目录
《2020 state of enterprise machine learning》翻译与解读
Key finding 1: The rise of the data science arsenal for machine learning用于机器学习的数据科学武器库的兴起
Data scientists employed, a year-on-year comparison
New roles, the same data science
Key finding 2: Cutting costs takes center stage as companies grow随着公司的成长,削减成本成为焦点
Machine learning use case frequency
Smaller companies focus on customers
Breakdown of use cases by industry
Key finding 3: Overcrowding at early maturity levels and AI for AI’s sake早熟阶段的过度拥挤和人工智能
2020 machine learning maturity levels
55% of companies surveyed have not deployed a machine learning model
9% more companies have gotten models into production since 2018
Year and company size comparison
Machine learning maturity and company size
Gauging maturity in the year ahead
Anticipated maturity stage in the next 12 months
Key finding 4: An unreasonably long road to deployment不合理的漫长部署之路
Model deployment timeline and company size
Model deployment timeline and ML maturity
Data science workload and the last mile to deployment
Time data scientists spend deploying models by company size
Key finding 5: Innovation hubs and the trouble with scale创新中心和规模问题
Model reproducibility impedes ML maturity
Year comparison of machine learning challenges
Organizational misalignment and ML progress
Key finding 6: Budget and machine learning maturity, priorities and industry预算和机器学习成熟度、优先级和行业
FY19 AI/ML budgets and ML maturity level
AI/ML budgets for banking and financial services
AI/ML budgets for manufacturing
AI/ML budgets for information technology
Key finding 7: Determining machine learning success across the org chart在整个组织结构图中确定机器学习的成功
The future of machine learning
相关文章
AI:Algorithmia《2020 state of enterprise machine learning—2020年企业机器学习状况》翻译与解读
AI:Algorithmia《2021 enterprise trends in machine learning 2021年机器学习的企业趋势》翻译与解读
《2020 state of enterprise machine learning》翻译与解读
文章链接:2020 State of ML - Algorithmia
Introduction
In the last 12 months, there have been myriad developments in machine learning (ML) tools and applications, and hardware for AI and ML is also progressing. Google’s TPUs are in their third generation, the AWS Inferentia chip is a year old, Intel’s Nervana Neural Network Processors are enabling deep learning, and Microsoft is reportedly developing its own customAIhardware. This year, Algorithmia has had conversations with thousands of companies in various stages of machine learning maturity. From them we developed hypotheses about the state of machine learning in the enterprise, and in October, we decided to test those hypotheses. Building on the State of Enterprise Machine Learning report we published in 2018, we conducted a new two-prong survey this year, polling nearly 750 business decision makers across all industries from companies actively developing machine learning lifecycles or just beginning their machine learning journey. |
在过去的 12 个月里,机器学习 (ML) 工具和应用程序有了无数的发展,人工智能和机器学习的硬件也在进步。 谷歌的 TPU 已进入第三代,AWS 推理芯片已有一年的历史,英特尔的 Nervana 神经网络处理器正在支持深度学习,据报道微软正在开发自己的定制人工智能硬件。 今年,Algorithmia 与数千家处于机器学习成熟度不同阶段的公司进行了对话。 我们从他们那里提出了关于企业机器学习状态的假设,并在 10 月决定检验这些假设。 基于我们在 2018 年发布的企业机器学习状况报告,我们今年进行了一项新的双管齐下的调查,对来自各行各业的近 750 名业务决策者进行了民意调查,这些决策者包括来自积极开发机器学习生命周期或刚刚开始机器学习之旅的公司。 |
One set of respondents was administered a blind version of our survey by a third-party (we refer to this group in the report as Group A); the other set was sent a survey by Algorithmia and was aware of the author (referred to herein as Group B). Group A contained 303 respondents and Group B contained 442. We analyzed the responses from both groups for insight into their work, their companies’ machine learning roadmaps, and the changes they’ve seen in recent months with regard to ML development. Where applicable, we state when only one group is being cited in a given statistic. The Methodology section provides further detail on the specifics of the survey prongs and how we processed the data. The following are the findings of that effort, presented with our original hypotheses, as well as our analysis of the results. Where possible, we have provided a year-on-year comparison with data from 2018 and included predictions about what is likely to manifest in the ML space in the near term. We will soon make our survey data available on an interactive webpage to foster greater understanding of the ML landscape, and we are committed to being good stewards of this technology. Algorithmia seeks to empower every organization to achieve its full potential through the use of artificial intelligence and machine learning by delivering the last-mile solution for model deployment at scale. |
其中一组受访者由第三方管理我们的盲版调查(我们在报告中将此组称为A组);另一组由Algorithmia发送一份调查问卷,并且知道作者(这里称为B组)。A组受访者为303人,B组受访者为442人。 我们分析了这两组人的反馈,以深入了解他们的工作、他们公司的机器学习路线图,以及他们在最近几个月在机器学习开发方面所看到的变化。在适用的情况下,当一个给定的统计数据中只有一个组被引用时,我们会说明。方法论部分提供了关于调查重点的细节以及我们如何处理数据的进一步详细信息。 以下是这项工作的发现,以及我们最初的假设,以及我们对结果的分析。在可能的情况下,我们提供了与2018年数据的同比比较,并对ML空间近期可能出现的情况进行了预测。我们将很快在一个交互式网页上提供我们的调查数据,以促进对ML环境的更好理解,我们致力于成为这项技术的优秀管理者。 Algorithmia旨在通过使用人工智能和机器学习,为模型大规模部署提供最后一英里的解决方案,使每个组织都能充分发挥其潜力。 |
Survey at a glance概览
The main takeaway from the 2020 State of Enterprise Machine Learning survey is that a growing number of companies are entering the early stages of ML development, but challenges in deployment, scaling,versioning, and other sophistication efforts still hinder teams from extracting value from their ML investments. As a result, we will likely see a boom in the number of ML companies providing services to overcome these obstacles in the near term. In this report, we focus on seven key survey findings and what they say about the machine learning landscape. Those key findings are as follows: (1)、The number of data scientist roles at companies is often less than 10, but is growing rapidly across all industries. (2)、Business use cases for machine learning are becoming more varied but currently, customer-centric applications are the most common. (3)、Machine learning operationalization (having a deployed ML lifecycle) is fledgling but maturing across all industries with software and IT firms leading the charge. (4)、The main challenges people face when developing ML capabilities are scale, version control, model reproducibility, and aligning stakeholders. (5)、The time it takes to deploy a model is stuck somewhere between 31 and 90 days for most companies. (6)、Budgets for ML programs are growing most often by 25 percent, and the banking, manufacturing, and IT industries have seen the largest budget growth this year. (7)、Organizations are determining ML success by both business unit and statistical metrics with a significant divide by job level. |
2020 年企业机器学习现状调查的主要内容是,越来越多的公司正进入 ML 开发的早期阶段,但部署、扩展、版本控制和其他复杂工作方面的挑战,仍然阻碍团队从其 ML 投资中获取价值。 因此,我们可能会看到为克服这些障碍而提供服务的ML公司数量激增。 在本报告中,我们将重点关注七个关键的调查结果,以及它们对机器学习前景的看法。这些主要发现如下: (1)、公司的数据科学家职位数量通常少于 10 个,但在所有行业中都在迅速增长。 (2)、机器学习的业务用例越来越多样化,但目前以客户为中心的应用最为普遍。 (3)、机器学习操作化(具有已部署的 ML 生命周期)在所有行业都处于起步阶段,但在软件和IT公司主导的所有行业中都日趋成熟。 (4)、人们在开发 ML 能力时面临的主要挑战是规模、版本控制、模型可再现性和协调利益相关者。 (5)、对于大多数公司来说,部署模型所需的时间大约在31到90天之间。 (6)、机器学习项目的预算增长幅度最大,达到 25%,其中银行、制造和 IT 行业的预算增长幅度今年最大。 (7)、组织正在通过业务部门和统计指标来确定 ML 的成功,并根据工作级别进行显著划分。 |
