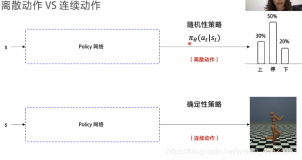
雷锋网(公众号:雷锋网)按:本文来自 硬创公开课 | AlphaGo专场的分享。分享嘉宾,出门问问NLP工程师,李理。

一、到底什么是深度学习?
我认为深度学习相对于传统的机器学习,最大的特点就是不需要(太多)的feature engineering。
在机器学习流行之前,都是基于规则的系统,因此做语音的需要了解语音学,做自然语言处理(NLP)的需要很多语言学知识,做深蓝需要很多国际象棋大师。而到后来统计方法成为主流之后,领域知识就不再那么重要,但是我们还是需要一些领域知识或者经验来提取合适的feature,feature的好坏往往决定了机器学习算法的成败。
对于NLP来说,feature还相对比较好提取,因为语言本身就是高度的抽象;而对于Speech或者Image来说,我们人类自己也很难描述我们是怎么提取feature的。比如我们识别一只猫,我们隐隐约约觉得猫有两个眼睛一个鼻子有个长尾巴,而且它们之间有一定的空间约束关系,比如两种眼睛到鼻子的距离可能差不多。但怎么用像素来定义”眼睛“呢?如果仔细想一下就会发现很难。当然我们有很多特征提取的方法,比如提取边缘轮廓等等。
但是人类学习似乎不需要这么复杂,我们只要给几张猫的照片给人看,他就能学习到什么是猫。人似乎能自动“学习”出feature来,你给他看了几张猫的照片,然后问题猫有什么特征,他可能会隐隐预约的告诉你猫有什么特征,甚至是猫特有的特征,这些特征豹子或者老虎没有。
深度学习为什么最近这么火,其中一个重要的原因就是不需要(太多)提取feature。
从机器学习的使用者来说,我们以前做的大部分事情是feature engineering,然后调一些参数,一般是为了防止过拟合。而有了深度学习之后,我们似乎什么也不用干!给它标注足够多的训练数据就行了。
具体的应用比如语音识别,图像识别,自然语言处理,这是比较成熟的一些领域。在一些其它领域,比如杀毒,天气预测。只要需要用机器建模,特征比较难以描述,而且又有足够多标注数据的地方都可以试一试深度学习。
二、同样是与人类对战,AlphaGo和深蓝的区别
深蓝的主要技术有两个:alpha-beta搜索和估值模型。搜索,大家应该都明白,机器学习就是更加领域专家(国际象棋大师)提取的特征(比如棋子的价值,位置的作用,棋子的保护和威胁关系等等),然后建立一个复杂的模型来判断局面(不太清楚是否用了机器学习)。
而AlphaGo的核心技术是:MCTS搜索和CNN神经网络。CNN使得机器可以学习人类的“棋感”,从而在开局和中局不落下风,然后残局凭借强大的计算能力战胜人类。
因为深度神经网络非常火,大家可能觉得它是AlphaGo能赢的关键,其实我觉得不是这样。
根据Tian yuandong(田渊栋)和AlphaGo的论文,如果不做任何搜索,只是根据“棋感”(其实就是估值函数),CNN最好能达到KGS 3d的水平,我估计也就业余1段的水平。而MCTS算法在没有Value Network的情况下在9 x 9的棋盘上能战胜人类高手,其实这也间接印证了AlphaGo在残局的实力是搜索(计算)起重要作用。原来基于搜索的软件在开局和中局就崩盘或者亏太多了,所以就不能体现搜索的优势了。另外AlphaGo使用了Value Network,这保证即使搜索有一些小问题,从人类学来的棋感也能保证不至于偏差太大。
AlphaGo的特点是:开局和中局依靠人类的棋盘学习棋感(可以理解为背棋盘,不过比死记硬背好一点,有一定的泛化能力),然后残局的计算能力碾压人类,就好像以前的李昌镐,前面看不出什么好来,但官子你就是下不过他,没办法,不服不行。
三、在比赛前,很多人都判断AlphaGo会输,这种判断偏差在哪里?
之前我们都太多关注AlphaGo的神经网络部分,其实它赢棋的关键可能在于残局的计算上。我们没有想到。
四、整个比赛的输赢对人工智能研究意味着什么?
