新书《离线和实时大数据开发实战》

购买链接(机械工业出版社官方淘宝店铺)
感谢@薛奎 和@空无 大大写推荐书评。
空无和薛奎的书评

大数据技术一直是个领先互联网公司的必备核心技术,阿里巴巴最近10年一直在持续加大投入,并将大数据处理技术用于大量的大规模业务场景。每年双十一对实时、离线技术也都是极限的考验,而作者就是在这样的环境下成长起来,基于真实业务场景钻研相关的技术,既有实战也有体系,相信这样的书会一定会给行业的从业者带来帮助,尤其是准备用大数据对传统公司进行改造升级正摩拳擦掌的朋友。
--空无,阿里巴巴资深总监
这是一本经过实践淬炼的大数据实操的书,特别是作者在阿里经历了不同大数据平台(离线,实时)的演进和迭代,相同的技术,不同的历炼,得到的领悟与实践真经一定会不一样。同类书籍相信不少,而同作者这样实战提炼而成的书应该不多。如果你是一个真正想探究并想从事大数据工作的人,相信这本书会给你莫大帮助。
--薛奎,阿里巴巴资深数据技术专家
我为什么写《离线和实时大数据开发实战》
念念不忘,终有回响。
撰写一本关于数据开发相关书的念头诞生于几年前我个人学习数据知识的早期,当时我遍寻市面上所有的数据书籍,没有发现一本系统化讲述、同时又从项目实践角度突出重点的数据开发书籍。
这本书是从2016年底开始构思的,差不多花费了2017年整年的业余时间至整体成文,再经历了2018年这几个月的正文修改、排版调整、图文编辑、最终定稿、出版印刷,5月初这本书终于正式出版。
这本书主要面向大数据开发的初级和中级人员。
个人非常理解某领域初学者的苦衷,对于领域急需入门者来说,首要最重要的不是具体的API、安装教程等,而是先找到该领域的知识图谱,有了它,就可按图索骥,有所学、有所不学,有所深入,有所了解。
对于大数据技术来说,此种需求更甚,由于社区、商业甚至私人的原因,大数据的技术可以说是五花八门,琳琅满目,初学者非常容易不知所措,不知从哪里下手;而另一方面看,理论上来说互联网上包含了所有的大数据技术,比如你可以去百度、问知乎,但是这些都是碎片化的知识,不成体系,你需要先建立自己的大数据知识架构,然后百度知乎才是你的领域深入器。
本书正是基于这样的初衷撰写的,本书最希望的是帮助和加快大数据相关人员建立自己大数据开发领域知识图谱的过程,能够更快的了解这片领域,而无需花更长的时间自己去摸索。
当然,另外一方面,未来是一个DT(Data Technology)时代,同时随着人工智能、大数据、云计算的崛起,未来数据将扮演关键的作用,数据将成为如同水电煤一样的基础设施。但是,实际上目前数据的价值还远远没有得到充分的挖掘,比如医疗数据、生物基因数据、交通物流数据、零售数据等。所以个人非常希望本书能够帮助到各个业务领域的业务分析人员、分析师、算法工程师等,让他们更快对熟悉和掌握悉数据的加工处理知识和技巧,从而能够更好更快地分析数据、挖掘数据和应用数据,让数据产生更多、更大的价值。
也非常希望通过阅读本书,读者能建立自己的大数据开发知识体系和图谱,并掌握数据开发的各种技术,包含其有关概念、原理、架构以及实际的开发和优化技巧等,并能对实际项目中的数据开发提供指导和参考。
本书的章节安排
本书包含三大部分,共计12章内容。
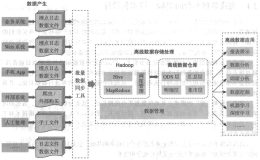
第一部分为数据大图和数据平台大图篇,主要从站在全局的角度,对数据、数据技术、数据相关从业者和角色、离线和实时数据平台架构等给出整体和大图形式的介绍,其中:
第1章 站在数据的全局角度,对数据流程、流程中涉及的主要数据技术进行了介绍,此外本章还介绍了主要的数据从业者角色和他们的日常工作内容,使读者有个感性的认识;
第2章 站在数据平台的角度,对离线和实时数据平台架构以及相关的各项技术进行介绍,本章是本书的纲领,同时也给出了数据技术的整体骨架,后续的各章将基于此骨架,具体详述各项技术;
第二部分为离线数据处理篇,离线数据是目前整个数据开发的根本和基础,也是目前数据开发的主战场,本部分详细介绍了离线数据处理的各种技术,其中:
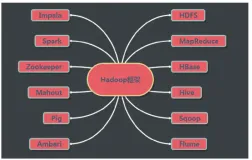
第3章 详细介绍离线数据处理的技术基础Hadoop MapReduce和HDFS,本章主要从执行原理和过程方面介绍了此项技术,此章内容是后续第4章和第5章的基础;
第4章 详细介绍了Hive,Hive是目前离线数处理的主要工具和技术,本章主要介绍了其概念、原理、架构,并以执行图解的方式,详细介绍了其执行过程和机制;
第5章 详细介绍了Hive的优化技术,包含数据倾斜的概念,join无关的优化技巧,join相关的优化技巧尤其是大表和大表join的可能的优化方案等;
第6章 详细介绍了数据的维度建模技术,包含维度建模的各种概念、维度表和事实表的设计以及大数据时代对于维度建模的改良和优化等;
第7章 主要以虚构的某全国连锁零售超市FutureRetailer为例介绍了逻辑数据仓库的构建,包含数据仓库的逻辑架构、分层、开发和命名规范等,此外本章还介绍了数据湖的新数据架构。
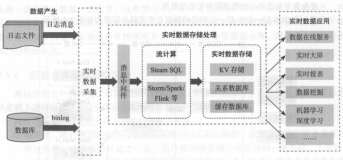
第三部分为实时数据处理篇,主要介绍了实时数据处理的各项技术,包含Storm、Spark Streaming、Flink、Beam以及流计算SQL等,其中:
第8章 详细介绍了分布式流式计算最早流行的Storm技术,包含原生Storm以及衍生的Trideng框架;
第9章 主要介绍了Spark生态对于流式数据处理的解决方案Spark Streaming,包含其基本原理介绍、基本API、可靠性、性能调优、数据倾斜和反压机制等;
第10章 主要介绍了流计算技术新贵Flink技术,Flink兼顾了数据处理的延迟以及吞吐量,而且具有流计算框架应该具有的诸多数据特性,因此被广泛认可为下一代的流式处理机引擎;
第11章 主要介绍了Google力推的Beam技术,Beam的设计目标就是统一离线批处理和实时流处理的编程范式,Beam抽象出的数据处理的通用处理范式“Beam Mode”是流计算技术的核心和精华;
第12章 主要结合Flink SQL和阿里云Stream SQL介绍了流计算 SQL以并以典型的几种实时开发场景为例进行了实时数据开发实战。