The report will go into each finding in detail and provide analysis and our outlook. |
报告将详细研究每一项发现,并提供分析和展望。 |
Key finding 1: The rise of the data science arsenal for machine learning用于机器学习的数据科学武器库的兴起
One of the pieces of data we collected this year was the number of data scientists employed at the respondent’s place of work. In conversations we regularly have with companies, we repeatedly hear that management is prioritizing hiring for the data science role above many others, including engineering, IT, and software. Here is what the survey results showed. Half of people polled (across both survey groups) said their companies employ between one and 10 data scientists. This is actually down from 2018 wherein 58 percent of companies claimed to employ between one and 10 data scientists. We would have expected the number to increase over time because investment in AI and ML is known to be growing (Gartner). When assessed in the context of the full data, however, a likely reason for the downward trend presents itself. In 2018, 18 percent of companies employed 11 or more data scientists. This year, however, that number soared to 39 percent, suggesting that across all industries, organizations are ramping up their hiring efforts to build larger data science arsenals, with some of them starting from close to 10 data scientists already. Another observation is that in 2018, barely 2 percent of companies had more than 1,000 data scientists; today that number is just over 3 percent, indicating small but significant growth. These companies include the big FAANG tech giants—Facebook, Apple, Amazon, Netflix, and Google (Yahoo); their large data science teams are working to maintain competitiveness as more third-party solutions crop up. |
我们今年收集的数据之一是被调查者工作地点雇佣的数据科学家的数量。在我们经常与公司的交谈中,我们反复听到管理层将数据科学职位的招聘优先于其他许多职位,而不是其他许多人,包括工程、IT和软件。以下是调查结果。 在接受调查的两组人中,有一半人表示,他们的公司雇佣1至10名数据科学家。这实际上比2018年有所下降,当时有58%的公司声称雇佣了1至10名数据科学家。 由于对人工智能和ML的投资正在增加,预计这一数字还会增加(Gartner)。然而,在全面数据的背景下进行评估,就会发现下降趋势的一个可能原因。2018年,18%的公司雇佣了11名或以上的数据科学家。然而,今年这一数字飙升至39%,这表明,在所有行业,企业都在加大招聘力度,以建立更大的数据科学武库,其中一些企业已经从近10名数据科学家开始招聘。 另一个观察结果是,2018年,只有2%的公司拥有超过1000名数据科学家;如今,这个数字仅略高于3%,这表明增长虽小但意义重大。这些公司包括FAANG科技巨头——Facebook、苹果(Apple)、亚马逊(Amazon)、Netflix和谷歌(Yahoo);随着越来越多的第三方解决方案涌现,它们的大型数据科学团队正在努力保持竞争力。 |
Data scientists employed, a year-on-year comparison
受雇的数据科学家,逐年比较
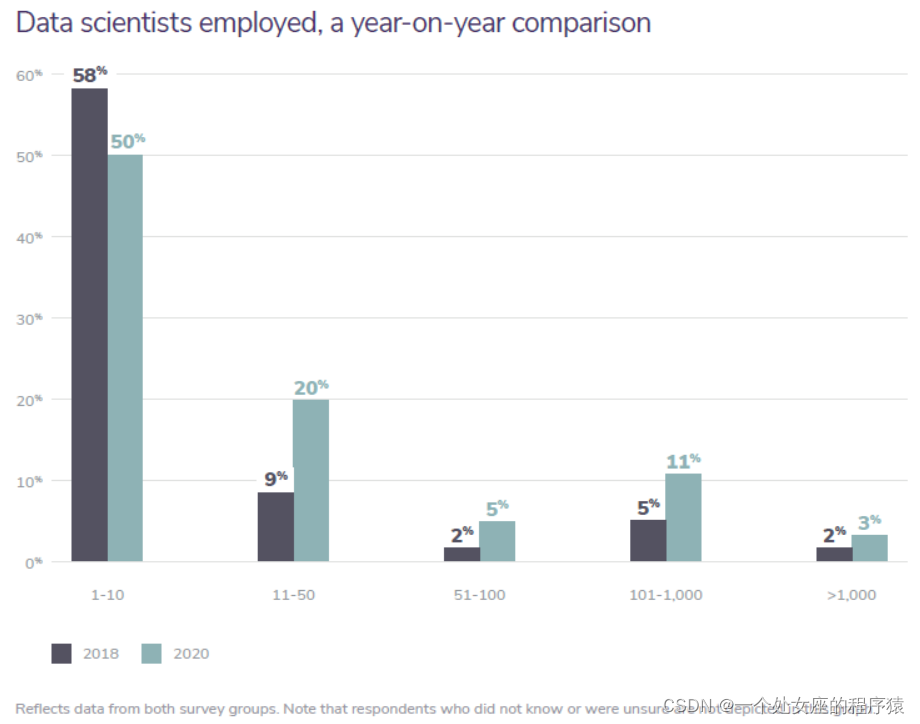
Reflects data from both survey groups. Note that respondents who did not know or were unsure are not depicted in this graph. |
反映了两个调查群体的数据。请注意,不知道或不确定的受访者没有在这张图表中描述。 |
Demand for data scientists
对数据科学家的需求
In 2016, Deloitte predicted a shortage of 180,000 data scientists by 2018, and between 2012 and 2017, the number of data scientist jobs on LinkedIn increased by more than 650 percent (KDnuggets). The talent deficit and high demand means that hiring and maintaining data science roles will only become more difficult for small and mid-sized companies that cannot offer the same salary and benefits packages as the FAANG companies. As demand for data scientists grows, we may see a trend of junior-level hires having less opportunity to structure data science and machine learning efforts within their teams, as much of the structuring and program scoping may have already been done by predecessors who overcame the initial hurdles. It could also mean, however, that leadership alignment has already been attained so ML teams will have more ownership and leeway in project execution. |
2016 年,德勤预测到 2018 年将短缺 180,000 名数据科学家,而在 2012 年至 2017 年期间,LinkedIn 上的数据科学家职位数量增加了 650% 以上(KDnuggets)。 人才短缺和高需求意味着,对于无法提供与 FAANG 公司相同的薪资和福利待遇的中小型公司而言,招聘和维护数据科学职位只会变得更加困难。 随着对数据科学家的需求增长,我们可能会看到初级员工在其团队中构建数据科学和机器学习工作的机会减少的趋势,因为许多结构化和程序范围划分可能已经由克服最初障碍的前辈完成。 然而,这也可能意味着领导层已经达成一致,因此 ML 团队将在项目执行中拥有更多的所有权和回旋余地。 |
New roles, the same data science
同样的数据科学新角色
Finally, we may also see the merging of traditional business intelligence and data science in order to fill immediate requirements in the latter talent pool since both domains use data modeling (BI work uses statistical methods to analyze past performance, and data science makes predictions about future events or performance). Gartner predicts that the overall lack of data science resources will result in an increasing number of developers becoming involved in creating and managing machine learning models (Gartner CIO survey). This blending of roles, will likely lead to another phenomenon related to this finding: more role names and job titles for the same sorts of work. To that end, we are seeing an influx of new job titles in data science such as Machine Learning Engineer, ML Developer, ML Architect, Data Engineer, Machine Learning Operations (ML Ops), and AI Ops as the industry expands and companies attempt to distinguish themselves and their talent from the pack. |
最后,我们可能还会看到传统商业智能和数据科学的融合,以满足后者人才库的即时需求,因为这两个领域都使用数据建模(BI工作使用统计方法分析过去的绩效,数据科学对未来事件或绩效进行预测)。 Gartner 预测,数据科学资源的整体缺乏将导致越来越多的开发人员参与创建和管理机器学习模型(Gartner CIO 调查)。 这种角色的混合,很可能会导致与这一发现相关的另一种现象:相同类型的工作有更多的角色名称和职务。 随着行业的扩张,公司试图将自己和他们的人才从群体中脱颖而出,数据科学领域的新职位如机器学习工程师、ML开发人员、ML架构师、数据工程师、机器学习运营(ML Ops)和AI Ops大量涌现。 |
Key finding 2: Cutting costs takes center stage as companies grow随着公司的成长,削减成本成为焦点
As a company, we are interested in machine learning applications in the enterprise and we strive to keep a pulse on how industries are using emerging ML tech to automate workflows. There are countless ways to apply ML to a particular business problem, such as using prediction modeling to make assessments about customer churn or applying natural language processing to millions of tweets to analyze the percentage of negative sentiments. In this year’s survey, we polled respondents about the ways their companies are using machine learning to ensure our understanding of the landscape is accurate or that we aren’t missing a key use case entering the enterprise. We anticipated a trend toward using ML to automate time-consuming processes and cut down on the number of human resources needed to do a given task. The results are depicted below. |
作为一家公司,我们对机器学习在企业中的应用感兴趣,并努力保持 行业如何利用新兴的ML技术实现工作流自动化。有无数种方法可以将ML应用于特定的业务问题,比如使用预测建模来评估客户流失,或者对数百万条tweet应用自然语言处理来分析负面情绪的百分比。 在今年的调查中,我们对受访者进行了调查,询问他们的公司如何使用机器学习来确保我们对环境的理解是准确的,或者我们是否遗漏了进入企业的关键用例。我们预计会有一种趋势,即使用ML自动化耗时的流程,并减少执行给定任务所需的人力资源数量。结果如下所示。 |
Machine learning use case frequency
机器学习用例频率
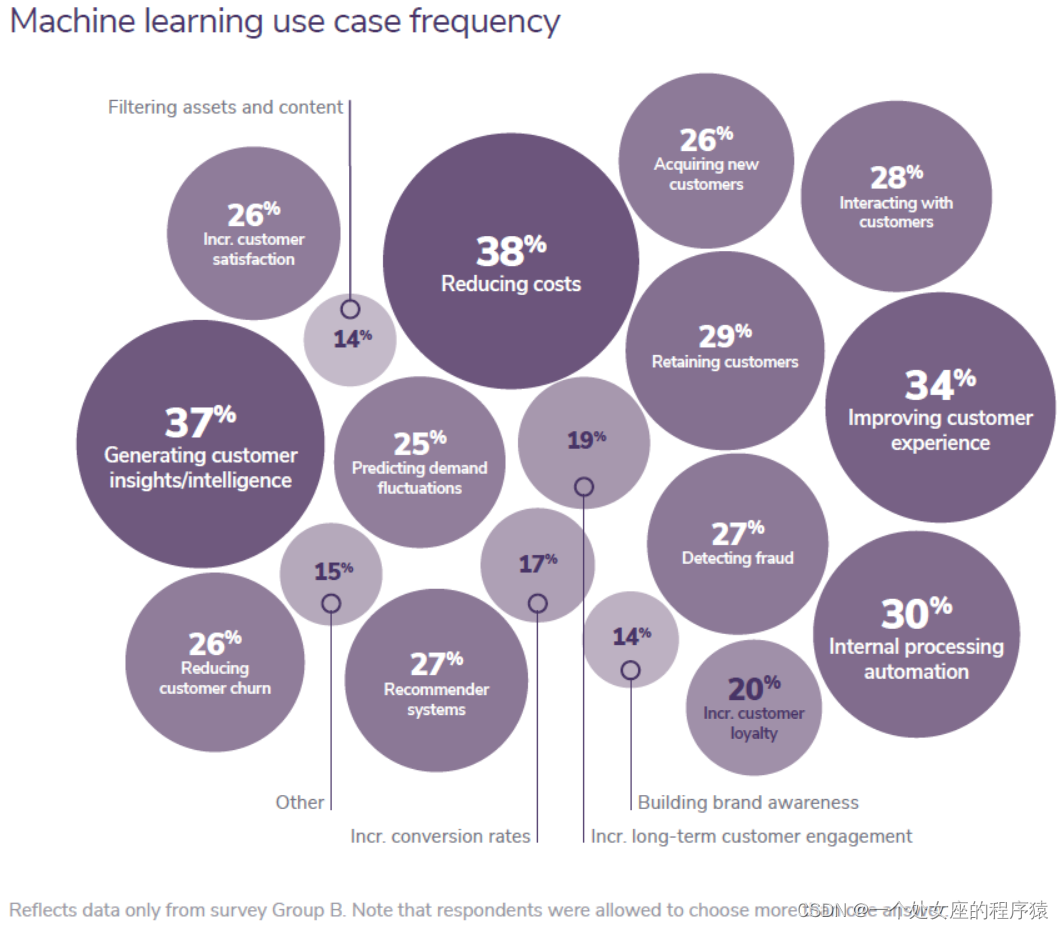
Reflects data only from survey Group B. Note that respondents were allowed to choose more than one answer. |
仅反映调查组B的数据。注意,受访者被允许选择一个以上的答案。 |
In this year’s survey, we provided a wide-ranging list of possible use cases and a write-in option. Respondents were encouraged to select all answers that applied to how their companies use AI and ML models today. The top three machine learning use cases across the board (for companies of all sizes) were as follows: (1)、Reducing company costs (2)、Generating customer insights and intelligence (3)、Improving customer experience |
