第二章 MongoDB查看指令
test:登录时默认存在的库
admin库:系统预留库,MongoDB系统管理库
local库:本地预留库,存储关键日志
config库:MongoDB配置信息库
查看数据库命令
show databases/show dbs
show tables/show collections
use admin
db/select database()
一:插入命令
1.插入单条
db.user_info.insert({"name":"SATA","age":27,"ad":"北京市朝阳区"})
db.user_info.insert({"name":"HU","age":27,"ad":"北京市朝阳区"})
db.user_info.insert({"name":"GANG","age":28,"ad":"北京市朝阳区"})
db.user_info.insert({"name":"MA","age":28,"ad":"北京市朝阳区"})
db.user_info.insert({"name":"YI","age":28,"ad":"北京市朝阳区","sex":"待定"})2.插入多条
db.inventory.insertMany([
{ "item": "journal", "qty": 25, "size": { "h": 14, "w": 21, "uom": "cm" }, "status": "A" },
{ "item": "notebook", "qty": 50, "size": { "h": 8.5, "w": 11, "uom": "in" }, "status": "A" },
{ "item": "paper", "qty": 100, "size": { "h": 8.5, "w": 11, "uom": "in" }, "status": "D" },
{ "item": "planner", "qty": 75, "size": { "h": 22.85, "w": 30, "uom": "cm" }, "status": "D" },
{ "item": "postcard", "qty": 45, "size": { "h": 10, "w": 15.25, "uom": "cm" }, "status": "A" }
]);二:mongoDB 查询命令
1.查询一条
db.user_info.findOne()2.查询所有
db.user_info.find()3.查询符合条件
db.user_info.find({"age":28})
select * from user_info where age = 28;4.查询嵌套的条件
db.inventory.find( { "size.uom": "in" } )
db.inventory.find(
{
"size.uom": "in"
}
)
5.逻辑查询:and
db.inventory.find( { "size.uom": "cm" ,"status" : "A"} )
db.inventory.find(
{
"size.uom": "cm" ,
"status" : "A"
}
)6.逻辑查询 或
db.inventory.find(
{
$or:[
{status:"D"},
{qty:{$lt:30}
]
}
)7.逻辑查询+或+and+正则表达式
db.inventory.find({status:"A",$or:[{qty:{$lt:30}},{item:/^p/}]})
db.inventory.find(
{
status: "A",
$or: [
{ qty: { $lt: 30 } },
{ item: /^p/ }
]
}
)
db.inventory.find(
{
status: "A",
$or: [
{ qty: { $gt: 30 } },
{ item: /^p/ }
]
}
)三:mongoDB更新数据
1.更改匹配条件的单条数据
db.inventory.find({ "item" : "paper" })
db.inventory.updateOne({ "item" : "paper" },{$set: { "size.uom" : "cm", "status" : "P" }})
db.inventory.updateOne(
{ "item" : "paper" },
{
$set: {
"size.uom" : "cm",
"status" : "P"
}
}
)2.更改匹配条件的多条数据
db.inventory.find({ "qty" : { $lt: 50 } })
db.inventory.updateMany(
{ "qty" : { $lt: 50 } },
{
$set:
{
"size.uom" : "mm",
"status": "P"
}
}
)3.添加字段
db.user_info.find({ "age" : 27})
db.user_info.updateMany(
{ "age" : 27},
{
$set:
{
"pet" : "cat"
}
}
)四:mongoDB删除
1.先查找需要删除的数据
db.inventory.find({"status":"P"})2.删除单条
db.inventory.deleteOne({"status":"P"})3.删除多个
db.inventory.deleteMany({"status":"P"})4.删除索引
db.user_info.dropIndex("age_1")4.删除集合
show dbs
db
show tables
db.inventory.drop()5.删除库
show dbs
db
db.dropDatabase()五:mongoDB的索引
1.查看执行计划
db.user_info.find({"age":{ $lt: 30 }})
db.user_info.find({"age":{ $lt: 30 }}).explain()2.创建索引
db.user_info.createIndex({ age: 1 },{background: true})参数说明:
