
2018年9月13日笔记
0.检测tensorflow环境
安装tensorflow命令:pip install tensorflow
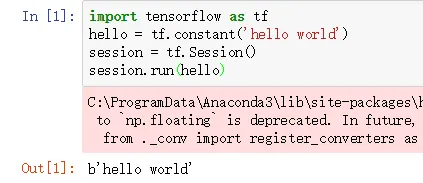
下面一段代码能够成功运行,则说明安装tensorflow环境成功。
import tensorflow as tf
hello = tf.constant('hello world')
session = tf.Session()
session.run(hello)
上面一段代码成功运行的结果如下图所示:
1.数据准备
从下图可以看出,变量a为1维的ndarray对象时,a[:, np.newaxis]与a.reshape(-1, 1)相同。

import numpy as np
X = np.linspace(-1, 1, 300)[:, np.newaxis].astype('float32')
noise = np.random.normal(0, 0.05, X.shape).astype('float32')
y = np.square(X) - 0.5 + noise
第1行代码导入numpy库,起别名np;
第3行代码调用np.linspace方法获得一个区间内的等间距点,例如np.linspace(0, 1, 11)是获取[0, 1]区间的11个等间距点。如下图所示:

第4行代码调用np.random.normal方法初始化符合正态分布的点,第1个参数是正态分布的均值,第2个参数是正态分布的方差,第3个参数是返回值的shape,返回值的数据类型为ndarray对象。
第5行代码调用np.square方法对X中的每一个值求平方,
- 0.5使用了ndarray对象的广播特性,最后加上噪声noise,将计算结果赋值给变量y。
2.搭建神经网络
import tensorflow as tf
Weights_1 = tf.Variable(tf.random_normal([1, 10]))
biases_1 = tf.Variable(tf.zeros([1, 10]) + 0.1)
Wx_plus_b_1 = tf.matmul(X, Weights_1) + biases_1
outputs_1 = tf.nn.relu(Wx_plus_b_1)
Weights_2 = tf.Variable(tf.random_normal([10, 1]))
biases_2 = tf.Variable(tf.zeros([1, 1]) + 0.1)
Wx_plus_b_2 = tf.matmul(outputs_1, Weights_2) + biases_2
outputs_2 = Wx_plus_b_2
loss = tf.reduce_mean(tf.square(y - outputs_2))
optimizer = tf.train.AdamOptimizer(0.1)
train = optimizer.minimize(loss)
第1行代码导入tensorflow库,起别名tf;
第3-6这4行代码定义神经网络中的输入层到第1隐层的连接;
第7-10这4行代码定义神经网络中的第1隐层到输出层的连接;
第3、7行代码定义Weights,它的形状是连接上一层神经元的个数*连接下一层神经元的个数;
第4、8行代码定义biases,它是二维矩阵,行数一直为1,列数为连接下一层神经元的个数,即它的形状为1*连接下一层神经元的个数;
第5、9行代码表示wx+b的计算结果;
第6行代码表示在第1个连接的输出结果,经过激活函数relu得出;
第10行代码表示在第2个连接的输出结果,因为此连接的下一层是输出层,所以不需要激活函数。
第11行代码定义损失函数,等同于回归预测中的MSE,中文叫做均方误差,数据类型如下图所示:

第12行代码调用tf.train库中的AdamOptimizer方法实例化优化器对象,数据类型如下图所示:

第13行代码调用优化器的minimize方法定义训练方式,参数为损失函数。方法的返回结果赋值给变量train,数据类型如下图所示:

3.变量初始化
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
对于神经网络模型,重要是其中的W、b这两个参数。
开始神经网络模型训练之前,这两个变量需要初始化。
第1行代码调用tf.global_variables_initializer实例化tensorflow中的Operation对象。
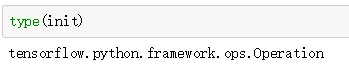
第2行代码调用tf.Session方法实例化会话对象;
第3行代码调用tf.Session对象的run方法做变量初始化。
4.模型训练
模型训练200次,每运行1次代码session.run(train)则模型训练1次。
在训练次数为20的整数倍时,打印训练步数、loss值。
for step in range(201):
session.run(train)
if step % 20 == 0:
print(step, 'loss:', session.run(loss))
上面一段代码的运行结果如下:
0 loss: 0.23739298
20 loss: 0.0074774586
40 loss: 0.0032493745
60 loss: 0.0026177235
80 loss: 0.0025075015
100 loss: 0.002472407
120 loss: 0.0024537172
140 loss: 0.002427246
160 loss: 0.002398049
180 loss: 0.002373801
200 loss: 0.002357695
5.完整代码
下面代码与前文相比,将搭建神经网络时重复定义Weights、biases的步骤封装成了函数。
import numpy as np
import tensorflow as tf
X = np.linspace(-1, 1, 300)[:, np.newaxis].astype('float32')
noise = np.random.normal(0, 0.05, X.shape).astype('float32')
y = np.square(X) - 0.5 + noise
def addConnect(inputs, in_size, out_size, activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if not activation_function:
return Wx_plus_b
else:
return activation_function(Wx_plus_b)
connect_1 = addConnect(X, 1, 10, tf.nn.relu)
predict_y = addConnect(connect_1, 10, 1)
loss = tf.reduce_mean(tf.square(y - predict_y))
optimizer = tf.train.AdamOptimizer(0.1)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
for step in range(201):
session.run(train)
if step % 20 == 0:
print(step, 'loss:', session.run(loss))
上面一段代码的运行结果如下:
0 loss: 0.28191957
20 loss: 0.011470509
40 loss: 0.0044303066
60 loss: 0.003392854
80 loss: 0.0031887146
100 loss: 0.0030761429
120 loss: 0.0029888747
140 loss: 0.0029117232
160 loss: 0.0028402375
180 loss: 0.0027794265
200 loss: 0.0027436544
6.可视化
前5节内容的可视化代码下载链接: https://pan.baidu.com/s/1AbkH8hFo7Pg1dbcNgdWhwg 密码: 99ku
在下载文件visualization.py的同级目录下打开cmd。
运行命令:python visualization.py
可视化部分截图:

7.结论
1.这是本文作者写的第2篇关于tensorflow的文章,加深了对tensorflow框架的理解;
2.本文是作者学习《周莫烦tensorflow视频教程》的成果,感激前辈;
视频链接:https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/
3.本文在周莫烦视频的基础上加入了自己的理解,add_layer函数修改为addConnect函数,本文作者认为更加贴切。