在今年的调查中,我们提供了一个范围广泛的可能用例列表和一个写入选项。鼓励受访者选择适用于他们的公司今天如何使用 AI 和 ML 模型的所有答案。全面排名前三的机器学习用例(适用于各种规模的公司)如下: (1)、降低公司成本 (2)、生成客户洞察和情报 (3)、提升客户体验 |
When we break down the data by company size, we start to see some differentiation in priorities. The top five ML use cases for companies with 10,000 employees or more: (1)、Reducing company costs (2)、Process automation for internal organization (3)、Improving customer experience (4)、Generating customer insights and intelligence (5)、Detecting fraud |
当我们按公司规模细分数据时,我们开始看到优先级有所不同。拥有 10,000 名或更多员工的公司的前五个 ML 用例: (1)、降低公司成本 (2)、内部组织过程自动化 (3)、提升客户体验 (4)、生成客户洞察和情报 (5)、检测欺诈 |
The top five ML uses cases for companies with 1,001-5,000 employees: (1)、Reducing company costs (2)、Retaining customers (3)、Process automation for internal organization (4)、Recommender systems (5)、Increasing customer satisfaction |
拥有 1,001-5,000 名员工的公司的前五个 ML 用例: (1)、降低公司成本 (2)、留住客户 (3)、内部组织过程自动化 (4)、推荐系统 (5)、提高客户满意度 |
The top five ML use cases for companies with fewer than 100 employees: (1)、Generating customer insights and intelligence (2)、Improving customer experience (3)、Reducing company costs (4)、Increasing customer satisfaction (5)、Retaining customers |
员工人数少于 100 人的公司的前 5 个 ML 用例: (1)、生成客户洞察和情报 (2)、提升客户体验 (3)、降低公司成本 (4)、提高客户满意度 (5)、留住客户 |
Smaller companies focus on customers
小公司专注于客户
The survey data showed that large companies are using ML primarily for internal applications (reducing company spend and automating internal processes), and smaller companies are primarily focused on customer-centric functions (increasing customer satisfaction, improving customer experience, and gathering insights). This suggests that as companies grow, they prioritize customer service less than cost-saving measures and applications that improve their product lines. Doing so comes at a price, however, as one-third of Americans consider switching companies after just one instance of poor customer service (Qualtrics). Conversely, an increase in customer retention rate of just 5 percent can produce more than a 25-percent increase in profits (Bain&Company). |
调查数据显示,大公司主要将 ML 用于内部应用程序(减少公司支出和自动化内部流程),而小公司主要关注以客户为中心的功能(提高客户满意度、改善客户体验和收集见解)。这表明,随着公司的发展,他们优先考虑客户服务,而不是节省成本的措施和改善其产品线的应用程序。然而,这样做是有代价的,因为三分之一的美国人在一次糟糕的客户服务(Qualtrics)之后考虑更换公司。相反,客户保留率仅增加 5% 就能产生超过 25% 的利润增长(Bain&Company)。 |
Fortunately, machine learning is a solution for both types of business problems—cutting costs and customer satisfaction—and will likely shift business priorities in the near term as workflows are drastically augmented by new tech. For comparison, in our 2018 survey, 48 percent of respondents from companies with 10,000 or more employees said cost savings was a major ML priority, and 59 percent said increasing customer loyalty was the top ML use case, depicting a notable shift away from customers this year. It will be important to monitor this metric in future years to see if this is the beginning of a trend or an anomaly. Before conducting this year’s survey, we anticipated a more even spread of use cases across companies of all sizes independent of industry because of the number of companies and applications in development in the AI/ML space (Forbes). The percentages for cost reduction, roboticprocessautomation, and customer service applications may be an indicator of ML’s general newness and immaturity, which our next key finding discusses, or it may be demonstrative of the fact that those types of repetitive applications lend themselves more readily to automation. As machine learning becomes more sophisticated with time, we are likely to see a wider pool of use cases designed for specific organizational initiatives. |
幸运的是,机器学习是解决这两种业务问题(削减成本和客户满意度)的解决方案,并且可能会在短期内改变业务重点,因为新技术极大地增强了工作流程。相比之下,在我们 2018 年的调查中,来自拥有 10,000 名或更多员工的公司的 48% 的受访者表示,节省成本是 ML 的主要优先事项,59% 的受访者表示,提高客户忠诚度是 ML 的首要用例,这这表明今年的ML用户明显减少。在未来几年监控这一指标以查看这是趋势的开始还是异常情况非常重要。 在进行今年的调查之前,由于 AI/ML 领域(福布斯)中正在开发的公司和应用程序的数量,我们预计使用案例在各种规模的公司中的分布会更加均匀,而与行业无关。成本降低、机器人流程自动化和客户服务应用程序的百分比可能是 ML 普遍新颖和不成熟的指标,我们的下一个关键发现将讨论这一点,或者它可能表明这些类型的重复应用程序更容易实现自动化这一事实.随着机器学习随着时间的推移变得越来越复杂,我们可能会看到为特定组织计划设计的更广泛的用例池。 |
Breakdown of use cases by industry
按行业划分的用例
Understandably, industries with customer-facing products or services (retail, manufacturing, healthcare, etc.) prioritize ML applications that improve customer service, and industries involved with security, compliance laws, and proprietary data (financial institutions, government agencies, insurers, etc.) focus more so on ML use cases that help solve those challenges. The following are a few noteworthy examples: |
可以理解,拥有面向客户的产品或服务(零售、制造、医疗保健等)的行业优先考虑改善客户服务的 ML 应用程序,以及涉及安全、合规法律和专有数据的行业(金融机构、政府机构、保险公司等) .) 更多地关注有助于解决这些挑战的机器学习用例。以下是一些值得注意的例子: |
Respondents in both survey groups who work in consulting and professional services industries said that reducing customer churn was their top ML priority. The education/edtech sector’s top ML use case was interacting with customers, which is reasonable considering that students and instructors are likely a primary customer set in those industries. For the healthcare, pharmaceutical, and biotech industries, increasing customer satisfaction was the leading use case, suggesting that customer dissatisfaction or churn may be a continual challenge in those fields. IT companies use ML primarily to acquire new customers, and software development organizations prioritize ML recommendersystems to guide users toward viewing new products or features to buy. Banks and financial services firms are focusing their ML efforts on retainingcustomers and detecting fraud—keeping customers happy and mitigating vulnerabilities to the company. Finally, the energy sector, including utility companies, are focusing on forecasting demand fluctuations using ML, likely to prevent power outages, reduce response times during disruptions of service, and plan for power consumption for coming years (NeuralDesigner). |
在咨询和专业服务行业工作的两个调查组中的受访者都表示,减少客户流失是他们在机器学习方面的首要任务。 教育/edtech 行业的顶级 ML 用例是与客户交互,考虑到学生和教师可能是这些行业的主要客户群,这是合理的。 对于医疗保健、制药和生物技术行业,提高客户满意度是主要用例,这表明客户不满意或流失可能是这些领域的持续挑战。 IT 公司主要使用 ML 来获取新客户,软件开发组织优先使用 ML 推荐系统来引导用户查看新产品或购买新功能。 银行和金融服务公司正在将他们的机器学习工作重点放在留住客户和检测欺诈上——让客户满意并减少公司的漏洞。 最后,包括公用事业公司在内的能源部门正专注于使用 ML 预测需求波动,可能防止停电,缩短服务中断期间的响应时间,并规划未来几年的用电量(NeuralDesigner)。 |
Key finding 3: Overcrowding at early maturity levels and AI for AI’s sake早熟阶段的过度拥挤和人工智能
Understanding how companies view their own machine learning maturity provides insight into future developments in the ML space. For this survey, we asked respondents to gauge where they think their companies are located currently on the machinelearningroadmap. That is to say, we sought to determine if they are just starting to consider machine learning applications for business problems or if they are operating a fully developed machine learning program, or somewhere in the middle of that spectrum, and whether their positioning has changed in the previous 12 months. In 2018’s survey report, nearly 40 percent of respondents said they were just beginning to develop ML plans (ie. evaluating use cases, starting to build models). Moreover, in 2018 fewer than 10 percent of respondents considered themselves at a sophisticated ML maturity level. |
