
DMS中spark sql支持maxcompute吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是的,DMS中的Spark SQL是支持MaxCompute的。Spark SQL是Apache Spark的一个模块,它提供了一种用于处理结构化数据的编程接口。通过Spark SQL,您可以使用SQL语句或Spark的DataFrame API来查询和分析数据。
在DMS中,您可以使用Spark SQL来连接和操作MaxCompute数据。您可以通过配置Spark连接器来连接到MaxCompute,并使用Spark SQL语句来查询和处理MaxCompute表中的数据。
要使用Spark SQL连接到MaxCompute,请按照以下步骤操作:
在DMS中创建一个Spark连接器,并配置连接参数,包括MaxCompute的Endpoint、AccessKey和AccessSecret等信息。
在Spark连接器中,选择MaxCompute作为数据源,并指定要连接的MaxCompute项目和表。
使用Spark SQL语句来查询和处理MaxCompute表中的数据。您可以在DMS中编写和执行Spark SQL语句,查看查询结果并进行数据分析。
MaxCompute是阿里云提供的云原生的数据计算和分析服务,是一个云原生的数据计算和分析服务,它提供了托管的大规模数据存储和计算能力.
MaxCompute是阿里云提供的大数据计算引擎。阿里云提供了MaxCompute Spark Connector,这是一个用于将Spark与MaxCompute集成的库。通过使用MaxCompute Spark Connector,你可以在Spark中读取和写入MaxCompute表,并使用Spark SQL执行MaxCompute表的查询。
DMS Spark SQL支持MaxCompute。您可以在DMS中创建Spark SQL任务,然后选择MaxCompute作为数据源。
DMS是阿里云的数据管理服务,支持MaxCompute。Spark SQL是Apache Spark的SQL查询语言,可以在MaxCompute上执行。
是的,DMS中的Spark SQL支持MaxCompute,可以通过连接MaxCompute数据源进行数据分析和处理。需要在DMS中添加MaxCompute数据源,并正确配置相关参数,如accessKeyId、accessKeySecret、project等。然后就可以使用Spark SQL语句对MaxCompute数据进行查询、过滤、聚合等操作。

