项目空间
• 项目空间(Project)是MaxCompute的基本组织单元,类似于传统数据库的DataBase或Schema的概念,是进行多用户隔离和访问控制的主要边界。项目空间中包含多个对象,例如表(Table)、资源(Resource)、函数(Function)和实例(Instance)等。
• 一个用户可以同时拥有多个项目空间的权限。通过安全授权,可以跨项目空间访问对象。
• 通过在MaxCompute客户端中运行use
project命令进入一个项目空间。
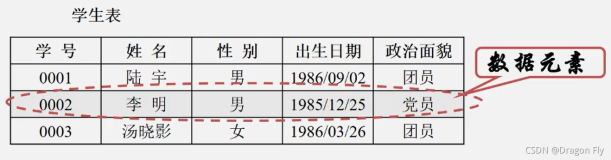
表
• 表是MaxCompute的数据存储单元,逻辑上是二维结构,MaxCompute中不同类型计算任务的操作对象(输入、输出)都是表。
• MaxCompute的表分为内部表和外部表(2.0版本开始支持)。
• 对于内部表,所有的数据都被存储在MaxCompute中。
• 对于外部表,MaxCompute并不真正持有数据,表格的数据可以存放在OSS或OTS中,MaxCompute仅会记录表格的Meta信息,OSS上的信息可以是非结构化的,例如视频、音频等。
• MaxCompute与Oracle等数据库不同,系统并不会自动创建dual表。
分区
• 分区表是指在创建表时指定分区空间,即指定表内的一个或某几个字段作为分区列。分区表实际就是对应分布式文件系统上的独立文件夹,该文件夹下是该分区的所有数据文件。
• 分区表的意义在于优化查询。查询表时通过where子句查询指定分区,避免全表扫描。
• MaxCompute将分区列的每个值作为一个分区,同时也可以指定多级分区,即将表的多个字段作为表的分区,如多级目录的关系。
• MaxCompute
2.0支持字段类型为TINYINT、SMALLINT、INT、BIGINT、VARCHAR、STRING的分区,虽然可以指定分区类型为BIGINT,但是除了表的字段表示为BIGINT,任何其他情况实际都被处理为STRING。建议使用STRING。
分区使用限制
• 单表分区层级最多为6级。
• 单表分区数最多允许60000个分区。
• 单词查询允许查询的最多分区个数为10000个。
• STRING分区类型的分区值不支持使用中文。
错误的分区使用方式:
select * from src where pt=20170601;
在这样的使用方式下,MaxCompute并不能保障分区过滤机制的有效性。pt是STRING类型,当STRING类型与BIGINT(20170601)比较时,MaxCompute会将二者转换为DOUBLE类型,此时有可能会有精度损失。
生命周期
MaxCompute表的生命周期(Lifecycle),指表(分区)数据从最后一次更新的时间算起,在经过指定的时间后没有变动,则此表(分区)将被MaxCompute自动回收,这个指定的时间就是生命周期。
• 生命周期单位:Days(天),只接受正整数。
• 对于非分区表,如果表数据在生命周期内没有被修改,生命周期结束时,此表将会被MaxCompute自动回收(类似drop table),生命周期从最后一次表数据被修改的时间(LastDataModifiedTime)起进行计算。
• 对于分区表,每个分区可以分别被回收,在生命周期内数据未被修改的分区,经过指定的天数后,此分区将会被回收,否则会被保留。同理,生命周期是从最后一次分区数据被修改的时间起进行计算。不同于非分区表的是,分区表的最后一个分区被回收后,该表不会被删除。
• 生命周期回收为每天定时启动,扫描所有分区,只有被扫描时发现分区/表超过生命周期的指定时间,分区/表才会被回收。
• 生命周期只能设定到表级别,不能设定到分区级,创建表时即可指定生命周期。
资源
资源(Resource)是MaxCompute的特有概念,如果需要使用UDF、MapReduce,读取第三方库等,都需要依赖资源来完成,如下所示:
• SQL UDF:编写UDF时,需要将编译好的jar包或编写好的Python UDF脚本文件以资源的形式上传到MaxCompute,运行UDF时,MaxCompute会自动下载jar包或python脚本来运行UDF。