了解公司如何看待自己的机器学习成熟度可以洞察机器学习领域的未来发展。在本次调查中,我们要求受访者评估他们认为他们的公司目前在机器学习路线图上的位置。也就是说,我们试图确定他们是否刚刚开始考虑将机器学习应用程序用于解决业务问题,或者他们是否正在运行一个完全开发的机器学习程序,或者处于该范围的中间,以及他们的定位是否在过去的12个月改变。 在 2018 年的调查报告中,近 40% 的受访者表示他们刚刚开始制定 ML 计划(即评估用例,开始构建模型)。此外,在 2018 年,不到 10% 的受访者认为自己处于复杂的 ML 成熟度水平。 |
This year, we asked respondents to select one of the following options to gauge ML maturity levels: Not actively considering ML as a business solution Evaluating ML use cases Just starting to develop/build models Developed models; working toward production Early stage adoption (models in production for 1-2 years) Mid-stage adoption (models in production for 2-4 years) Sophisticated (models in production for 5+ years) |
今年,我们要求受访者选择以下选项之一来衡量 ML 成熟度水平: 没有积极考虑将 ML 作为业务解决方案 评估机器学习用例 刚开始开发/构建模型 开发模型;致力于生产 早期采用(模型生产 1-2 年) 中期采用(模型生产 2-4 年) 复杂(模型生产 5 年以上) |
2020 machine learning maturity levels
2020机器学习成熟度水平
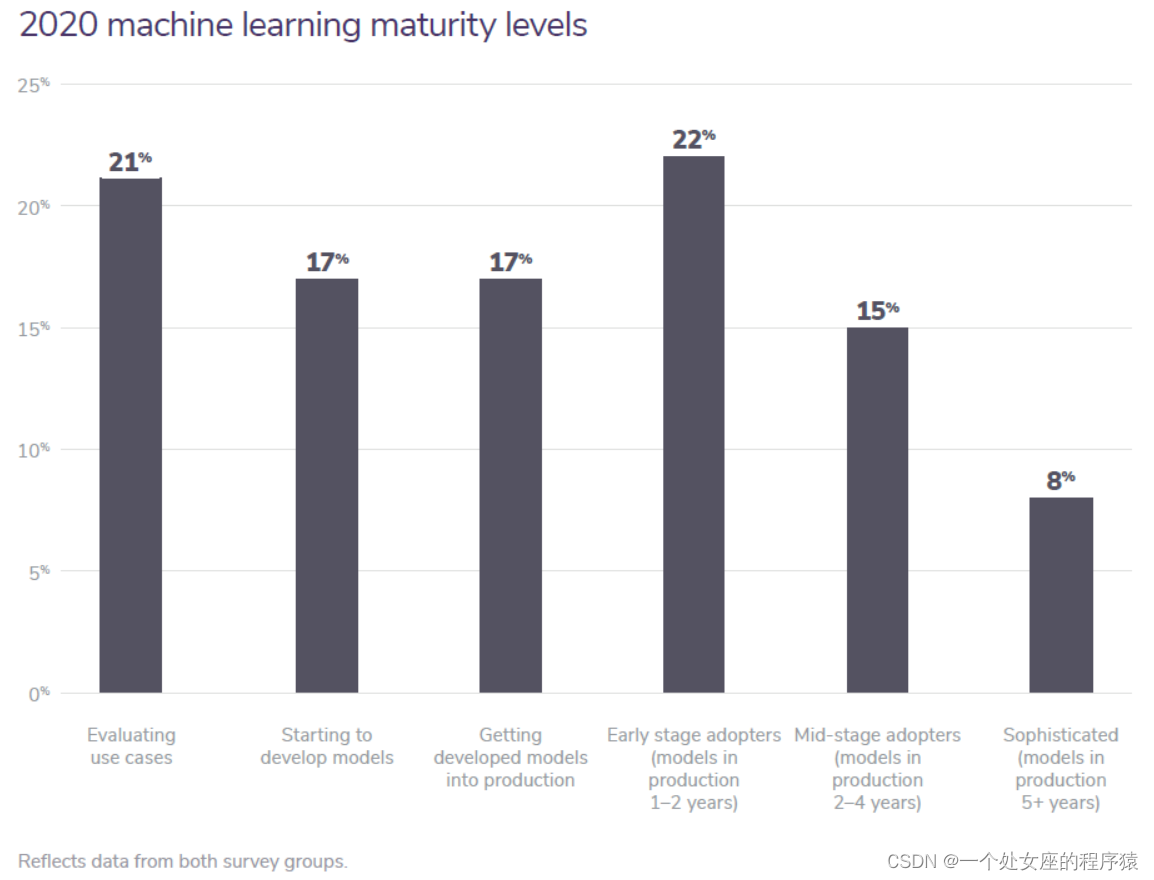
55% of companies surveyed have not deployed a machine learning model
55%的受访公司没有部署机器学习模型
Of the respondents who are actively engaging in ML (removing the first category of those who are not evaluating ML as a business solution), about one-fifth said they are evaluating use cases, based on an average of both survey groups. Those just starting to develop and build models numbered 17 percent, and a separate 17 percent of companies have developed models but are still working toward production. This means that 55 percent of companies surveyed have not deployed a machine learning model. |
根据两个调查组的平均值,在积极参与 ML 的受访者中(删除了不将 ML 作为业务解决方案评估的第一类),大约五分之一的人表示他们正在评估用例。 刚开始开发和建造模型的公司占 17%,另外 17% 的公司已经开发了模型,但仍在努力生产。 这意味着 55% 的受访公司尚未部署机器学习模型。 |
ML in early stages of development The number of companies with undeployed models is up 4 percent from last year, likely because there are more companies across the board beginning ML journeys, inflating the category of newcomers. It is important to note as well that our survey sample increased by more than 200 people from last year. |
处于早期开发阶段的机器学习 未部署模型的公司数量比去年增加了 4%,这可能是因为有更多公司全面开始 ML 之旅,从而扩大了新人的类别。 还需要注意的是,我们的调查样本比去年增加了 200 多人。 |
9% more companies have gotten models into production since 2018
自2018年以来,有9%以上的公司已将模型投入生产
Just over 22 percent of companies have had models in production for 1-2 years; last year, 13 percent of respondents claimed this, demonstrating a fairly significant migration toward productionization even if it is still early days for most companies Moreover, one-fifth of companies said they plan on getting models into production within the next year, suggesting that we may see a noticeable portion of companies moving into the next maturity category (mid-stage) in the near term. |
超过 22% 的公司已经生产了 1-2 年的模型;去年,有 13% 的受访者表示这一点,这表明即使对于大多数公司来说仍处于初期阶段,但向生产化的迁移也相当显着 此外,五分之一的公司表示他们计划在明年将模型投入生产,这表明我们可能会看到相当一部分公司在短期内进入下一个成熟类别(中期)。 |
Year and company size comparison
年份和公司规模比较
In 2018, only 6 percent of respondents considered their companies to have sophisticated ML programs. This year, 8 percent do, and the majority of companies in the sophisticated category either have fewer than 500 employees or more than 10,000. In 2018, 39 percent of sophisticated companies had fewer than 100 employees and 29 percent had more than 10,000 employees. There are several ways to read this maturity breakdown. First, large companies typically have more budget for innovation hubs and emerging technology, thus streamlining the development of sophisticated ML initiatives. Smaller companies, however, can be quite agile technologically, able to build, buy, and iterate quickly. |
2018 年,只有 6% 的受访者认为他们的公司拥有复杂的 ML 程序。今年,这一比例为 8%,大多数复杂类别的公司员工人数少于 500 人或超过 10,000 人。 2018 年,39% 的成熟公司员工人数少于 100 人,29% 的公司员工人数超过 10,000 人。 有几种方法可以阅读此成熟度细分。首先,首先,大公司通常有更多的预算用于创新中心和新兴技术,从而简化复杂ML计划的开发。然而,较小的公司在技术上可以非常灵活,能够快速构建、购买和迭代。 |
They can also be highly motivated to build reputation, profit, brand loyalty, and a competitive edge right out of the gate—machine learning can be an effective and efficient tool to reach all those goals. That the largest and smallest companies are leading in ML maturity is significant and may speak to and encourage a more equal tech landscape wherein the largest tech voices are not the only voices at play. |
他们也可以非常积极地建立声誉、利润、品牌忠诚度和竞争优势——机器学习可以成为实现所有这些目标的有效工具。 最大和最小的公司在 ML 成熟度方面处于领先地位是非常重要的,并且可能会影响和鼓励一个更平等的技术领域,其中最大的技术声音并不是唯一的声音。 |
Machine learning maturity and company size
机器学习成熟度与公司规模
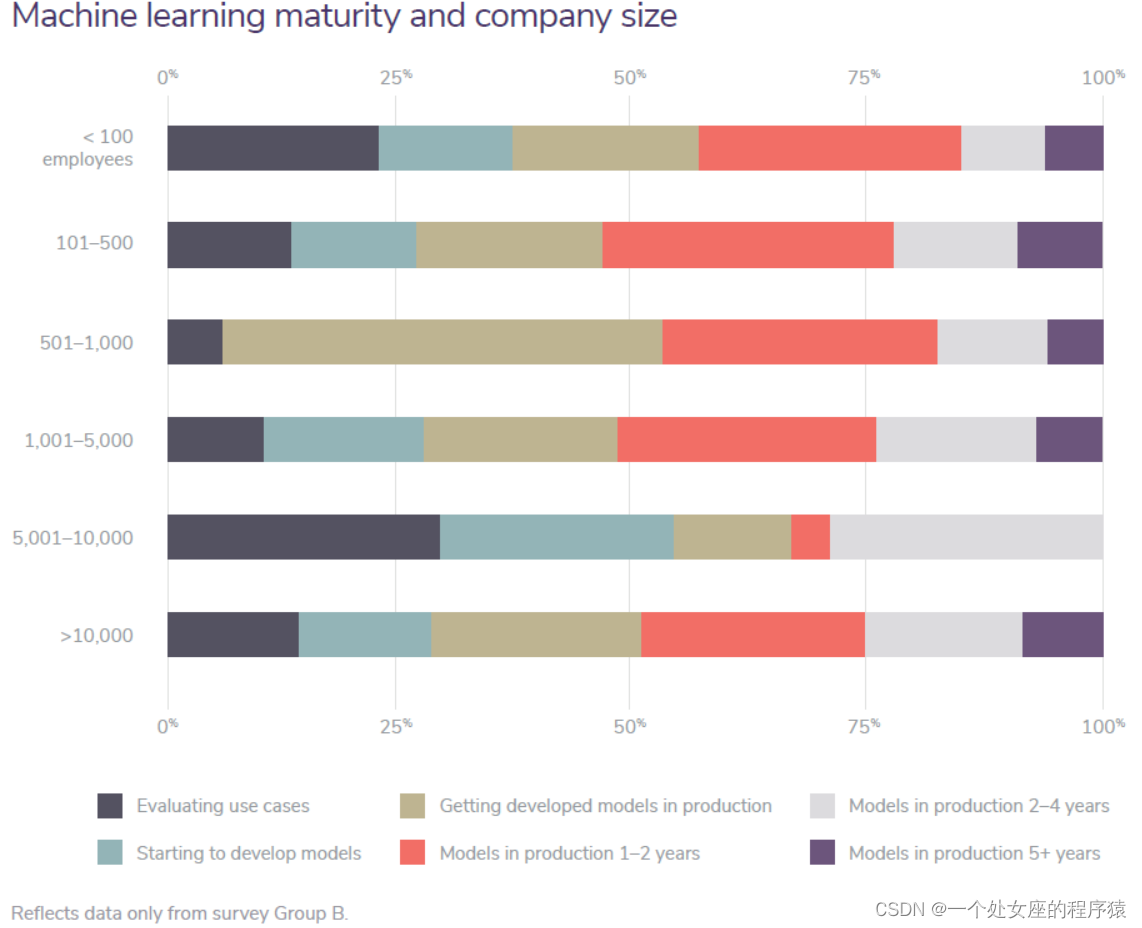
Mid-sized companies span all maturity levels with the highest concentration in the early-to-mid-stage levels of maturity, suggesting that they may have a bit of both worlds—the agility of smaller companies to tackle new projects quickly and growing budgets dedicated to emerging tech (DigitalistMagazine). |
中型公司跨越所有成熟度级别,其中早期到中期成熟度级别的集中度最高,这表明它们可能兼有小型公司快速处理新项目的灵活性和不断增长的新兴技术预算(DigitalistMagazine)。 |
Gauging maturity in the year ahead
衡量未来一年的成熟度
In the next 12 months, we expect the number of companies in the earliest machine learning stages (evaluating use cases and starting to develop models) to expand and then decline as ML becomes ever more ubiquitous in the enterprise. Eventually the early stages will decline as companies proceed through the machine learning lifecycle. |
在接下来的 12 个月中,随着机器学习在企业中变得越来越普遍,我们预计处于最早机器学习阶段(评估用例和开始开发模型)的公司数量会扩大然后下降。最终,随着公司在机器学习生命周期中的发展,早期阶段将逐渐衰落。 |
Anticipated maturity stage in the next 12 months
未来 12 个月的预期成熟阶段
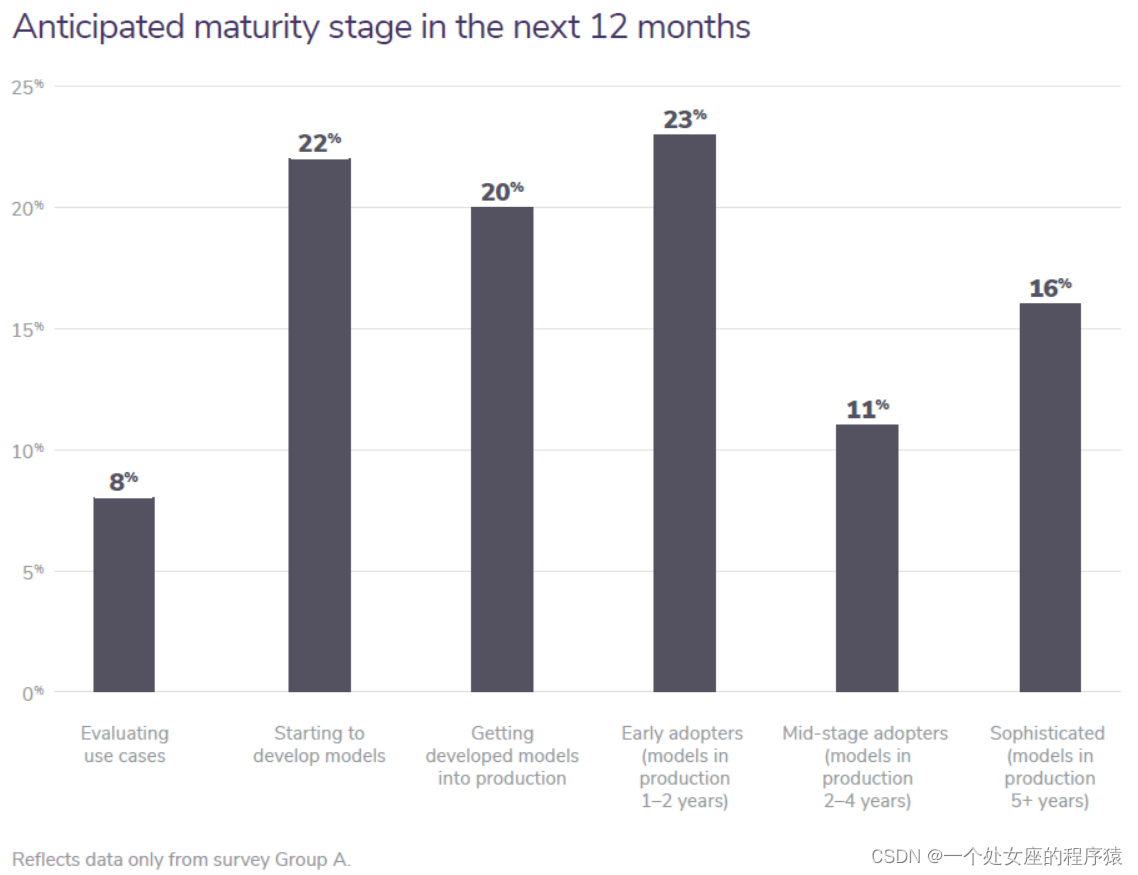
The bottom line is that we do see a shift toward greater ML maturity in all companies surveyed, however, those in mid-to-late stages of maturity are still quite low in number. We expect to see that group grow over the course of the next 12 months as companies overcome last-mileMLproblems and align stakeholders toward building sophistication into their ML programs. |
最重要的是,我们确实看到所有接受调查的公司都在向更高的机器学习成熟度转变,但是,处于成熟中后期的公司数量仍然很少。 随着公司克服最后一英里的机器学习问题,并使利益相关者一致致力于将成熟度构建到其ML计划中,该团队将不断壮大。 |
Key finding 4: An unreasonably long road to deployment不合理的漫长部署之路
Model deployment timeline
模型部署时间表
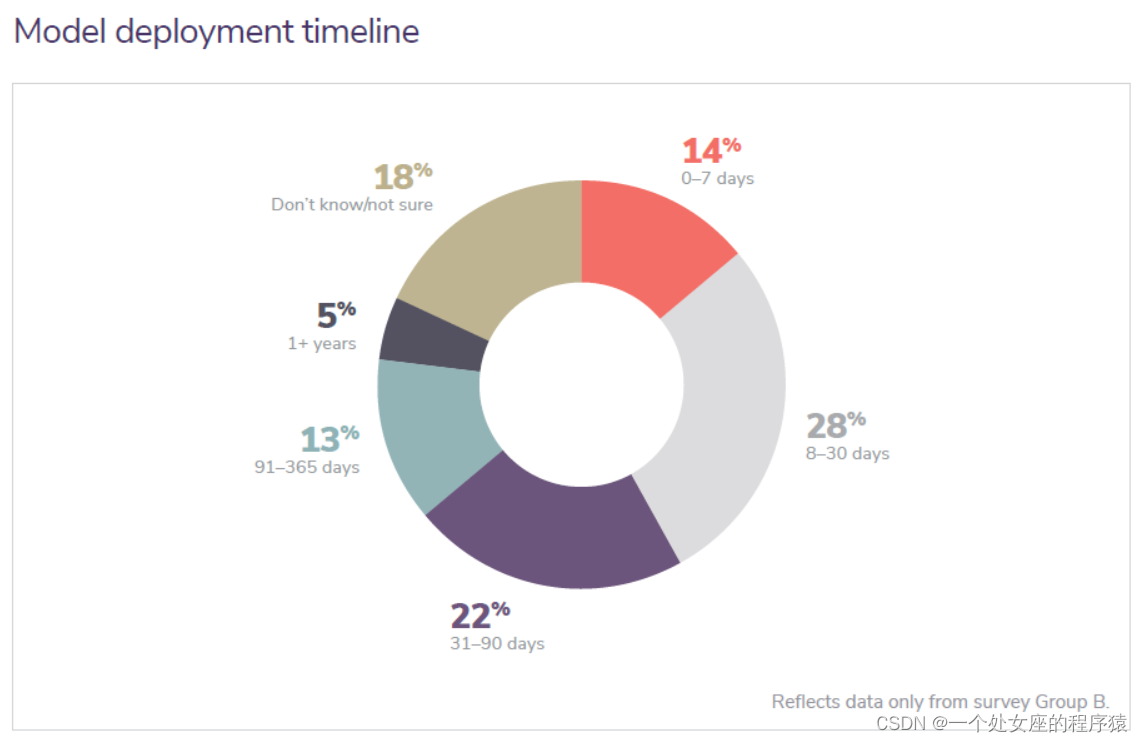
A new metric we are beginning to track this year is the time it takes an organization to deploy a single ML model. Of companies surveyed, just about half say they spend between 8 and 90 days deploying one model. And 18 percent of companies are taking longer than 90 days—some spending more than a year productionizing! We thoroughly understand that there are many challenges to overcome when building a robust ML lifecycle, deployment being a large one (Medium). That being said, we would still have expected the percentage of companies who deploy models in less than a week to be significantly larger than 14 percent, based on the number of companies in the early stage maturity level (models in production for 1-2 years). Company size and maturity level provide some context to explain this relatively low number. |