在创建服务页面中,等待服务创建完成。
在服务创建完成后,选择“管理”。
在管理页面中,选择“数据源”。
在数据源页面中,选择“创建数据源”。
是的,DMS中Spark SQL支持MaxCompute。MaxCompute是阿里云提供的一种分布式计算服务,可以提供大规模数据处理能力。在DMS中,您可以使用Spark SQL来连接MaxCompute,并进行数据处理和分析。
在DMS中,您可以使用以下步骤来连接MaxCompute:
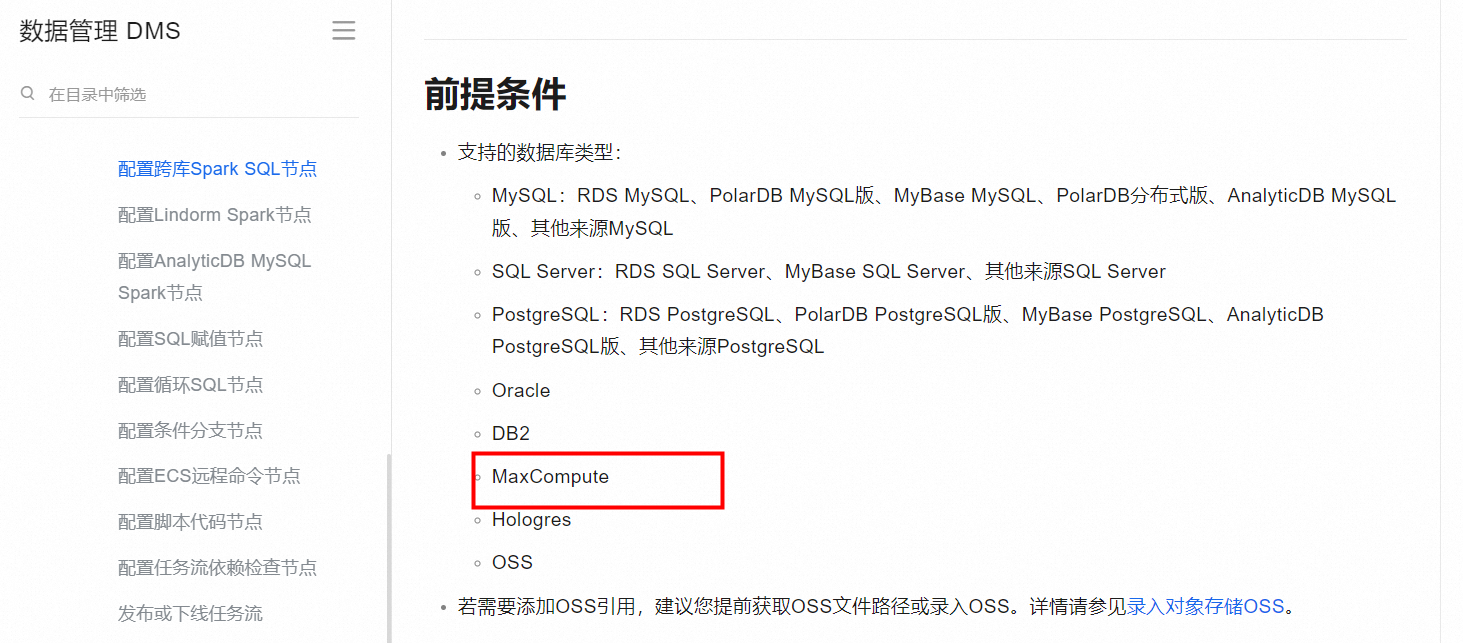

在阿里云 DMS(Data Management Service)中,Spark SQL 可以与 MaxCompute 进行集成和使用。Spark SQL 是 Apache Spark 提供的用于处理结构化数据的模块,而 MaxCompute 是阿里云提供的一种大数据计算平台。
通过 DMS 中的 Spark SQL 功能,你可以使用 Spark SQL 语法来查询和操作 MaxCompute 中存储的数据。具体步骤如下:
登录到阿里云 DMS 控制台:打开阿里云官方网站,在控制台中选择 DMS 服务,并使用你的阿里云账号登录。
创建连接:在 DMS 控制台中,选择对应数据库类型为 "MaxCompute",并创建新的数据库连接。输入必要的连接信息,如 AccessKey、AccessKeySecret、Endpoint 等。
打开 Spark SQL 终端:完成连接配置后,进入数据库管理界面,选择相应的 MaxCompute 数据库实例,并点击 "Spark SQL" 进入 Spark SQL 终端。
使用 Spark SQL 查询:在 Spark SQL 终端中,可以直接编写 Spark SQL 语句来查询和操作 MaxCompute 中的数据。例如,你可以执行类似以下的语句:
SELECT * FROM your_table;
该语句将从 MaxCompute 数据表中选取所有数据。
Spark SQL语法:基于Spark 3.1.2版本部署,提供该版本所有语法特性和原生函数。原生函数包括聚合函数、窗口函数、数组函数、Map函数、日期和时间处理函数、JSON处理函数等。更多信息,请参见Spark SQL官方文档。https://spark.apache.org/docs/3.1.2/sql-programming-guide.html
