1.构造选择器:
>>> response = HtmlResponse(url='http://example.com', body=body)
>>> Selector(response=response).xpath('//span/text()').extract()
[u'good']
2.使用选择器(在response使用xpath或CSS查询):
.xpath() 及 .css() 方法返回一个类 SelectorList 的实例, 它是一个新选择器的列表。
>>> response.xpath('//title/text()')
[<Selector (text) xpath=//title/text()>]
>>> response.css('title::text')
[<Selector (text) xpath=//title/text()>]
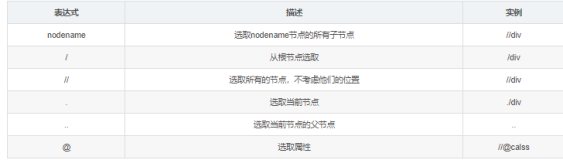
xpath中 //选取标签,/选择属性, CSS中用 :: 选取属性。
调用 extract() 来获取标签内容,使用extract_frist()来获取第一个元素内容。
>>> response.css('title::text').extract()
[u'Example website']
使用@或attr()来获取属性。
>>> response.xpath('//base/@href').extract()
[u'http://example.com/']
>>> response.css('base::attr(href)').extract()
[u'http://example.com/']
获取指定内容,如image。
>>> response.xpath('//a[contains(@href, "image")]/@href').extract()
[u'image1.html',
u'image2.html',
u'image3.html',
u'image4.html',
u'image5.html']
>>> response.css('a[href*=image]::attr(href)').extract()
[u'image1.html',
u'image2.html',
u'image3.html',
u'image4.html',
u'image5.html']
结合正则表达式。
>>> response.xpath('//a[contains(@href, "image")]/text()').re(r'Name:\s*(.*)')
[u'My image 1',
u'My image 2',
u'My image 3',
u'My image 4',
u'My image 5']