我们今年开始跟踪的一个新指标是组织部署单个 ML 模型所需的时间。 在接受调查的公司中,只有大约一半表示他们会花费 8 到 90 天来部署一个模型。 18% 的公司需要 90 天以上的时间——有些公司花费了一年多的时间进行生产! 我们完全理解,在构建健壮的ML生命周期时,有许多挑战需要克服,部署是一个大的生命周期(中等)。 话。尽管如此,根据处于早期成熟度水平的公司数量(生产1-2年的模型),我们仍然预计在不到一周的时间内部署模型的公司比例将大大超过14%。公司规模和成熟度水平提供了一些背景来解释这一相对较低的数字。 |
Model deployment timeline and company size
模型部署时间表和公司规模
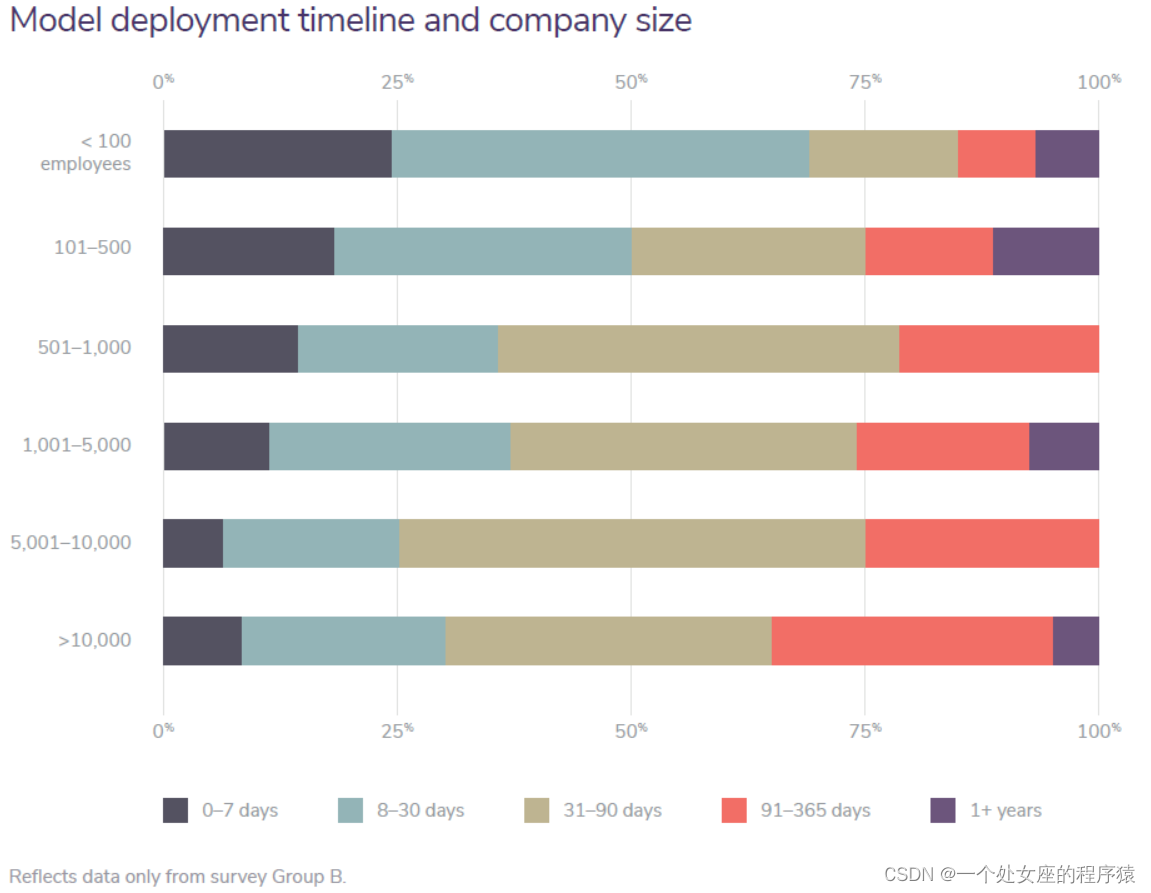
Companies of all sizes typically spend between 8 and 90 days deploying one model, with a few notable exceptions. A small (and we expect decreasing) number of companies is spending more than a year deploying models, and of those, mostly small-to-midsize organizations. Moreover, a fairly significant portion of companies with 100 employees or fewer is spending somewhere between 8 and 30 days deploying a single model. Moreover, there is a slight decrease in the ideal 0-7 day range as company size increases, and on the other side, there is a somewhat uniform indication that the larger the company, the more likely it will spend between 4 and 12 months deploying a model. We assess, however, that the time to deployment phenomenon is less dependent on company size alone and more so on maturity level. |
各种规模的公司通常会花费 8 到 90 天来部署一个模型,但也有一些明显的例外。 一小部分(我们预计会减少)公司花费一年多的时间来部署模型,其中大部分是中小型企业。 此外,相当大一部分员工人数不超过 100 人的公司会花费 8 到 30 天时间来部署一个模型。 此外,随着公司规模的增加,理想的 0-7 天范围略有下降,另一方面,有一个统一的迹象表明,公司越大,部署一个模型的时间 4 到 12 个月的可能性就越大。 然而,我们评估说,部署时间的现象不仅仅取决于公司规模,而更多地取决于成熟度。 |
Model deployment timeline and ML maturity
模型部署时间表和ML成熟度
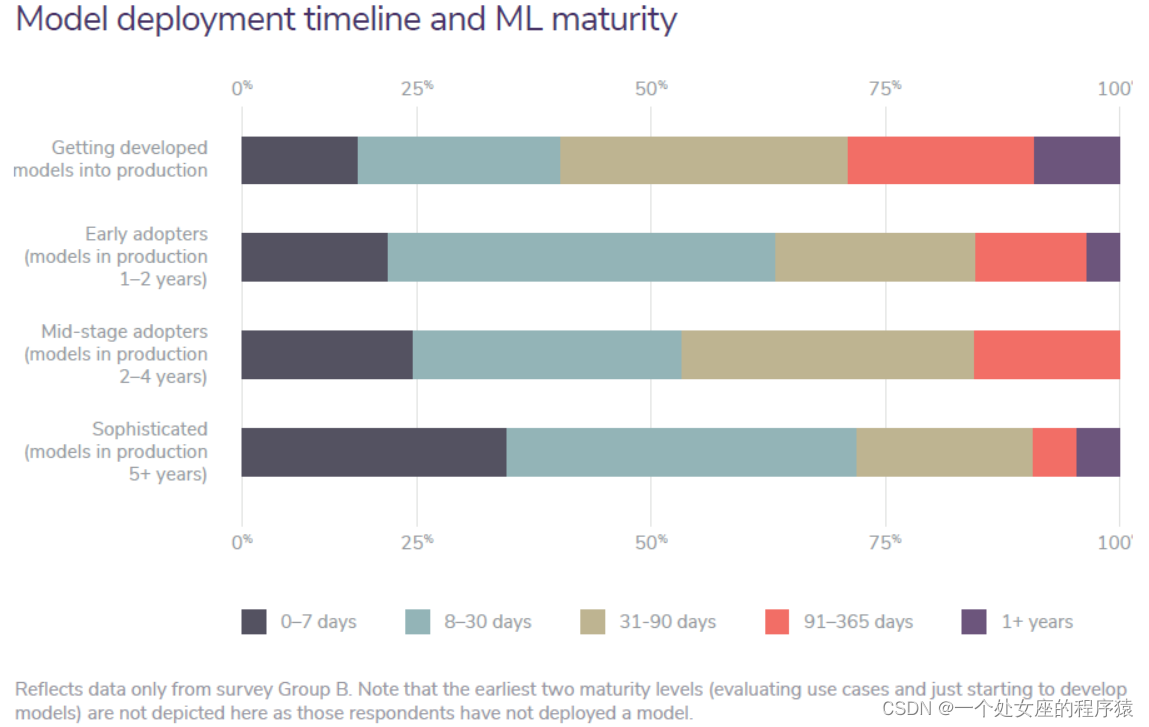
Most noticeable—and understandable—is the increase in the 0-7 day range as companies’ machine learning programs mature. It follows that the more sophisticated a company’s ML efforts are, the more likely it is to deploy a model quickly. Also noteworthy is that the more sophisticated a company becomes, the more time it spends in the 8-30 day range for model deployment. Our best guess as to why is discussed in Key finding 5, the challenges associated with machine learning. In short, struggles with scale and aligning all stakeholders can add to timelines. |
随着公司机器学习程序的成熟,最引人注目且可以理解的是 0-7 天范围的增加。 因此,公司的 ML 工作越复杂,就越有可能快速部署模型。 同样值得注意的是,公司越成熟,在 8-30 天范围内用于模型部署的时间就越多。 我们对原因的最佳猜测在关键发现 5(与机器学习相关的挑战)中进行了讨论。 简而言之,与规模和协调所有利益相关者的斗争可以增加时间表。 |
Data science workload and the last mile to deployment
When we look at the actual time spent deploying models, we see that at companies of all sizes, at least 25 percent of data scientist time is spent on deployment efforts. Put simply, a quarter of data science capability is lost to infrastructure tasks. In 2018, closer to 70 percent of data science capability was spent lost to deploying models, which at face value, appears to imply drastic improvement. However, the data cannot tell us definitely why this large decrease occurred. Ideally, it’s due to data scientists having the tools they need to deploy with ease, but based on the low number of companies in the deployed category, we are not confident in that assessment. It is more likely that data science teams are handing off more of their models to a DevOps or IT team to deploy, if it’s happening at all. “I’ve heard many variants of this story: they all capture a misaligned pace of work between product and machine learning teams. Ultimately, this leads to machine learning research never making it out of the lab. And yet, the best measure of impact for machine learning, if you work in a non-research institution, is whether you can use it to help your customers—and that means getting it out of the door” (Medium). |
当我们查看部署模型所花费的实际时间时,我们发现在各种规模的公司中,至少 25% 的数据科学家时间都花在了部署工作上。简而言之,基础设施任务损失了四分之一的数据科学能力。 2018 年,近 70% 的数据科学能力被用于部署模型,从表面上看,这似乎意味着大幅改进。但是,数据无法明确告诉我们为什么会出现这种大幅下降。理想情况下,这是由于数据科学家拥有轻松部署所需的工具,但基于已部署类别中的公司数量较少,我们对该评估没有信心。数据科学团队更有可能将更多模型移交给 DevOps 或 IT 团队进行部署(如果这种情况发生的话)。 “我听说过这个故事的许多说法:它们都反映了产品和机器学习团队之间的工作节奏不一致。最终,这导致机器学习研究永远无法走出实验室。然而,如果您在非研究机构工作,衡量机器学习影响的最佳方法是你是否可以利用它来帮助你的客户,这意味着要把它带出门”(中等)。 |
Time data scientists spend deploying models by company size
数据科学家按公司规模部署模型的时间
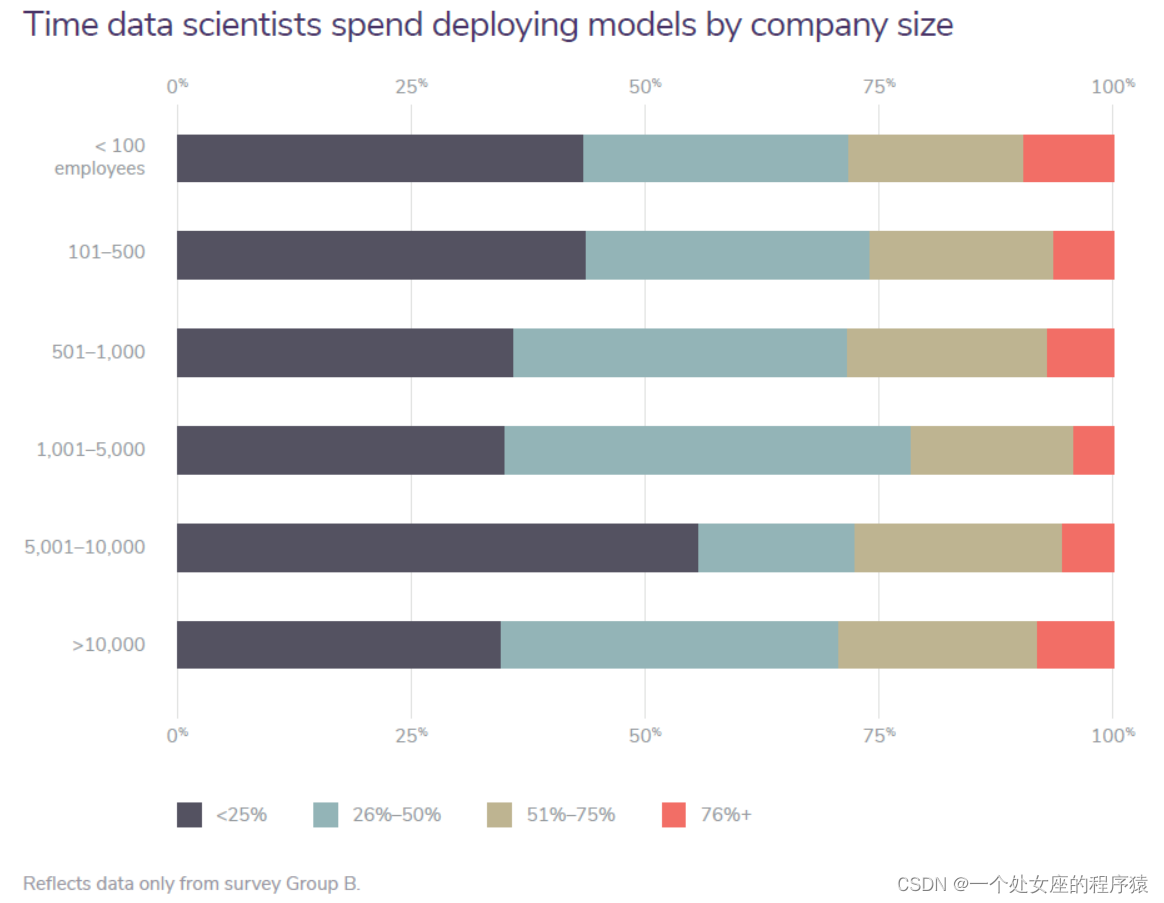
Data science teams need to be able to deploy their work as quickly as possible to prevent their insights from being overcome by events (OBE); models and data change quickly as do market opportunities. As such, an insight that comes 10 days too late is OBE and no longer useful. To that end, much of the potential of ML may yet to be seen. “This is why AI has yet to reshape most businesses: For many companies, deploying AI is slower and more expensive than it might seem” (MITTechnologyReview). In November 2019, Gartner said that the “increased use of commercial AI and ML will help to accelerate the deployment of models in production, which will drive business value from these investments” (Gartner). It went on to assess that the majority of teams developing ML capabilities are doing so using open-source tooling because of the dearth of viable commercial options. We assess that that gap is soon to be filled with companies offering a full suite of ML tooling as companies seek to become more mature in their ML lifecycles and look for third-party solutions rather than spending valuable time building ML infrastructure. |
数据科学团队需要能够尽快部署他们的工作,以防止他们的见解被事件(OBE)所克服;模型和数据变化很快,市场机会也在变化。因此,迟到 10 天的洞察力是 OBE,不再有用。为此,ML的许多潜力可能尚未被发现。 “这就是为什么 AI 尚未重塑大多数企业的原因:对于许多公司来说,部署 AI 比看起来更慢且更昂贵”(MITTechnologyReview)。 2019 年 11 月,Gartner 表示,“商业 AI 和 ML 的使用增加将有助于加速模型在生产中的部署,这将推动这些投资的商业价值”(Gartner)。它继续评估,由于缺乏可行的商业选择,大多数开发 ML 功能的团队都在使用开源工具这样做。我们估计,随着公司寻求在其 ML 生命周期中变得更加成熟并寻找第三方解决方案,而不是花费宝贵的时间构建 ML 基础设施,这一差距很快就会被提供全套 ML 工具的公司填补。 |
It is worth sharing here a word of warning from Ryan Calo, an associate law professor at the University of Washington, who is also a co-founder of the Tech Policy Lab and a leading voice on law and emerging tech issues in the media. At a recent SeattleTimes–sponsoredpanel discussion on AI and the future of work,Calo cautioned attendees about snake oil AI companies. He described a plausible future scenario in which countless third-party AI solutions flood the market, creating a cacophony of messaging about AI necessities. The resulting confusion might allow AI firms to take advantage of non-technical customers who hope to stay competitive in their spaces. They may pay for services that are inappropriate or unnecessary for their business in order to mature their ML programs quickly. It is important at a time of rapid technological innovation, such as now, to tread intelligently and not fall victim to the “AIforAI’ssake” adage. |
值得在这里分享华盛顿大学法学副教授 Ryan Calo 的警告,他也是科技政策实验室的联合创始人,也是媒体上法律和新兴技术问题的主要发言者。在最近由《西雅图时报》赞助的关于人工智能和工作未来的小组讨论中,Calo 提醒与会者注意蛇油人工智能公司。他描述了一个似是而非的未来场景,无数第三方人工智能解决方案涌入市场,制造了关于人工智能必需品的不和谐消息。 由此产生的混乱可能会让人工智能公司利用那些希望在他们的领域保持竞争力的非技术客户。他们可能会为他们的业务不合适或不必要的服务付费,以便让他们的 ML 程序快速成熟。在像现在这样快速技术创新的时代,重要的是要明智地行事,不要成为“AIforAI”格言的牺牲品。 |
Key finding 5: Innovation hubs and the trouble with scale创新中心和规模问题