age:1 表示对age字段作为索引的字段,1表示排序规则为升序,-1表示为降序
background 表示放在后台创建,不影响读写
3.查看索引
db.user_info.getIndexes()
4.再次查看执行计划
db.user_info.find({"age":{ $lt: 30 }}).explain()关键词
"stage" : "IXSCAN"
"indexName" : "age_1"5.删除索引
db.user_info.dropIndex("age_1")索引类型
COLLSCAN - 表示查询的字段并没有建立索引,所以查询的时候会使用全表扫描
IXSCAN – 表示使用索引来找出对应的文档
六:mongoDB的工具
0.命令介绍
mongod #启动命令
mongo #登录命令
mongodump #备份导出,全备压缩
mongorestore #恢复
mongoexport #备份,数据可读json
mongoimport #恢复
mongostat #查看mongo运行状态
mongotop #查看mongo运行状态
mongos #集群分片命令1.mongostat
各字段解释说明:
insert/s : 官方解释是每秒插入数据库的对象数量,如果是slave,则数值前有*,则表示复制集操作
query/s : 每秒的查询操作次数
update/s : 每秒的更新操作次数
delete/s : 每秒的删除操作次数
getmore/s: 每秒查询cursor(游标)时的getmore操作数
command: 每秒执行的命令数,在主从系统中会显示两个值(例如 3|0),分表代表 本地|复制 命令
注: 一秒内执行的命令数比如批量插入,只认为是一条命令(所以意义应该不大)
dirty: 仅仅针对WiredTiger引擎,官网解释是脏数据字节的缓存百分比
used: 仅仅针对WiredTiger引擎,官网解释是正在使用中的缓存百分比
flushes:
For WiredTiger引擎:指checkpoint的触发次数在一个轮询间隔期间
For MMAPv1 引擎:每秒执行fsync将数据写入硬盘的次数
注:一般都是0,间断性会是1, 通过计算两个1之间的间隔时间,可以大致了解多长时间flush一次。flush开销是很大的,如果频繁的flush,可能就要找找原因了
vsize: 虚拟内存使用量,单位MB (这是 在mongostat 最后一次调用的总数据)
res: 物理内存使用量,单位MB (这是 在mongostat 最后一次调用的总数据)
注:这个和你用top看到的一样, vsize一般不会有大的变动, res会慢慢的上升,如果res经常突然下降,去查查是否有别的程序狂吃内存。
qr: 客户端等待从MongoDB实例读数据的队列长度
qw:客户端等待从MongoDB实例写入数据的队列长度
ar: 执行读操作的活跃客户端数量
aw: 执行写操作的活客户端数量
注:如果这两个数值很大,那么就是DB被堵住了,DB的处理速度不及请求速度。看看是否有开销很大的慢查询。如果查询一切正常,确实是负载很大,就需要加机器了
netIn:MongoDB实例的网络进流量
netOut:MongoDB实例的网络出流量
注:此两项字段表名网络带宽压力,一般情况下,不会成为瓶颈
conn: 打开连接的总数,是qr,qw,ar,aw的总和
注:MongoDB为每一个连接创建一个线程,线程的创建与释放也会有开销,所以尽量要适当配置连接数的启动参数,maxIncomingConnections,阿里工程师建议在5000以下,基本满足多数场景
七:mongoDB的权限和认证
创建用户和角色
0.与用户相关的命令
db.auth() 将用户验证到数据库。
db.changeUserPassword() 更改现有用户的密码。
db.createUser() 创建一个新用户。
db.dropUser() 删除单个用户。
db.dropAllUsers() 删除与数据库关联的所有用户。
db.getUser() 返回有关指定用户的信息。
db.getUsers() 返回有关与数据库关联的所有用户的信息。
db.grantRolesToUser() 授予用户角色及其特权。
db.removeUser() 已过时。从数据库中删除用户。
db.revokeRolesFromUser() 从用户中删除角色。
db.updateUser() 更新用户数据。1.创建管理用户
mongo db01:27017
use admin
db.createUser(
{
user: "admin",
pwd: "31huiyi.com",
roles:[
{
role: "root",
db:"admin"
}
]
}
)2.查看创建的用户
db.getUsers()
3.配置文件添加权限认证参数
security:
authorization: enabled4.重启mongo
mongod -f /opt/mongo_27017/conf/mongodb.conf --shutdown
mongod -f /opt/mongo_27017/conf/mongodb.conf5.使用admin用户登录
mongo db01:27017 -uadmin -p --authenticationDatabase admin6.创建其他用户
use test
db.createUser(
{
user: "mysun",
pwd: "123456",
roles: [ { role: "readWrite", db: "write" },
{ role: "read", db: "read" } ]
}
)7.创建测试数据
use write
db.write.insert({"name":"zhangya","age":27,"ad":"北京市朝阳区"})
db.write.insert({"name":"zhangya","age":27,"ad":"北京市朝阳区"})
db.write.insert({"name":"yazhang","age":28,"ad":"北京市朝阳区"})