支持与阿里云 MaxCompute(原名为 ODPS)的集成。
MaxCompute 是阿里云提供的一种大数据计算和分析服务,可用于处理大规模的结构化和非结构化数据。而 DMS 中的 Spark SQL 是基于 Apache Spark 构建的 SQL 查询引擎,可以方便地进行数据分析和查询。
通过 DMS 中的 Spark SQL,你可以连接到 MaxCompute,并执行 SQL 查询和分析操作。你可以编写 Spark SQL 查询语句,通过 DMS 提供的可视化界面或命令行方式执行这些语句,并处理 MaxCompute 中的数据。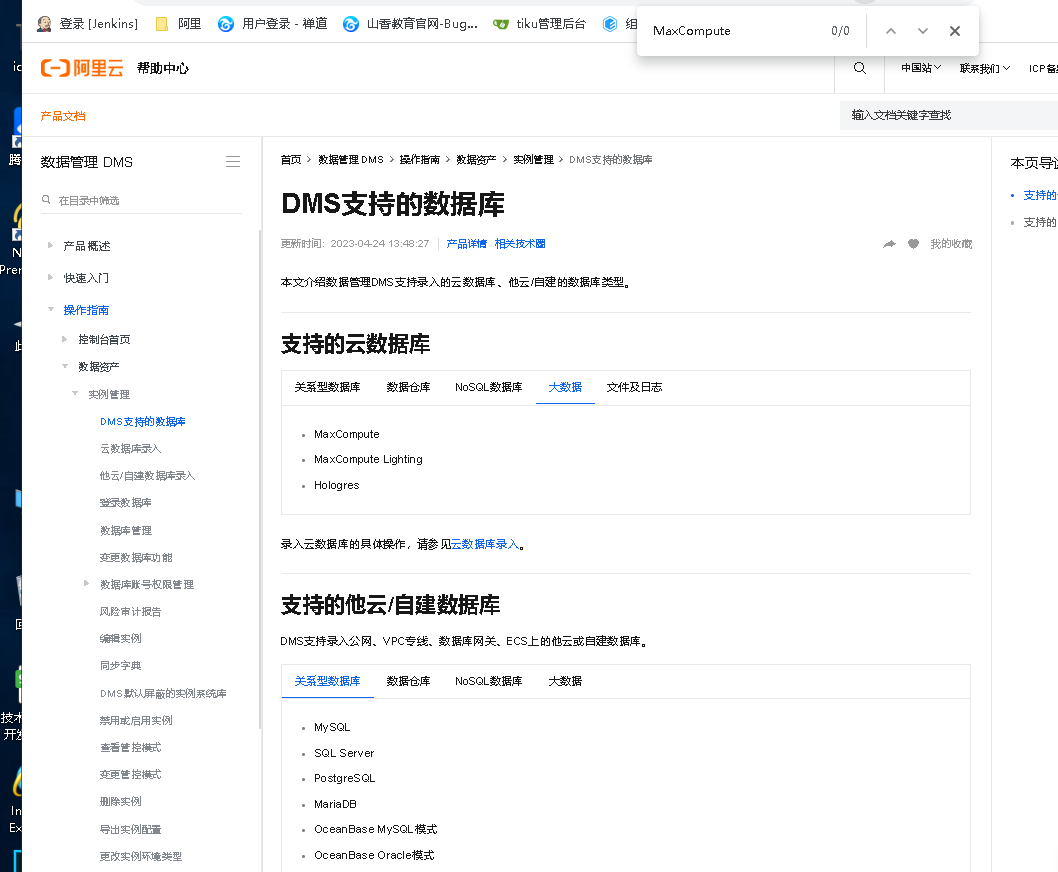
在DMS(Data Management Service)中,Spark SQL 默认情况下并不直接支持 MaxCompute。Spark SQL 是基于 Apache Spark 构建的用于处理结构化数据的查询引擎,而 MaxCompute 是阿里云提供的云上大数据计算服务。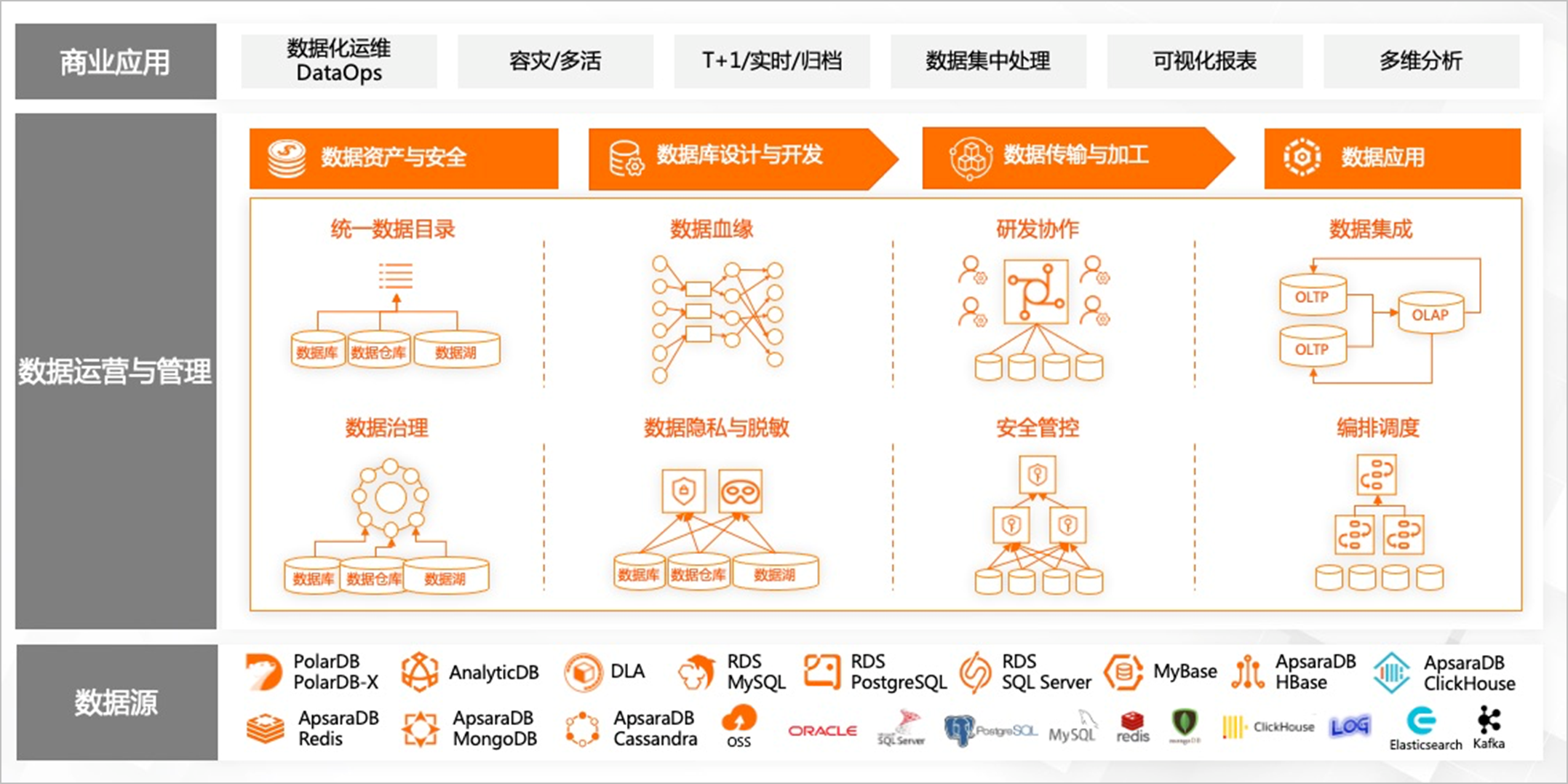
然而,如果你希望在 Spark 中使用 MaxCompute 数据,有几种方法可以实现:
使用开源项目:有一些开源项目(如阿里云自研的 Odps-spark 或者 DataFramesOnOdps)可以作为桥接器,允许在 Spark 中使用 MaxCompute 数据。这些项目提供了对 MaxCompute 的连接和查询功能。你可以通过搜索这些项目并按照它们的文档来了解如何将 MaxCompute 与 Spark 进行集成。
自定义开发:你可以借助 Spark 提供的接口以及 MaxCompute 的 SDK,编写自己的代码来实现 MaxCompute 在 Spark 中的连接和查询。这可能需要针对 MaxCompute 的底层 API 进行开发,并将其集成到 Spark 程序中。
无论哪种方法,都需要进行额外的配置和代码开发,以确保 Spark 能够与 MaxCompute 连接并执行查询。同时,请注意 Spark 和 MaxCompute 的版本兼容性要求,并查阅相关文档和资源,了解更多关于集成这两个系统的最佳实践和适用方法。
