
我现在flink服务启动之后,占用的cpu有点多,20%-30%。服务器是64核的。这样正常吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
不正常,这个应该是你的参数配置不是很得当导致的,需要进行调参
从1.5版本开始TaskManager数量由程序的并行度自动推算
在Flink中你可以设置要使用的最大内存和任务槽的数量(它只是划分内存)。 taskmanager.numberOfTaskSlots:单个TaskManager可以运行的并行操作符或用户函数实例的数量(默认值:1)。如果此值大于1,则单个TaskManager将获取函数或运算符的多个实例。这样,TaskManager可以使用多个CPU内核,但同时,可用内存在不同的操作员或功能实例之间划分 。该值通常与TaskManager的机器具有的物理CPU核心数成比例(例如,等于核的数量,或核的数量的一半)。 同时Flink大并发任务(超过500并发)在使用keyBy或者rebalance的情况下,将 bufferTimeout设置为1s可以节省30~50%的CPU消耗。
cpu是计算机和服务器中最为重要的部件,要是cpu占用率过高的话,就很容易出现死机的情况。 服务器cpu占用率多少算正常,这个没有绝对的说法,规定CPU使用多少算正常。 通常情况下,如果cpu占用率在0%--75%之间变化,这个是正常的。但是要是经常在90%以上,甚至99.9%或者100%,那就算不正常。服务器cpu占用率过高,会导致死机等问题。 你这个是正常的。
由于使用的是基于堆的状态后端( FSStateBackend将其工作状态保留在JVM堆上),并且状态TTL被配置为1(或3)天,因此可以预期状态大小将会增长。它将增长多少是特定于应用程序的;它取决于密钥空间如何随着时间的推移而增长。 检查点变慢的原因有很多,但通常这表明在到达远程文件系统时存在反压力或某种类型的资源争用--即S3速率限制。如果您在Flink WebUI中查看检查点统计信息,您可以在那里查找线索。查看检查点是否会占用很长时间来遍历执行图,或者检查点的异步部分是否需要很长时间才能将检查点写入远程磁盘。寻找不对称性--一个实例是否比其他实例花费的时间更长在用户函数中执行任何阻塞i/o操作,这可能会带来麻烦。或者你可能有严重的数据偏差(例如,热键)。或者任务管理器和分布式文件系统之间的慢速网络。或者集群可能配置不足--您可能需要增加并行度。 可能需要增加检查点超时。如果在某个时候检查点持续时间真的变得有问题,您可以切换到使用RocksDB状态后端,以便能够使用增量检查点(但这是否会有所帮助取决于正在发生的事情)。或者,可以更快地将状态TTL配置更改为清除状态。 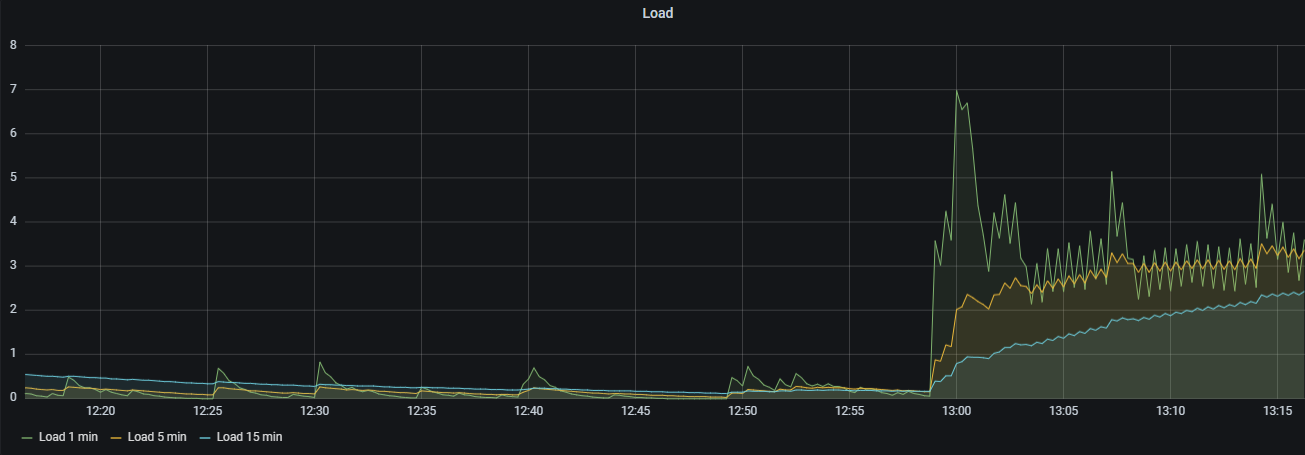
这个是正常的,对于异常的标准可用通过cpu的波动来判断,如果cpu的使用量一直都是70%以上肯定是不正常的。flink的启动之后会有很大的进程在处理对应的消息,所以cpu的使用量会比较高。一般不超过50%不用担心
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