A crucial component of realizing ML’s full potential is scale. Can it scale? Scaling models was the biggest overall challenge cited by respondents this year (43 percent). For comparison, that percentage is up 13 percent from last year. But multiple requirements factor into scaling—hardware, modularity, data sourcing, etc.—and optimizing for it can lead to cumbersome team cross-cutting (Arc.dev). Of respondents from companies of more than 10,000 employees, 58 percent said scaling up was their top ML challenge. This may be demonstrative of decentralized organizational structures—data science teams siloed throughout company org charts—which can cause tooling, framework, and even programming language friction when scaled. Earlier this year, Gartner predicted that “through 2020, 80 percent of AI projects will remain alchemy, run by wizards whose talents will not scale in the organization” (Gartner). This outlook may prove true, but, we are skeptical based on our observations of a continuous increase in centralized innovation hubs and emerging tech centers (see Ericsson, IBM, Pfizer, etc.). We assess these hubs will be more efficient at maturing ML for their companies than the decentralized alternative (ie. data science components siloed throughout organizations working on one-off projects and models). An innovation hub can iterate quickly, work with agility across an organization, and standardize ML efforts. They can often vet new technologies quickly, ensuring their companies keep at the bleeding edge of technological development. We anticipate this kind of centralized focus on ML and AI technologies may just turn lead into gold, so to speak. |
实现 ML 全部潜力的一个关键组成部分是规模。它可以扩展吗?扩展模型是今年受访者提到的最大的总体挑战(43%)。相比之下,这个百分比比去年增加了 13%。但是多个需求因素会影响扩展——硬件、模块化、数据源等——并对其进行优化可能会导致繁琐的团队交叉 (Arc.dev)。 在员工人数超过 10,000 人的公司的受访者中,58% 的人表示扩大规模是他们面临的最大 ML 挑战。这可能表明分散的组织结构数据科学团队分散在整个公司组织结构图中,这可能导致工具、框架甚至编程语言在扩展时产生摩擦。 今年早些时候,Gartner 预测“到 2020 年,80% 的 AI 项目仍将是炼金术,由奇才管理,他们的才能在组织中无法扩展”(Gartner)。这种前景可能被证明是正确的,但是,基于我们对集中式创新中心和新兴技术中心(参见爱立信、IBM、辉瑞等)不断增加的观察,我们持怀疑态度。我们评估这些中心在为他们的公司成熟 ML 方面将比分散的替代方案(即数据科学组件孤立在从事一次性项目和模型的组织中)更有效。创新中心可以快速迭代,跨组织灵活工作,并使ML工作标准化。他们通常可以快速审查新技术,确保其公司保持在技术发展的前沿。我们预计,这种对ML和AI技术的集中关注可能会让铅变成黄金。 |
Model reproducibility impedes ML maturity
The second most cited ML challenge was versioning and reproducibility of models (41 percent of respondents reported this). This number is much higher than the 24 percent of respondents who cited this challenge in 2018. Machine learning requires faster iteration than the traditional software development lifecycle, and ironclad version-control is paramount for pipelining, retraining, and evaluating models for accuracy, speed, and drift. Versioning is one of the hurdles that data science and ML teams must overcome to reach more sophisticated levels of ML maturity, so in future surveys, we will be monitoring this metric closely. We expect the number of times this is cited as a challenge to decrease in the coming year. |
被引用次数第二多的 ML 挑战是模型的版本控制和可重复性(41% 的受访者报告了这一点)。 这个数字远高于 2018 年提到这一挑战的 24% 的受访者。机器学习需要比传统软件开发生命周期更快的迭代,而铁的版本控制对于流水线、再培训和评估模型的准确性、速度和漂移至关重要。 版本控制是数据科学和 ML 团队必须克服的障碍之一,以达到更复杂的 ML 成熟度水平,因此在未来的调查中,我们将密切监控这一指标。 我们预计,在未来一年,这一挑战被引用的次数将减少。 |
Year comparison of machine learning challenges
机器学习挑战的年份比较
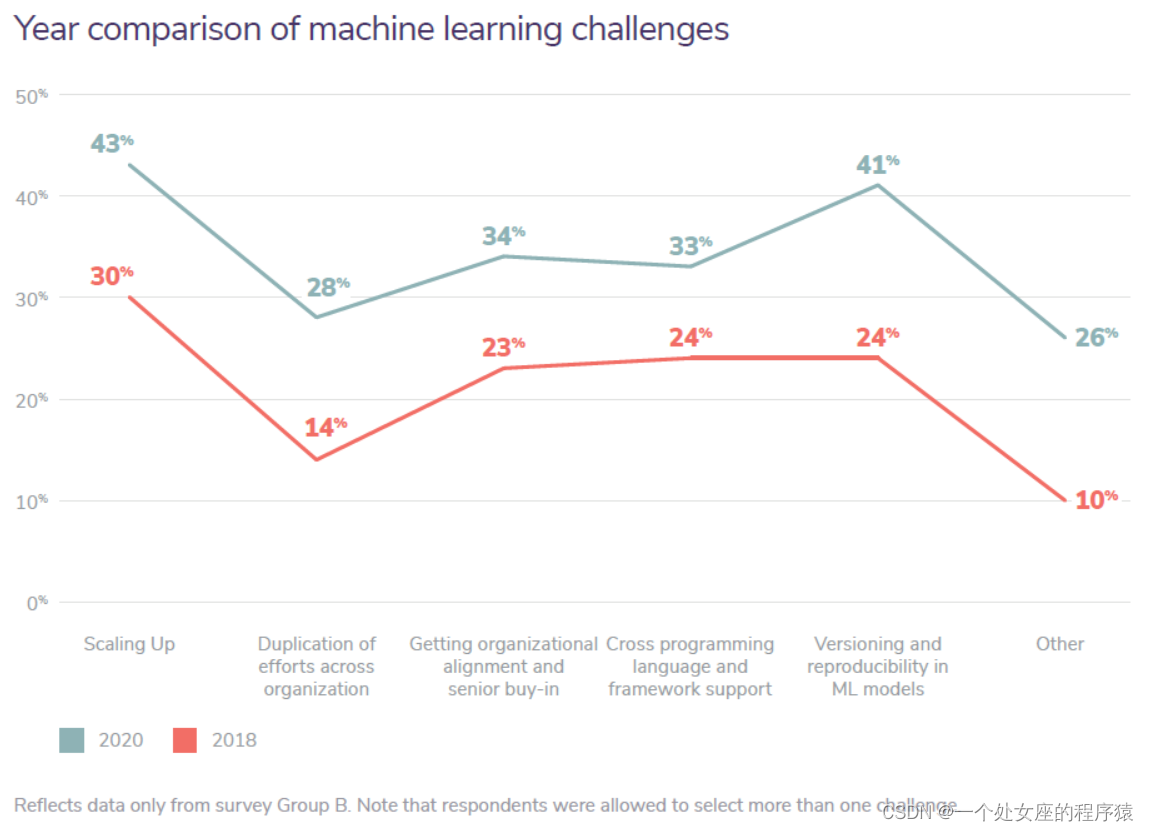
Reflects data only from survey Group B. Note that respondents were allowed to select more than one challenge. |
仅反映来自调查组 B 的数据。请注意,受访者可以选择多个挑战。 |
Organizational misalignment and ML progress
组织错位和机器学习进展
The third most cited ML challenge was getting organizational alignment and senior buy-in for ML initiatives (34 percent). Notably of the respondents who cited this challenge, 47 percent are from companies with more than 10,000 employees. Especially for decentralized organizations (no central innovation hub), trying to obtain multiple team and stakeholder concurrence may take a lot of time. In 2018, 23 percent of respondents noted stakeholder alignment as a challenge. The 24-percent increase this year might contribute to other metrics, such as number of models deployed, time to deployment, and scaling. We expect this problem to decline in coming years as ML becomes more routine, reliable, and measurable. |
第三个被引用次数最多的 ML 挑战是是组织一致性和高层对ML计划的认同(34%)。 值得注意的是,在提到这一挑战的受访者中,47% 来自拥有超过 10,000 名员工的公司。 特别是对于去中心化的组织(没有中央创新中心),试图获得多个团队和利益相关者的同意可能需要很多时间。 2018 年,23% 的受访者认为利益相关者的一致性是一项挑战。 今年 24% 的增长可能有助于其他指标,例如部署的模型数量、部署时间和扩展。 随着机器学习变得更加常规、可靠和可测量,我们预计这个问题将在未来几年内减少。 |
Key finding 6: Budget and machine learning maturity, priorities and industry预算和机器学习成熟度、优先级和行业
This year’s survey shows that ML budgets vary across industry and stage of maturity, but on the whole, are growing at companies of all sizes. This is in line with estimates that in 2018, the compound annual growth rate (CAGR) of AI was $23.94 billion and is expected to reach $208.49 billion by 2025 (MarketWatch). |
今年的调查显示,ML 预算因行业和成熟阶段而异,但总体而言,各种规模的公司都在增长。 这与2018年人工智能的复合年增长率(CAGR)为239.4亿美元的估计一致,预计到2025年将达到2084.9亿美元(MarketWatch)。 |
AI/ML budgets FY18 to FY19
AI/ML 预算 2018财年 至 2019 财年
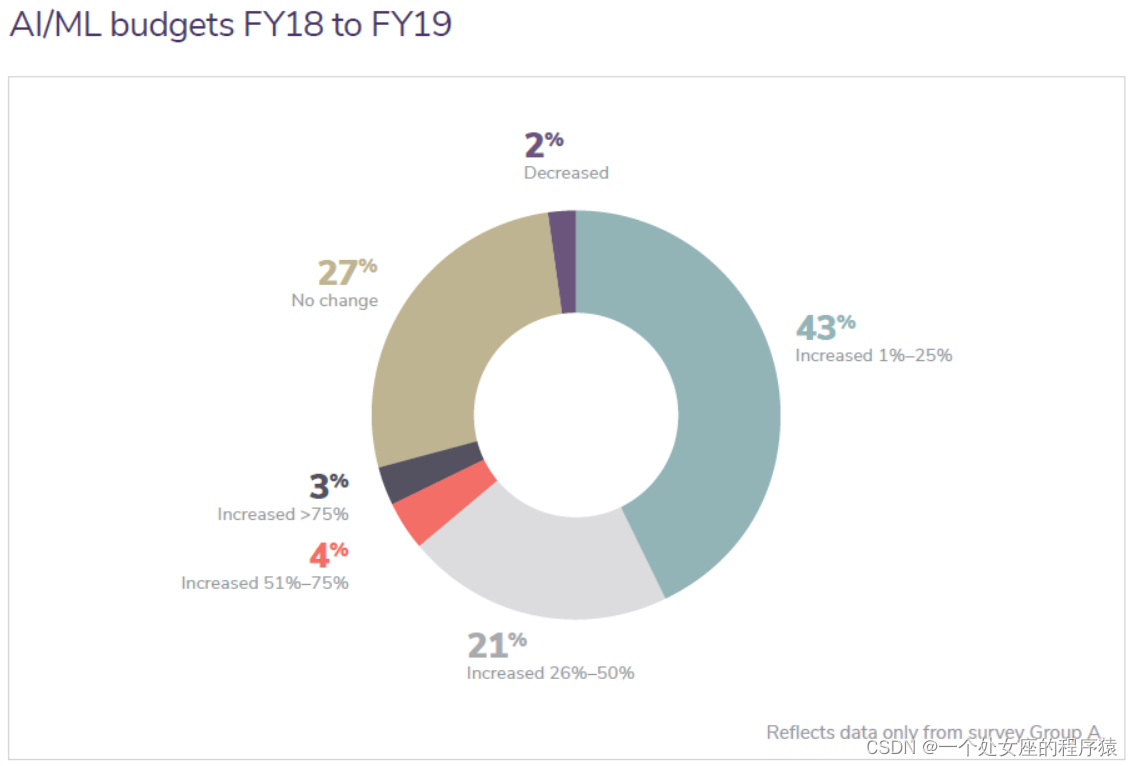
Twenty-one percent of respondents said budgets for AI/ML programs were growing between 26-50 percent. Forty-three percent of companies have increased their AI/ML budgets between 1 and 25 percent in the last year. And just under one-third (27 percent) of respondents noted that their budgets have not changed. This may be a reason why the majority of companies are still at early-stage maturity levels. |
21%的受访者表示,AI/ML项目的预算增长率在26%至50%之间。43%的公司在去年将AI/ML预算增加了1%到25%。只有不到三分之一(27%)的受访者表示他们的预算没有改变。这可能是大多数公司仍处于早期成熟水平的一个原因。 |
Budgets and ML maturity
预算和机器学习成熟度
Fifty-seven percent of companies in the mid-level maturity range (ML models in production for 2-4 years) increased their budgets between 1 and 25 percent. Close to 50 percent of companies at early stage maturity levels also increased their budgets between 1 and 25 percent. And nearly 40 percent of companies already at sophisticated ML maturity levels increased their budgets by as much as 25 percent. Finally, 30 percent of sophisticated maturity respondents said they increased their AI/ML budgets by 26-50 percent. We expect to see mid-stage and sophisticated companies increase their AI/ML budgets by more than a quarter in the very near term once ML has proven itself. |
57% 处于中等成熟度范围(生产 2-4 年的机器学习模型)的公司将预算增加了 1% 到 25%。 接近 50% 处于早期成熟度水平的公司也将预算增加了 1% 到 25%。 近 40% 的公司已经处于复杂的 ML 成熟度级别,其预算增加了多达 25%。 最后,30% 成熟的受访者表示他们将 AI/ML 预算增加了 26-50%。 一旦 ML 证明了自己,我们预计将在短期内看到中期和成熟的公司将其 AI/ML 预算增加四分之一以上。 |
FY19 AI/ML budgets and ML maturity level
2019 财年 AI/ML 预算和 ML 成熟度级别
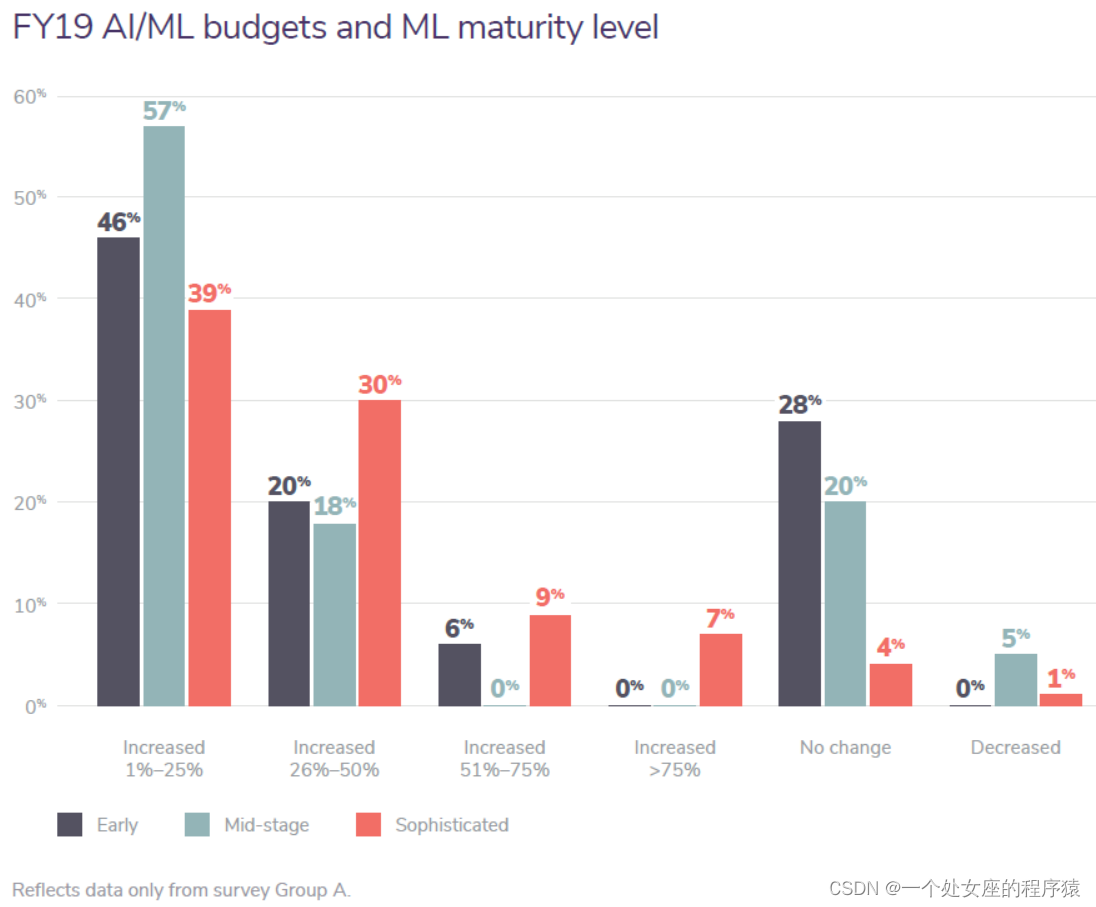
We assess that this upward budgetary trend is due to the fact that companies already at a mid or sophisticated level of ML maturity (models built and deployed for 2-5 years), are doubling down on their tech investment efforts. This means that companies in very early deployment stages ( just starting to develop ML models) will have to triple their efforts to stay competitive in their industry. Now is the time to start planning a 2020 (and beyond) ML strategy. From an industry perspective, there was budgetary growth in specific industries, suggesting some jockeying for ML prowess in the nascent space. |
