基本概念
解决问题
如何存储大量数据?
如何处理大量数据?
常用平台
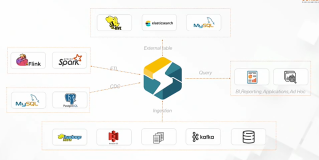
E-MapReduce(简称“EMR”)是云原生开源大数据平台,向客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、Clickhouse、Delta、Hudi等开源大数据计算和存储引擎。EMR计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK、专有云平台。
产品优势
| 对比维度 | EMR | 自建Hadoop |
| 成本 | 资源按量付费,支持集群资源灵活调整,数据分层存储,资源使用率高。无额外软件License费用。 | 提前预估资源,且资源相对固定,资源使用率低。采用Hadoop发行版,需额外支付License费用。 |
| 性能 | 较开源版本性能大幅提升,如EMR SparkSQL性能是开源版本6倍。 | 采用开源社区版本,性能需自行优化。 |
| 易用 | 分钟级别启动Hadoop集群,敏捷响应业务需求。 | 采购服务器,部署Hadoop生态组件,周期长达数周。 |
| 弹性 | 可根据作业临时启动和销毁集群。集群资源可根据时间周期或集群负载动态自动调整。基于JindoFS计算存储分离架构,轻松分别扩展计算和存储资源。 | 计算和存储耦合,资源相对固定,无法弹性调整资源。 |
| 安全 | 支持企业级多租户资源管理能力,支持对表、列、行级别的权限控制和日志审计,支持数据加密。 | 多租户管理能力需自行配置,能力不完善,无法满足企业级需求。 |
| 可靠 | 大规模、企业级环境的检验,随开源版本升级,并经过专业的兼容性验证测试,提供优于社区版本的使用体验。 | 需自行更新和升级开源版本,验证各组件版本兼容性,自行修复社区bug。 |
| 服务 | 专业和资深大数据专家技术服务团队提供售后支持。 | 社区版本无服务支持,Hadoop发行版,需额外支付License和服务费用。 |
配置流程
以下流程来源与阿里云官网,链接https://developer.aliyun.com/adc/scenario/exp/175735954e19429cbb753cd547c00b5a
本步骤将指导您如何登录EMR集群终端。
1. 在远程桌面中点击Firefox ESR,会自动弹出分配子账号的登录页面,点击下一步,从左侧复制子用户密码,粘贴(温馨提示:粘贴快捷键为CTRL+V)到输入框



2. 登录成功后进入阿里云控制台首页,点击左侧菜单,输入关键词“emr”,点击E-MapReduce进入管理页面。

3.在E-MapReduce控制台页面上方,选择资源所在地域。例如下图中,地域切换为华东2(上海)。
说明:您可以在云产品资源列表中查看到您的E-MapReduce资源所在地域。

4.在E-MapReduce控制台页面的集群列表区域,单击您的集群名/ID。
说明:您可以在云产品资源列表中查看到您的E-MapReduce集群名/ID。

5.集群基础信息页面的主机信息区域,复制MASTER的节点的公网ip地址。

6. 打开远程桌面终端LxShell

7. 在终端中输入连接命令ssh root@[ipaddress]。您需要将[ipaddress]替换成第3步中复制公网地址,例如:
ssh root@139.xxx.xxx.230
命令显示结果如下:

8. 输入 yes。
9. 同意继续后将会提示输入登录密码。密码为@Aliyun2021(你可以使用粘贴快捷键SHIFT+CTRL+V)。
说明:输入密码的过程中没有回显,请确保键入内容正确。

登录成功后会显示如下信息。