title: MySQL · myrocks · myrocks crash safe 特性
author: 张远
crash safe 定义
在主备环境下,实例mysqld crash或机器宕机是常见的事情,而如何快速而安全的从异常中恢复,对高可用来说是非常重要的。常见的恢复方法是从备份集来恢复实例,重建复制关系,这种做法是安全的但一般耗时较长。另外一种方法就是等异常实例恢复,直接启动异常实例来恢复复制关系,这种做法快速但不一定是安全的,下节会详细介绍原因。
crash safe就是指在异常实例恢复后,直接启动异常实例来恢复复制关系,并且保证数据是一致的。
myrocks 是crash safe的。
不一致原因
分为主库异常恢复和备库异常恢复两种情况,这两种情况都可能出现不一致的情况。
主库异常
在myrocks主备环境是开启了loss-less semisync(AFTER-SYNC模式),并且主库sync_binlog=1,innodb_flush_log_at_trx_commit=1(双1模式)。在这种情况下,主库是在sync binlog 之后,engine commit之前等待备库的ACK, 因此主库crash时,主库可能存在部分binlog已经落盘但engine层没有提交,并且这些binlog也没有即时发送到备库的情况。

这部分binlog 实际上就是比备库多出来的binlog,而主库启动恢复这部分binlog所在事务是处于prepare状态的,根据binlog XA协议,这部分事务最终会提交。从而,主库比备库会多一些事物,导致不一致。
备库异常
为了加快复制速度,备库一般会设置sync_binlog!=1,innodb_flush_log_at_trx_commit!=1(非双1模式)。这种设置,备库可能出现两种情况:
- binlog落后于engine层,也就是存在engine 层提交了但binlog没有落盘的情况。
- binlog超前于engine层,也就是存在binlog落盘了但engine层没有提交(非prepare)的情况。
在这两种情况下直接启动备库,重建复制关系都可能导致主备不一致。
engine层的binlog信息
讨论myrocks如何做到crash safe之前,我们先熟悉下以下背景知识。
engine 层提交时会保存binlog位点信息。
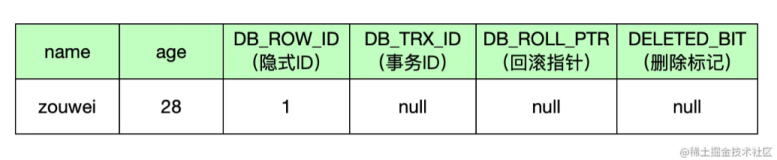
对于innodb, 每次提交时会在系统事务页(第5页)存储binlog 位点和gtid,参考trx_sys_update_mysql_binlog_offset
#define TRX_SYS_MYSQL_LOG_OFFSET_HIGH 4 /*!< high 4 bytes of the offset within that file */
#define TRX_SYS_MYSQL_LOG_OFFSET_LOW 8 /*!< low 4 bytes of the offset within that file */
#define TRX_SYS_MYSQL_LOG_NAME 12 /*!< MySQL log file name */
#define TRX_SYS_MYSQL_GTID (TRX_SYS_MYSQL_LOG_NAME + TRX_SYS_MYSQL_LOG_NAME_LEN)对于rocksdb,每次提交时会在数据字典BINLOG_INFO_INDEX_NUMBER中存储binlog 位点和gtid, 参考Rdb_binlog_manager::update
BINLOG_INFO_INDEX_NUMBER
key: Rdb_key_def::BINLOG_INFO_INDEX_NUMBER (0x4)
value: version, {binlog_name,binlog_pos,binlog_gtid}master crash safe
myrocks可以做到主库crash safe。前面讲过如果直接启动主库,多出来的那部分binlog可能导致不一致。如果我们能够把这部分binlog去掉,那么启动时,prepare的事务就可以回滚了,从而主备又可以一致了。事实上facebook就是这样做的,主库crash时,备库io线程会终止,同时会在errorlog中记录拉取主库binlog的位点信息。取到这位点后,将主库的binlog从此位点truncate掉。
以下图片来自facebook
主库crash
truncate binlog 后
前面提到engine层也保存了位点信息,那么我们为什么不使用这个位点,而是从备库errorlog中获取呢。
engine层位点前的事务在engine 层都是已提交的。