我们评估,这种预算上升的趋势是由于公司已经处于中等或复杂的机器学习成熟度水平(构建和部署了 2-5 年的模型),正在加倍投入技术投资。 这意味着处于非常早期部署阶段(刚刚开始开发 ML 模型)的公司将不得不加倍努力以保持其行业竞争力。 现在是开始规划 2020 年(及以后)机器学习战略的时候了。 从行业的角度来看,特定行业的预算有所增长,这表明新兴领域的ML实力受到了一些争夺。 |
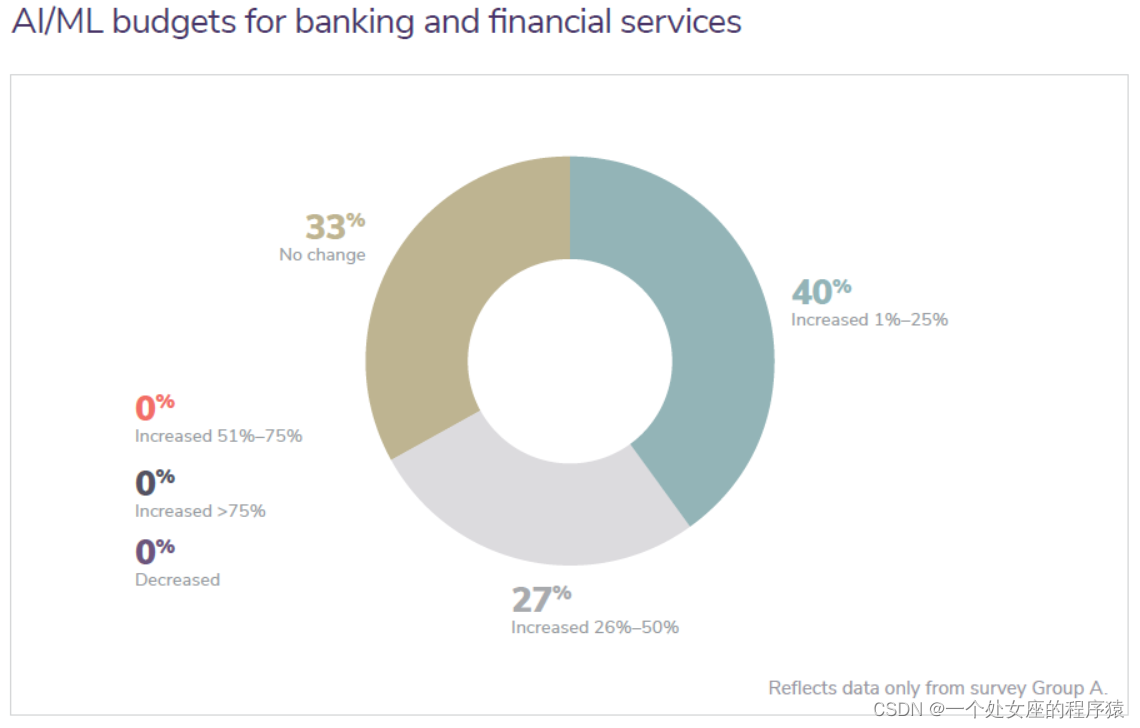
AI/ML budgets for banking and financial services
银行和金融服务的 AI/ML 预算
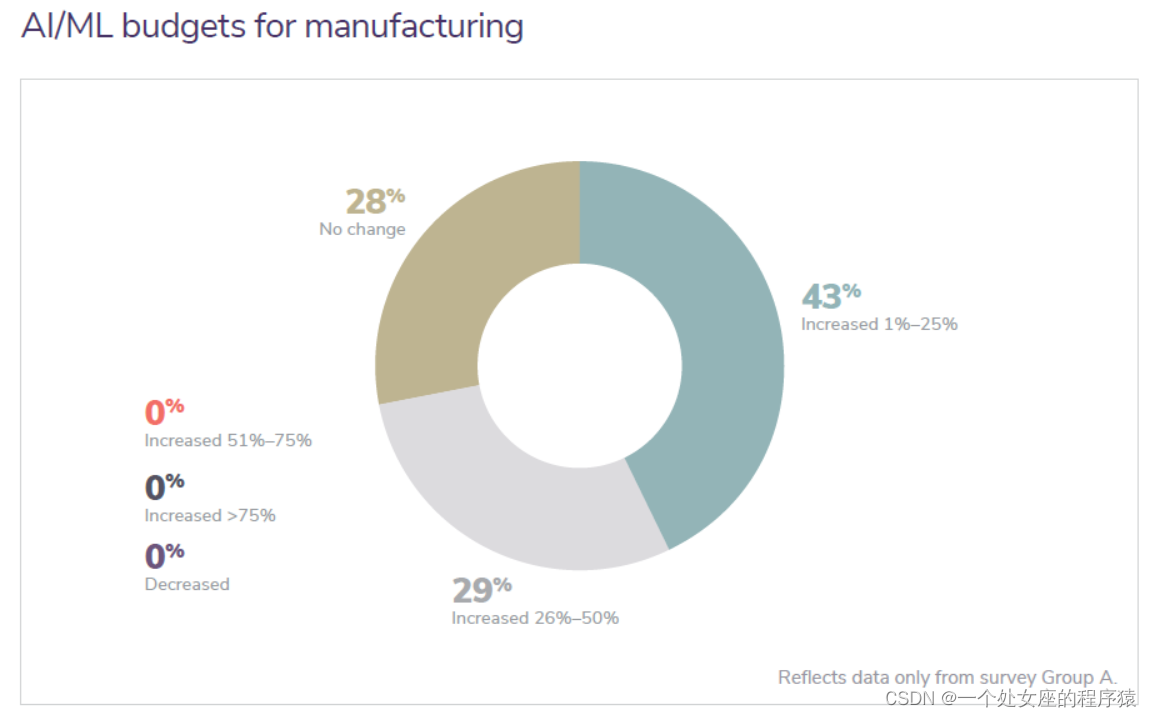
AI/ML budgets for manufacturing
制造业的 AI/ML 预算
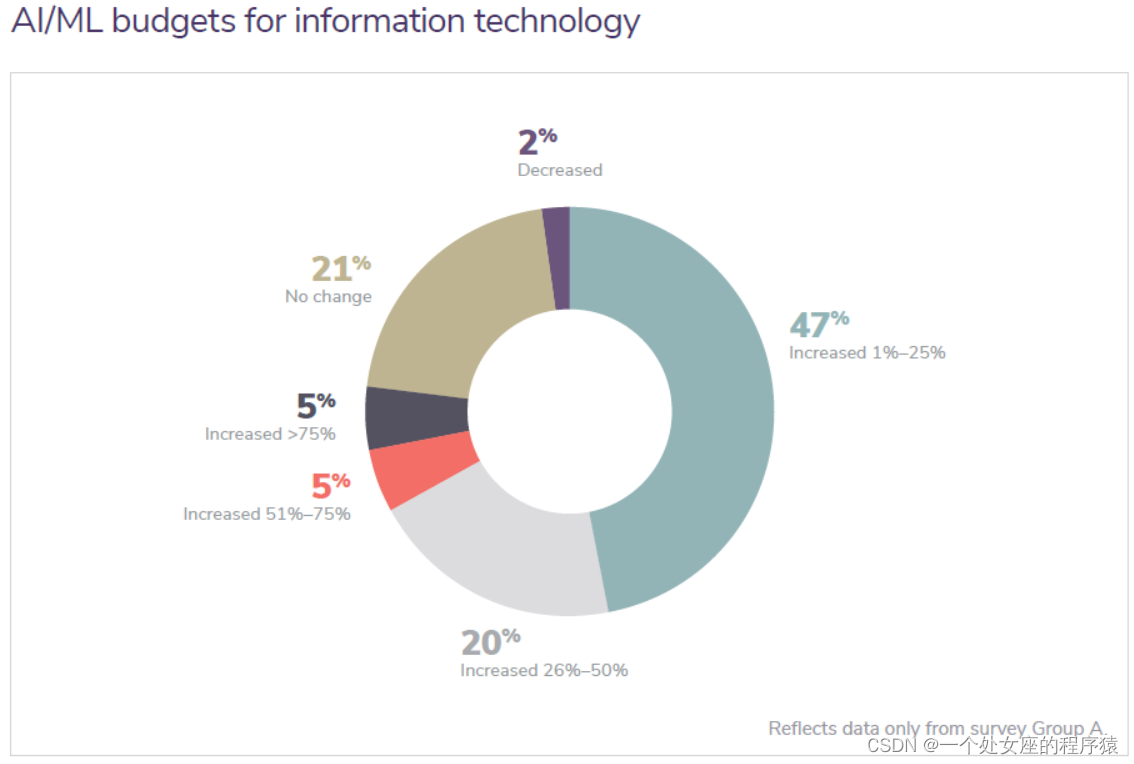
AI/ML budgets for information technology
信息技术的 AI/ML 预算
Key finding 7: Determining machine learning success across the org chart在整个组织结构图中确定机器学习的成功
While it is still early days for ML in the enterprise, our seventh key finding (how companies are determining what success means for their ML efforts) is likely an indicator of the path that machine learning will take as it develops throughout the enterprise (Emerj). Our hypothesis was that if ML success is primarily measured by dollars saved, then ML models designed to reduce costs are likely to be developed in droves, more so than any of countless other ML applications. The top two metrics for discerning ML success as noted by respondents this year were tied for first place: business metrics, such as guaranteed ROI, and a more technical evaluation of ML model performance. Across all industries and company size, 58 percent of respondents said ML efforts are successful if they produce ROI, reduce customer churn, aid in product adoption, and/or promote brand fidelity. And another 58 percent of respondents said ML efforts are successful when model accuracy, precision, speed, and drift meet threshold. (Note that respondents were encouraged to select more than one answer option, accounting for the more than 100 percent total.) |
虽然机器学习在企业中的应用还处于起步阶段,但我们的第七个关键发现(公司如何确定其机器学习工作的成功意义)很可能是机器学习在整个企业发展过程中所走道路的一个指标(Emerj)。 我们的假设是,如果ML的成功主要是通过节省的资金来衡量的,那么设计用于降低成本的ML模型可能会大量开发,这比无数其他ML应用程序都要多。 今年受访者指出,辨别机器学习成功的前两个指标并列第一:业务指标,如保证的投资回报率,以及对机器学习模型性能的技术性评估。 在所有行业和公司规模中,58% 的受访者表示,如果 ML 能够产生投资回报率、减少客户流失、帮助产品采用和/或提升品牌忠诚度,那么它们是成功的。另有 58% 的受访者表示,当模型准确性、精度、速度和漂移达到阈值时,ML 工作是成功的。 (请注意,鼓励受访者选择多个答案选项,占总数的 100% 以上。) |
When those percentages are broken down by role, an interesting separation occurs. The individual contributor level (data scientist, software developer) values technical measures of ML success more so than the business metrics, and C-level executives and VPs generally place more value on the opposite—measuring ML success by how it ultimately benefits the company at a strategic level. The director level is in the middle, valuing both the business unit impact (ROI, budgetary, strategic planning metrics) as well as the more technical metrics surrounding model performance. We assess that the director level will prove to be the crux of ML decisions made within organizations in the coming years as they seek to demonstrate their teams’ capabilities but also prove to senior management that ML is a worthwhile investment to make. To that end, we expect to see an increase in the number of proof of concepts demanded of ML tooling companies by organizations looking to build ML programs or mature their current efforts. This expectation works into our assessment that aligning stakeholders and obtaining senior buy-in will also become less of a challenge in the near term. |
当这些百分比按角色细分时,就会发生有趣的分离。个人贡献者级别(数据科学家、软件开发人员)比业务指标更重视 ML 成功的技术衡量标准,而C级高管和VP通常更看重相反的衡量ML成功的方法,即从战略层面衡量ML成功的最终收益。 director 级别处于中间位置,既重视业务部门的影响(投资回报率、预算、战略规划指标),也重视围绕模型性能的更多技术指标。我们评估,director 级别将被证明是未来几年组织内做出 ML 决策的关键,因为他们试图展示其团队的能力,同时也向高级管理层证明 ML 是值得投资的。 为此,我们预计希望构建 ML 程序或使当前工作成熟的组织对 ML 工具公司要求的概念证明数量会有所增加。这种预期符合我们的评估,即协调利益相关者和获得高级支持也将在短期内变得不那么具有挑战性。 |
“Machine learning will be the biggest technological shift of our generation, enabling businesses to achieve their full potential.”Diego Oppenheimer, CEO Algorithmia |
“机器学习将是我们这一代人最大的技术转变,使企业能够充分发挥潜力。”Diego Oppenheimer,Algorithmia 首席执行官 |
The future of machine learning
In our survey report from last year, we concluded that ML was very much in pioneering days, with most companies only just beginning to develop use cases, build models, and align teams. Twelve months later, we see the ML landscape already changing as early efforts to build healthy ML lifecycles become more streamlined. Our hypotheses for the near-term future include the following: (1)、A growing number of data scientists employed at mid-sized companies to help gain industry edge using ML (2)、Lower levels of customer satisfaction at large corporations as they prioritize cutting costs (3)、The advent of more innovation hubs to drive ML adoption within organizations (4)、An increase in director-level roles stewarding ML progress across all industries |
在我们去年的调查报告中,我们得出的结论是,机器学习处于非常开创性时期,大多数公司才刚刚开始开发用例、构建模型和调整团队。12个月后,我们看到,随着构建健康的ML生命周期的早期努力变得更加精简,ML环境已经发生了变化。 我们对近期未来的假设包括: (1)、越来越多的数据科学家受雇于中型公司,以帮助利用机器学习获得行业优势 (2)、大公司的客户满意度较低,因为他们优先考虑削减成本 (3)、更多创新中心的出现推动组织内部采用机器学习 (4)、管理所有行业机器学习进展的director级角色增加 |
We are convinced that company size is not a determinant of ultimate ML maturity level, and we look forward to the future where companies of all sizes in all industries can implement machine learning to automate and augment their business goals. We are particularly curious about what the near-term future holds for machine learning use cases. The trend of using ML to automate fairly formulaic tasks will soon give rise to more complex and pipelined ML workflows. As that happens, the infrastructure needed to compute those more compound applications will also change, requiring practitioners to make choices about tech tooling that may affect infrastructural performance or flexibility down the road. This year’s survey report should confirm for readers that machine learning in the enterprise is progressing in haste. Though the majority of companies are still in the early stages of ML maturity, it is incorrect to think there is time to delay your ML efforts. If your company is not currently ML–minded, rest assured your competitors are, and the rate of AI’s development is bound to increase exponentially. Now is the time to future-proof your organization with AI/ML. Join the 2020 state of enterprise machine learning conversation @algorithmia #2020StateOfML |
我们坚信,公司规模并不是最终 ML 成熟度水平的决定因素,我们期待未来所有行业的各种规模的公司都可以实施机器学习来自动化和增强他们的业务目标。 我们对机器学习用例的近期前景特别好奇。使用 ML 自动化相当公式化的任务的趋势将很快产生更复杂和流水线化的 ML 工作流。随着这种情况的发生,计算这些更复杂应用程序所需的基础设施也将发生变化,要求从业者选择可能影响基础设施性能或灵活性的技术工具。 今年的调查报告应该向读者证实,企业中的机器学习进展迅速。尽管大多数公司仍处于 ML 成熟的早期阶段,但认为有时间推迟您的 ML 工作是不正确的。如果你的公司目前没有ML意识,请放心,你的竞争对手是,人工智能的发展速度肯定会成倍增长。现在是时候用AI/ML证明您的组织的未来了。现在是使用 AI/ML 让您的组织面向未来的时候了。 加入 2020 年企业机器学习状态对话@algorithmia #2020StateOfML |
Methodology 方法