DMS(Data Management Service)是阿里云提供的一种数据管理服务,可以帮助用户进行数据的导入、导出、转换和分析等操作。而Spark SQL是Apache Spark中的一个模块,用于处理结构化数据,支持使用SQL查询和操作数据。
DMS中的Spark SQL支持连接MaxCompute,可以通过DMS的数据集成功能,将MaxCompute中的数据导入到Spark SQL中进行分析和处理。具体步骤如下:
在DMS中创建一个数据集成任务,选择MaxCompute作为源数据。
配置MaxCompute的连接信息,包括AccessKey、AccessSecret、Endpoint等。
选择要导入的MaxCompute表或视图,配置导入的数据字段、数据筛选条件等。
完成数据集成任务的配置后,DMS会自动创建一个Spark SQL的数据源,可以在Spark SQL中使用该数据源进行数据查询和分析。
使用Spark SQL进行MaxCompute数据分析时,可以通过Spark SQL的API或者直接使用SQL语句进行操作。例如下图操作:

是的,DMS(阿里云分布式消息队列)支持 Spark SQL 连接到阿里云的 MaxCompute 数据处理平台。通过使用 DMS,您可以在 Spark SQL 中执行数据操作、查询和分析等任务。要使用 Spark SQL 连接到 MaxCompute,您需要确保已正确配置连接信息,包括 MaxCompute 的实例地址、端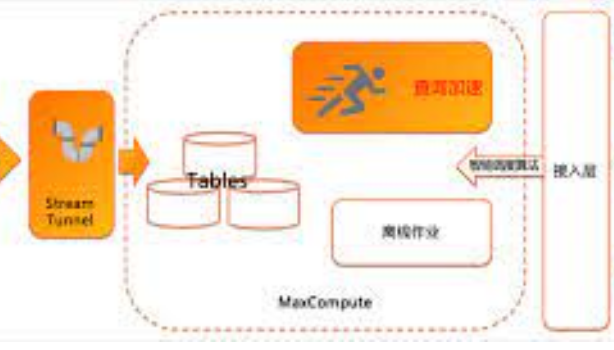
口、用户名和密码等。同时,您还需要在 Spark SQL 中启用连接池功能,以便更高效地管理和重用连接。在执行查询时,可以使用 "jdbc:maxcompute://:/" 这样的连接字符串。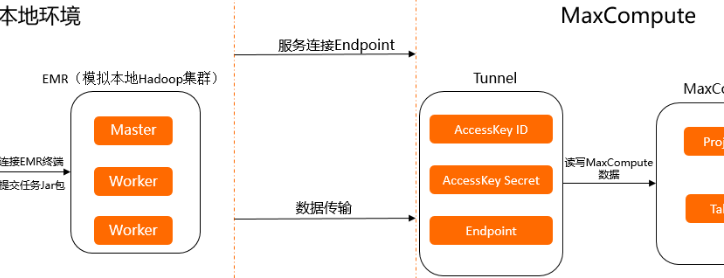
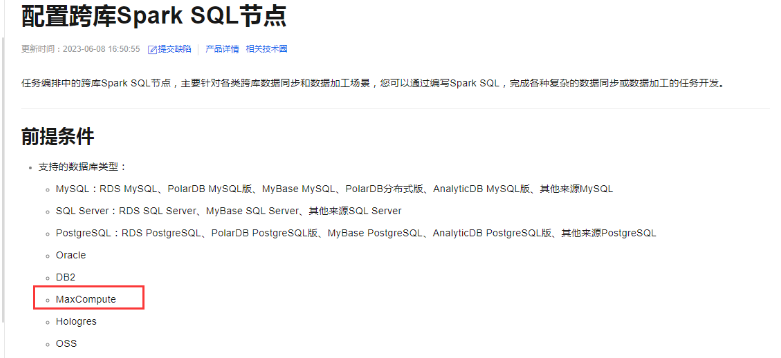
对各类跨库数据同步和数据加工场景,通过编写Spark SQL,完成各种复杂的数据同步或数据加工的任务开发。Spark SQL支持maxcompute。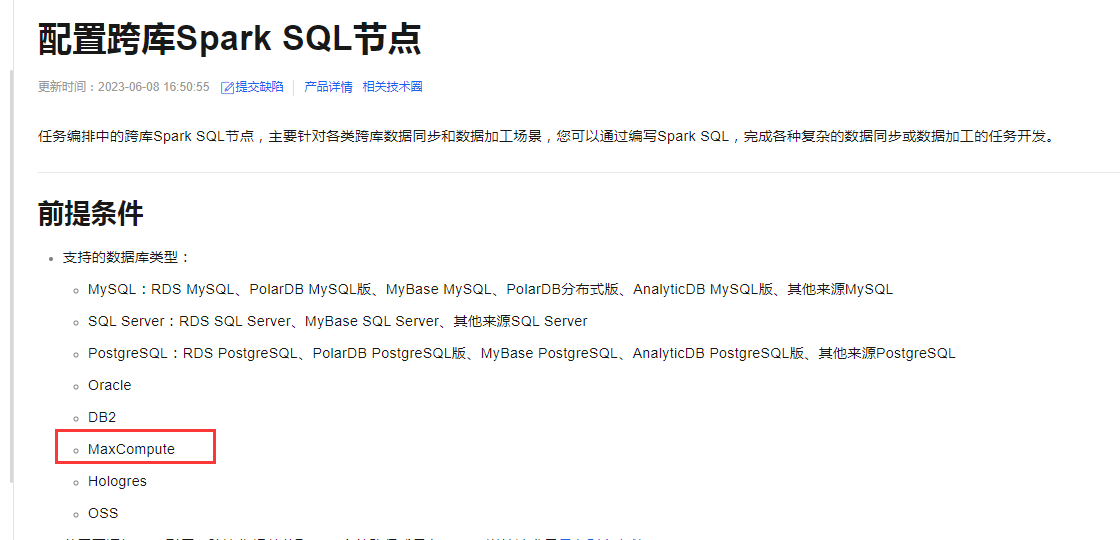