主库crash时,prepare的事务的binlog有可能部分传到了备库,而这些prepare的事务重启动时是应该提交的。而如果用engine层位点来truncate binlog会导致这部分事务回滚。
因此,从备库获取的位点信息才是准确的。
slave crash safe
myrocks可以做到备库库crash safe,这里需考虑两种情况
- binlog落后于engine层,也就是存在engine 层提交了但binlog没有落盘的情况。
针对此种情况,Facebook mysql增加了新的系统表专门保存每个db最后提交的gtid信息。之所以保存的是db的gtid信息,是因为并行复制还是库级别并发的,不得不吐槽下。
CREATE TABLE `slave_gtid_info` (
`Id` int(10) unsigned NOT NULL,
`Database_name` varchar(64) NOT NULL,
`Last_gtid` varchar(56)DEFAULT NULL,
PRIMARY KEY (`Id`)
) DEFAULT CHARSET=utf8 STATS_PERSISTENT=0此gtid信息,在每个事务提交时都会更新。
备库启动时,这部分未落盘事务会重新拉取部分到备库apply, sql线程apply的过程中会根据系统表中的gtid信息来判断此gtid是否应该跳过,这些需跳过的事务只需要记录binlog不需要真正执行。参考Gtid_info::skip_event .
- binlog超前于engine层,也就是存在binlog落盘了但engine层没有提交(非prepare)的情况。
实例启动时gtid_executed是从binlog中读取的。对于此种情况,先从engine层读取位点信息,更新gtid_executed信息时只读取binlog的到此位点,然后rotate binlog,用新的gtid_executed信息重新拉取binlog就不会不一致了。参考read_gtids_from_binlog。
slave_gtid_info表优化
每个事务提交时都要更新slave_gtid_info表。最初的时候,这个操作是server层提交时由server层更新slave_gtid_info表,后来将这个操作下沉到engine直接由engine层来执行。从而省去了server层接口调用的开销,这个优化对于rocksdb insert 场景有30%左右的提升。详情参考这里。不过,如果需要混用innodb和rocksdb,建议禁用此优化。
关于gtid_execute表
mysql5.7已经支持gtid_executed表(myrocks是基于mysql5.6的), 结构如下
CREATE TABLE `gtid_executed` (
`source_uuid` char(36) NOT NULL COMMENT 'uuid of the source where the transaction was originally executed.',
`interval_start` bigint(20) NOT NULL COMMENT 'First number of interval.',
`interval_end` bigint(20) NOT NULL COMMENT 'Last number of interval.',
PRIMARY KEY (`source_uuid`,`interval_start`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 STATS_PERSISTENT=0此表保存了所有已执行的gtid信息,与slave_gtid_info不同,slave_gtid_info只是保存了每个db最后执行的gtid信息。如果将slave_gtid_info换成gtid_executed表,整个代码逻辑将更加清晰,同时gtid_executed表对以后支持表级或事务级的并行复制来说更加便利。
总结
myrocks的crash safe 特性可以帮助我们快速安全的恢复实例,重新建立复制关系,恢复高可用。crash safe 可以解决大多数主备环境下由于实例crash导致的主备不一致问题。然而,前面提到的主库crash safe是在semisync没有退化为异步的情况下才成立,要想真正的做到高可用,可使用mysql5.7.17刚GA的group replication 特性。当然,myrocks理论上也是支持group relication的,rocksdb只是mysql的一个engine而已。另外,业界已经有比较成熟的基于rocksdb的高可用分布式数据库,例如TiDB,cockroachDB。