The purpose of the 2020 State of Enterprise Machine Learning report is to examine the progression of ML across the business landscape and compare the current state with that from 12 months ago to begin to identify trends, anomalies, or patterns of behavior. This report is based on data Algorithmia collected in the fall of 2019 in a two-prong survey effort that returned 745 respondents. The first prong (referred to herein as Group A) comprised a set of 20 questions pertaining to machine learning efforts, capabilities, and company demographics, and was disseminated by an independent third-party company on Algorithmia’s behalf. This was done to ensure survey attribution anonymity and remove bias for or against Algorithmia on the part of the respondents. The third party sourced a random sample panel of business leaders and ML practitioners (individual contributor, manager, director, and executives) at companies using data science for machine learning. Group A respondents voluntarily participated in the survey and were offered a small compensation by the third party for doing so. Algorithmia received the raw data following the third party’s survey completion after all identifiable respondent demographic information was removed by the third party. |
2020 年企业机器学习状态报告的目的是检查 ML 在整个业务领域的进展,并将当前状态与 12 个月前的状态进行比较,以开始识别趋势、异常或行为模式。本报告基于 Algorithmia 在 2019 年秋季在一项双管齐下的调查工作中收集的数据,该调查返回了 745 名受访者。 第一个问题(在此称为 A 组)包含一组 20 个与机器学习工作、能力和公司人口统计相关的问题,由一家独立的第三方公司代表 Algorithmia 传播。这样做是为了确保调查归因匿名并消除受访者对算法的偏见。第三方在使用数据科学进行机器学习的公司中随机抽取了一个由商业领袖和 ML 从业者(个人贡献者、经理、董事和高管)组成的样本小组。 A 组受访者自愿参与调查,并因此获得第三方的小额补偿。在第三方删除所有可识别的受访者人口统计信息后,Algorithmia 在第三方完成调查后收到原始数据。 |
The third party screened respondents using the following questions: (1)、Does your company employ data scientists? (2)、Which role best describes your title/role within your organization? (3)、Which industry do you currently work in? (4)、Which stage of ML maturity is your company in? If respondents gave specific “I do not know or I am unsure” or null answers, they were removed from the respondent pool. In this way, Algorithmia amassed a group of 303 individuals with a level of insight into the machine learning efforts of their companies across a random sampling of industries, company sizes, and machine learning maturity levels. The second prong (referred to herein as Group B) consisted of 21 questions pertaining to machine learning efforts, capabilities, and company demographics and was disseminated internally by Algorithmia with the company name and logo on it. Most questions overlapped with those in the third party’s survey, but there were several exceptions, one of which was email address, which was collected in order to fulfill 10 random $50 gift card incentives. The survey explained that a respondent’s email would be used solely for the gift card purpose, and Algorithmia maintained survey integrity by ensuring the respondents’ answers were not connected with their email addresses in any way. |
第三方使用以下问题筛选受访者: (1)、贵公司是否雇佣数据科学家? (2)、哪个角色最能描述您在组织中的头衔/角色? (3)、您目前从事哪个行业? (4)、贵公司处于ML成熟度的哪个阶段? 如果受访者给出了具体的“我不知道或我不确定”或空答案,他们就会从受访者库中删除。通过这种方式,Algorithmia 在行业、公司规模和机器学习成熟度级别的随机抽样中聚集了一组 303 人,他们对他们公司的机器学习工作有一定程度的洞察力。 第二部分(此处称为 B 组)由 21 个与机器学习工作、能力和公司人口统计相关的问题组成,由 Algorithmia 在内部传播,上面有公司名称和徽标。大多数问题与第三方调查中的问题重叠,但也有几个例外,其中之一是电子邮件地址,收集该地址是为了满足 10 个随机的 50 美元礼品卡奖励。该调查解释说,受访者的电子邮件将仅用于礼品卡目的,Algorithmia 通过确保受访者的答案与他们的电子邮件地址没有任何关联来保持调查的完整性。 |
Group B was sent to individuals who have engaged with Algorithmia in the past in various capacities (ie. attended a company webinar, read an internal whitepaper, met with our team at an industry trade show, etc.). The 442 respondents in this group voluntarily participated in the survey and represented a diverse sampling of industries, company sizes, ML maturity levels, and organizational structures and roles. The survey was conducted in two prongs to account for unintentional bias in either group. Where possible and appropriate, the researchers averaged Groups A and B for the most accurate readings and specified when one or both groups were represented in the text or in the graphs. All percentages were rounded to the nearest whole number. The 2020 State of Enterprise Machine Learning questionnaires (Groups A and B) were developed collaboratively by the Product and Marketing teams at Algorithmia. The teams identified the key issues to measure, determined critical survey questions, and provided feedback on the draft questionnaire. The survey was designed to be self-administered and completed online in an average of six minutes. We will continue to conduct this annual survey to increase the breadth of our understanding of machine learning technology in the enterprise and share with the broader industry how ML is evolving. In doing so,we can track trends in ML development across industries over time, ideally making more informed predictions with higher degrees of confidence. |
B 组被派发给过去曾以各种身份参与过 Algorithmia 的个人(即参加公司网络研讨会、阅读内部白皮书、在行业贸易展上与我们的团队会面等)。该组中的 442 名受访者自愿参与了调查,代表了来自行业、公司规模、机器学习成熟度水平以及组织结构和角色的不同样本。 该调查分两个方面进行,以说明任一组的无意偏见。在可能和适当的情况下,研究人员对 A 组和 B 组进行平均,以获得最准确的读数,并指定一个或两个组何时出现在文本或图表中。所有百分比均四舍五入至最接近的整数。 2020 年企业机器学习现状调查问卷(A 组和 B 组)由 Algorithmia 的产品和营销团队合作开发。团队确定了要衡量的关键问题,确定了关键的调查问题,并就问卷草案提供了反馈。该调查旨在自我管理并在平均六分钟内在线完成。 我们将继续开展这项年度调查,以扩大我们对企业机器学习技术的理解,并与更广泛的行业分享 ML 的发展历程。通过这样做,我们可以随着时间的推移跟踪跨行业的 ML 发展趋势,理想情况下做出更明智的预测,并具有更高的置信度。 |
About Algorithmia
Algorithmia is a leader in the machine learning space. We aim to empower every organization to achieve its full potential through the use of artificial intelligence and machine learning by delivering the last-mile solution for model deployment at scale. Our technology is trusted by more than 100,000 developers, Fortune 100 financial institutions, government intelligence agencies, and private companies. Algorithmia enables customers to: (1)、Deploy models from a variety of frameworks, languages, and platforms (2)、Connect popular data sources, orchestration engines, and step functions (3)、Scale model inference on multiple infrastructure providers (4)、Manage the ML lifecycle with tools to iterate, audit, secure, and govern To learn more about how Algorithmia can help your company accelerate its ML journey, visit our website at algorithmia.com. |
Algorithmia 是机器学习领域的领导者。 我们的目标是通过提供用于大规模模型部署的最后一英里解决方案,使每个组织都能够通过使用人工智能和机器学习来充分发挥其潜力。 我们的技术受到超过 100,000 名开发商、财富 100 强金融机构、政府情报机构和私营公司的信赖。 算法使客户能够: (1)、从多种框架、语言、平台部署模型 (2)、连接流行的数据源、编排引擎、step函数 (3)、对多个基础设施提供商的规模模型推断 (4)、使用迭代、审计、保护和治理工具管理 ML 生命周期 要详细了解 Algorithmia 如何帮助您的公司加速其 ML 之旅,请访问我们的网站 algorithmia.com。 |
About the cover
The cover image is a parallel set chart—similar to a Sankey diagram. Each line-set represents a specific data category. The width of each line-set’s path is determined by the proportional amount of the category total. The line-set on the left depicts the different industries that our survey participants come from. The line-set on the right of the diagram displays the machine learning maturity level of our respondents’ companies. Reflects data only from survey Group B. |
封面图片是一个平行集图——类似于桑基图。 每个行集代表一个特定的数据类别。 每个线集路径的宽度由类别总数的比例决定。 左侧的线条描绘了我们的调查参与者来自的不同行业。 图右侧的线组显示了受访公司的机器学习成熟度水平。 仅反映来自调查组 B 的数据。 |