db.write.insert({"name":"xiaozhang","age":28,"ad":"北京市朝阳区"})
db.write.insert({"name":"xiaozhang","age":28,"ad":"北京市朝阳区","sex":"boy"})
use read
db.read.insert({"name":"zhangya","age":27,"ad":"北京市朝阳区"})
db.read.insert({"name":"zhangya","age":27,"ad":"北京市朝阳区"})
db.read.insert({"name":"yazhang","age":28,"ad":"北京市朝阳区"})
db.read.insert({"name":"xiaozhang","age":28,"ad":"北京市朝阳区"})
db.read.insert({"name":"xiaozhang","age":28,"ad":"北京市朝阳区","sex":"boy"})8.退出admin,使用mysun用户登录
mongo db01:27017 -umysun -p --authenticationDatabase test
use write
db.write.find()
db.write.insert({"name":"zhangya","age":27,"ad":"北京市朝阳区"})
use read
db.read.find()
db.read.insert({"name":"zhangya","age":27,"ad":"北京市朝阳区"})9.修改用户权限
use test
db.updateUser(
'mysun',
{
pwd: "123456",
roles: [ { role: "readWrite", db: "write" },
{ role: "readWrite", db: "read" } ,
{ role: "readWrite", db: "test" }
]
}
)10.删除用户
db.getUsers()
db.dropUser('mysun')八:mongoDB的副本集配置(重要)
副本集
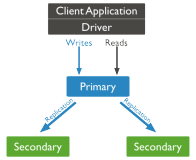
官方认为至少要三台节点才可以做副本集,主节点提供读写,从库只负责读 ,但是和MYSQL主从不一样,MongoDB的副本集每个节点都知道对方的信息情况,假如主节点宕机,那么在副本集集群中就会依据大多数投票选举来进行,然后再比较数据的新旧来确定新的主节点,比如三个节点挂掉一台剩下两台依旧满足大多数,从库自动指向新的主库,而原来宕机的主节点变为从节点,重新指向新的主节点,集群还是正常的。
仲裁节点
MongoDB中除了master,slave节点,还有一个仲裁节点Arbiter,比如现在只有两台服务器,按之前的做法副本集是不可行的,最少三台,但是Arbiter节点的出现两台服务器也可以实现,Arbiter节点只负责投票,不存储也不处理数据,几乎不消耗资源,并且永远不会抢占master,在两台中的任何一台上起一个Arbiter实例,物理上是两台,但是逻辑上有三台,副本集也可以搭建。实验环境采用一台多实例进行的
1.创建节点目录和数据目录
systemctl stop mongod #关闭原来的测试MongoDB
mkdir -p /opt/mongo_2801{7,8,9}/{conf,log,pid}
mkdir -p /data/mongo_2801{7,8,9}2.创建配置文件
vim /opt/mongo_28017/conf/mongo_28017.conf
systemLog:
destination: file
logAppend: true
path: /opt/mongo_28017/log/mongodb.log
storage:
journal:
enabled: true
dbPath: /data/mongo_28017
directoryPerDB: true
wiredTiger:
engineConfig:
cacheSizeGB: 0.5
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
processManagement:
fork: true
pidFilePath: /opt/mongo_28017/pid/mongod.pid
net:
port: 28017
bindIp: 127.0.0.1,10.0.0.51
replication: #该节点是以副本级启动的
oplogSizeMB: 1024 #相当于MYSQL的binlog,指定记录日志的大小为1G
replSetName: dba #在一个组中启动,名叫dba3.复制配置文件到其他节点
cp /opt/mongo_28017/conf/mongo_28017.conf /opt/mongo_28018/conf/mongo_28018.conf
cp /opt/mongo_28017/conf/mongo_28017.conf /opt/mongo_28019/conf/mongo_28019.conf4.替换端口号
sed -i 's#28017#28018#g' /opt/mongo_28018/conf/mongo_28018.conf
sed -i 's#28017#28019#g' /opt/mongo_28019/conf/mongo_28019.conf5.启动所有节点
mongod -f /opt/mongo_28017/conf/mongo_28017.conf
mongod -f /opt/mongo_28018/conf/mongo_28018.conf
mongod -f /opt/mongo_28019/conf/mongo_28019.conf6.初始化集群,一定要在主节点上初始化
mongo 10.0.0.51:28019 #指定端口来进入MongoDB实例config = {
_id : "dba",
members : [
{_id : 0, host : "192.168.15.253:27017"},
{_id : 1, host : "192.168.15.248:27017"},