在DMS中,Spark SQL可以与MaxCompute进行集成和交互。Spark SQL是Spark的一个模块,用于处理结构化数据,而MaxCompute是阿里云提供的大数据计算服务。
通过Spark SQL的MaxCompute数据源,你可以使用Spark SQL来读取、写入和处理MaxCompute中的数据。Spark SQL提供了与MaxCompute的连接器,可以通过配置连接参数来连接到MaxCompute,并执行SQL查询、数据转换和分析等操作。
以下是使用Spark SQL与MaxCompute集成的示例代码:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("Spark SQL with MaxCompute")
.config("spark.hadoop.odps.access.id", "your-access-id")
.config("spark.hadoop.odps.access.key", "your-access-key")
.config("spark.hadoop.odps.project.name", "your-project-name")
.config("spark.hadoop.odps.end.point", "your-end-point")
.getOrCreate()
val df = spark.read.format("org.apache.spark.sql.execution.datasources.odps.OdpsRelationProvider")
.option("odps.sql", "SELECT * FROM your-table")
.load()
df.show()
在上述代码中,我们使用SparkSession来创建一个Spark应用程序,并配置了与MaxCompute的连接参数。然后,我们使用org.apache.spark.sql.execution.datasources.odps.OdpsRelationProvider作为数据源,通过执行SQL查询来读取MaxCompute中的数据,并将结果显示出来。
需要注意的是,你需要替换示例代码中的连接参数(如access id、access key、project name、end point和table name)为你自己的MaxCompute相关信息。