• MapReduce:编写MapReduce程序后,将编译好的jar包上传到MaxCompute,运行MapReduce作业时,MapReduce框架会自动下载这个资源从而获取代码。
• MaxCompute支持上传的单个资源大小上限为500MB,资源包括File类型、Table类型、Jar类型和Archive类型。
函数
MaxCompute提供了内建函数与自定义函数,自定义函数分为标量值函数(UDF)、自定义聚合函数(UDAF)和自定义表值函数(UDTF)。
• UDF
广义的UDF代表自定义标量函数、自定义聚合函数及自定义表函数三种类型的自定义函数的集合。狭义的UDF指用户自定义标量值函数,即读入一行数据,写出一条输出。
• UDAF
自定义聚合函数,即多条输入记录聚合成一条输出值,可以与SQL中的GROUP BY语句联用。
• UDTF
自定义表值函数,输入多个字段,返回多个字段,逐行记录进行处理。简单的说,UDF是特殊的UDTF。
任务
任务(Task)是MaxCompute的基本计算单元,对于计算型任务,例如SQL、MapReduce,MaxCompute会对其进行解析,得出任务的执行计划,执行计划由具有依赖关系的多个执行阶段(Stage)构成。
• 执行计划逻辑上可以被看做一个有向无环图,图中的点是执行阶段,各个执行阶段的依赖关系是图的边。MaxCompute会依照图(执行计划)中的依赖关系执行各个阶段。在同一个执行阶段内,会有多个进程,也称之为Worker,共同完成该执行阶段的计算工作。同一个执行阶段的不同Worker只是处理的数据不同,执行逻辑完全相同。计算型任务在执行时,会被实例化。
• 另一方面,部分MaxCompute任务并不是计算型的任务,例如SQL中的DDL语句,这些任务本质上仅需要读取、修改MaxCompute中的元数据信息,因此这些任务无法被解析出执行计划。
任务实例
在MaxCompute中,部分任务在执行时会被实例化,任务实例会经历运行(Running)和结束(Terminated)两个阶段。运行阶段的状态为Running,而结束阶段会有Success、Failed、Canceled三种状态。
ACID语义
相关术语
• 操作:指在MaxCompute上提交的单个作业。
• 数据对象:指持有实际数据的对象,例如非分区表、分区。
• INTO类作业:INSERT INTO、DYNAMIC INSERT INTO等。
• OVERWRITE类作业:INSERT OVERWRITE、DYNAMIC INSERT OVERWRITE等。
• Tunnel数据上传:可以归结为INTO类或OVERWRITE类作业。
ACID语义描述
• 原子性(Atomicity):一个操作或是全部完成,或是全部不完成,不会结束在中间某个环节。
• 一致性(Consistency):从操作开始至结束的期间,数据对象的完整性没有被破坏。
• 隔离性(Isolation):操作独立于其它并发操作完成。
• 持久性(Durabillity):操作处理结束后,对数据的修改将永久有效,即使出现系统故障,该修改也不会丢失。
MaxCompute的ACID具体情形
• 原子性(Atomicity)
• 任何时候MaxCompute会保证在冲突时只会有一个作业成功,其它冲突作业失败。
• 对于单个表/分区的CREATE/OVERWRITE/DROP操作,可以保证其原子性。
• 跨表操作时不支持原子性(例如MULTI-INSERT)。
• 在极端情况下,以下操作可能不保证原子性:
• DYNAMIC INSERT OVERWRITE多于一万个分区,不支持原子性。
• INTO类操作:事务回滚时会有数据清理失败。
• 一致性(Consistency)
• OVERWRITE类作业可保证一致性。
• INTO类作业在冲突失败后可能存在失败作业的数据残留。
• 隔离性(Isolation)
• 非INTO类操作保证读已提交。
• INTO类操作存在读未提交的场景。
• 持久性(Durability)
• MaxCompute保证数据的持久性。