{_id : 2, host : "192.168.15.247:27017"},
]}
rs.initiate(config)7.插入数据测试,看看从节点能不能同步
db.inventory.insertMany( [
{ "item": "journal", "qty": 25, "size": { "h": 14, "w": 21, "uom": "cm" }, "status": "A" },
{ "item": "notebook", "qty": 50, "size": { "h": 8.5, "w": 11, "uom": "in" }, "status": "A" },
{ "item": "paper", "qty": 100, "size": { "h": 8.5, "w": 11, "uom": "in" }, "status": "D" },
{ "item": "planner", "qty": 75, "size": { "h": 22.85, "w": 30, "uom": "cm" }, "status": "D" },
{ "item": "postcard", "qty": 45, "size": { "h": 10, "w": 15.25, "uom": "cm" }, "status": "A" }
]);8.副本节点登录查看数据,默认刚开始进去不能读取,需要指定rs.slaveok()参数
rs.slaveOk()
use test
db.inventory.find()9.设置副本可读
方法1:临时生效
rs.slaveOk()
方法2:写入启动文件,永久生效
echo "rs.slaveOk()" > /root/.mongorc.js九:mongoDB的副本集权重调整
0.模拟故障转移
mongod -f /opt/mongo_28017/conf/mongo_28017.conf --shutdown
mongod -f /opt/mongo_28017/conf/mongo_28017.conf1.查看当前副本集配置
rs.conf()
2.设置权重(权重越大,优先级越高)
rs.conf() #查看当前副本集的优先级
config=rs.conf() #将当前配置信息导入到变量中保存
config.members[0].priority=100 #0代表节点的编号,将编号为0的节点权重改为100
rs.reconfig(config) #重新载入配置信息3.恢复成默认的权重,以便后面不影响主节点的选举
config=rs.conf()
config.members[0].priority=1 #毁尸灭迹
rs.reconfig(config)
rs.conf() #查看4.主节点主动降级,用于比如需要停机维护,未宕机,只是放弃竞选主节点,其他节点继续竞选
rs.stepDown() #执行完就变成从节点,主动放弃rs.status()查看副本集详细信息5:但是有一个问题,那么正常业务的代码怎么才可以连接到这个集群呢?
先来说一下,所有rs开头的命令都是和副本级相关的
rs.isMaster() #查看谁是主节点[10.0.0.51:28017,10.0.0.52:28018,10.0.0.53:28019] #MongoDB的集群会将地址全部写在一个集合中,由程序去统一调用,程序会先rs.isMaster()执行查看谁是master,知道后程序再去连接这个master,如果这个master宕机,只要集群还能正常工作,那么就会继续选取重新连接!十:mongoDB增加新节点和删除旧节点(扩容和缩减)
但凡是集群,都有扩容和收缩集群的需要,注意,在没有仲裁节点之前,3台机器构成的集群只能坏一台,4台机器在没有仲裁节点之前,也是只能坏一台,如果坏掉两台就不满足成员大多数,即不能坏掉只剩两台
1.创建新节点并启动
mkdir -p /opt/mongo_28010/{conf,log,pid}
mkdir -p /data/mongo_28010
cp /opt/mongo_28017/conf/mongo_28017.conf /opt/mongo_28010/conf/mongo_28010.conf
sed -i 's#28017#28010#g' /opt/mongo_28010/conf/mongo_28010.conf
mongod -f /opt/mongo_28010/conf/mongo_28010.conf
mongo db01:28010 #登录新的节点2.集群添加节点,一定是在主节点上添加,并且新添加的节点不需要初始化,直接添加使用
mongo 10.0.0.51:28017 #登录主节点
use admin
rs.add("10.0.0.51:28010") #在主节点上执行该命令,将新的节点加入到集群中。3.新节点查看信息
mongo db01:28010 #这里的db01已经在/etc/hosts里面做了解析了3.删除节点
rs.remove("db01:28010")
rs.remove("db01:28011")十一:mongoDB的仲裁节点
为了解决在最少的机器使用前提下,尽量减少宕机数量带来的危险情况。
1.不存储数据也不处理数据
2.只负责投票
3.永远不会抢占master角色
4.不消耗太多资源
仲裁节点的加入,使得从之前的四个节点集群最多坏一台减小到坏两台
1.创建新节点并启动
mkdir -p /opt/mongo_28011/{conf,log,pid}
mkdir -p /data/mongo_28011
cp /opt/mongo_28017/conf/mongo_28017.conf /opt/mongo_28011/conf/mongo_28011.conf
sed -i 's#28017#28011#g' /opt/mongo_28011/conf/mongo_28011.conf
mongod -f /opt/mongo_28011/conf/mongo_28011.conf
mongo db01:280112.将仲裁节点加入集群
rs.addArb("192.168.15.247:27017")