总结来说,Spark SQL可以与MaxCompute进行集成,通过配置连接参数和使用MaxCompute数据源,你可以在Spark中使用Spark SQL来读取、写入和处理MaxCompute中的数据。
DMS中的Spark SQL支持MaxCompute。MaxCompute是阿里云推出的一款云端大数据计算平台,支持SQL、MapReduce、Spark等多种计算方式。DMS中的Spark SQL可以直接连接MaxCompute,支持MaxCompute中的表查询、数据写入等操作。
如果您想在DMS中使用Spark SQL连接MaxCompute,可以按照以下步骤进行操作:
在DMS中创建MaxCompute连接。在DMS的“数据库管理”页面中,可以创建MaxCompute连接,并输入MaxCompute的账号信息和连接信息。
在DMS中创建Spark SQL任务。在DMS的“任务管理”页面中,可以创建Spark SQL任务,并选择MaxCompute连接作为数据源。
在Spark SQL任务中编写SQL语句。在Spark SQL任务中,可以编写SQL语句,查询MaxCompute中的数据。
运行Spark SQL任务。在DMS的“任务管理”页面中,可以运行Spark SQL任务,执行SQL语句并获取查询结果。
是的,DMS中的Spark SQL支持MaxCompute。您可以在DMS中创建MaxCompute的数据源,并使用Spark SQL来查询和分析MaxCompute中的数据。此外,您还可以使用DMS中的其他功能,例如数据同步、数据开发等,来更好地管理和使用MaxCompute中的数据。
支持的,阿里云的DMS(Data Management Service)中的Spark SQL功能支持MaxCompute。MaxCompute是一个大规模数据处理平台,可以用于数据清洗、转换、分析等任务。在Spark SQL中,您可以使用JDBC/ODBC连接MaxCompute,并进行各种数据处理操作。
操作步骤
以录入阿里云RDS MySQL数据库举例。
登录数据管理DMS 5.0。
在顶部菜单栏中,选择数据资产 > 实例管理。
单击实例列表页签,单击新增。
在新增实例页面,录入实例信息
完成以上信息填写后,单击左下角的测试连接。
说明
如果测试连接失败,请按照报错提示检查您录入的实例信息。
出现连接成功提示后,单击提交。
至此云数据库已经成功录入至DMS,您可以在DMS控制台左侧的实例列表中,查看并管理您的数据库。