作为对人工智能感兴趣的工程师,我既感到高兴又不免有些伤感。
高兴是因为我们可以“创造”出比我们自己“聪明”的机器,伤感就像教拳击的师傅看到徒弟的水平已然超过自己,不免有“老了,不中用了”的感叹。但这是大势所趋,不可避免,人工智能会在很多领域超过人类。
五、首场比赛,AlphaGo为什么在后半程越走越慢?
这是计算机用时的策略问题,因为根据前面的分析,后面的残局才是AlphaGo赢棋的关键,所以它把更多的时间放在残局是合理的策略。
六、如果计算性能够强大,AlphaGo能否直接得出最优解?
从数学上来讲,围棋有个最优的走法,也就是用mini-max搜索到游戏结束时的一条最优路径(也许有多条,但至少有一条),然后就能知道最优的情况下黑棋胜白棋多少目。
我认为AlphaGo离最优解其实还是差得老远的,尤其是开局和中局。其实这也间接的说明人类在开局上其实也离最优解差得太远。人类几千年也下不了多少盘棋(而且水平越差的人的棋对整个人类围棋没有太大帮助)。我们认为一个开局是否好,只能根据水平相似的高手下这个布局的胜率来推测它的好坏。但如果我们在最后50步的时候误差就很大,那么往前传播时积累的误差就更大了,我们可能经常忽略了一个看起来不好的走法,而这个走法可能就是“支持”这个开局的关键。
当然AlphaGo的残局比人厉害,那么就可以通过自己对弈来学习,然后往前传播误差。但是由于这个问题本质是NP的,即使它用了MCTS的方法来避免“明显不好”的走法。但是由于围棋的复杂性,可能某个“看起来不好”的走法可能恰恰是一个关键的胜负手呢?另外根据之前的分析,即使每步都能99%的准确,那么往前推100步准确的可能性也基本是0了。
因此如果人类不能解决NP问题,不能提出计算能力超过图灵机的计算模型,那么人类制造的机器也是不太可能解决这个问题的(当然这只是我的直觉,不知道能不能数学上证明)。
不过即使这样,能制造和人类一样,虽然在质上不能超越人类,但在量上能超越人类的机器也是很有意义的。
七、AlphaGo在学习什么,是如何学习的?
AlphaGo是通过人类高手的对局作为训练数据来训练的,也就是给定一个局面,用人类高手的下一步棋做完这个局面的最优走法。通过大量的这样的数据,使用CNN自动学习出类似人类的”棋感“。当然虽然说CNN不需要太多的feature,其实AlphaGo也是用了一些围棋的知识的,比如征子。我虽然比较业余,也知道征子能否成功要看那六线上是否有对手的接应,另外更棋的高低也有关系,即使有接应,如果棋太低,可能也能征子成功,这个就要计算了。
另外,AlphaGo也通过自己和自己对弈的强化学习来改进它”棋感“。我个人觉得为什么要强化学习的原因可能是:之前那些棋谱学习出来的是很多人的”棋感“,通过强化学习,AlphaGo能选择更适合自己的“棋感”。
这样的”棋感“更能适应它的后阶段的计算能力。就好像如果我下棋计算能力不行,我就走一些比较稳的开局。我计算力超强,我就和你搏杀,走复杂的变化。
AlphaGo一晚上的学习大概能达到什么样的效果?
这个很难说,我个人觉得他们应该不会再训练新的模型,因为即使是深度神经网络,调参也是很tricky的事情。而且他们现在领先,应该不会冒险更新模型。
八、除了围棋,AlphaGo还可以用在什么领域?
AlphaGo本身的技术是MCTS和CNN,MCTS其实是属于强化学习这个领域的。
深度学习可以用在很多领域,前面说过了,只要这个领域需要构建一个模型来预测,而且有大量标注的训练数据。
强化学习是非常关键,我觉得强化学习才是人类社会学习的过程,通过行为改变世界,然后从反馈中学习。虽然人类也有一些监督学习,比如学校的教育,把前人的结论作为训练数据。但大部分的创新(获取新知识或者修正旧知识)都是靠强化学习。之前学校学到的可以认为是先验知识,但还是要自己的行为和尝试。纸上得来终觉浅,绝知此事要躬行。
比如我们要让机器人在火星生存,火星的环境我们是不太清楚的,只能根据地球的数据训练一个基本的先验的模型。到了火星之后机器人就必须能通过强化学习来学习新的知识来适应新的环境。
本文作者:吴德新
本文转自雷锋网禁止二次转载,原文链接