
YOLO不是“魔法”,是你自己也能跑通的一条工程流水线:Python从标注到训练全实战
说实话,我第一次接触 YOLO 的时候,脑子里想的是:“这玩意儿是不是要读一堆论文才能用?”
后来真正上手才发现——
YOLO的核心不是复杂,而是工程流程清晰到离谱。
你只要搞懂三件事:
标注数据 → 组织数据 → 训练模型
剩下的,基本就是“交给GPU干活”。
今天这篇文章,我带你用最接地气的方式,把 YOLO 从零跑通一遍:
包括 自己标注数据 + Python整理 + 训练模型 + 推理测试
一、YOLO到底在干嘛?一句话讲明白
YOLO本质就一句话:
一张图片输入 → 直接输出框 + 类别 + 置信度
比如:
输入:一张街景图
输出:
- 人(0.91)
- 车(0.88)
- 红绿灯(0.73)
它和传统目标检测区别是:
| 方法 | 特点 |
|---|---|
| RCNN系列 | 慢,但精细 |
| YOLO | 快,适合工程 |
一句话总结:
YOLO = 实时目标检测工业标准答案
二、第一步:数据标注(最关键,没有之一)
很多人卡在 YOLO 的第一步,不是模型,是数据。
我们用最常见工具:
👉 LabelImg(免费)
安装:
pip install labelImg
labelImg
打开后你会看到这样的流程:
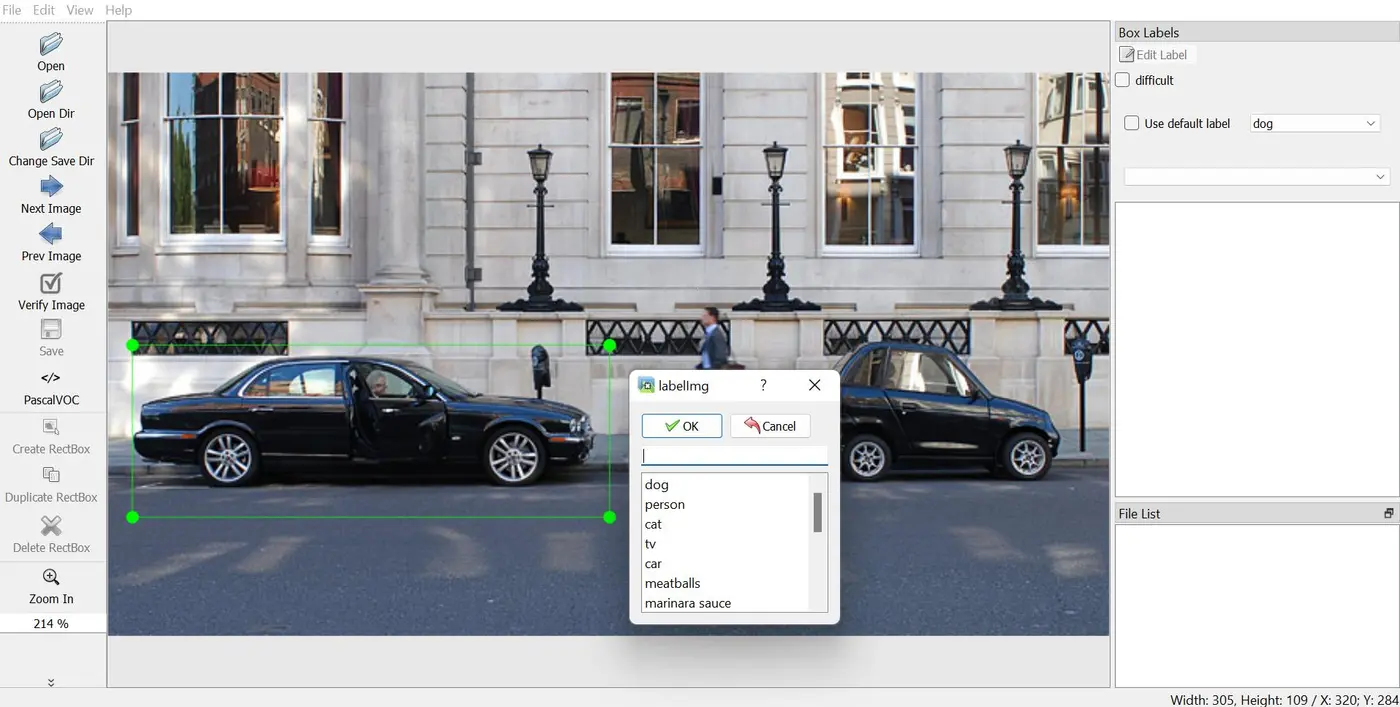
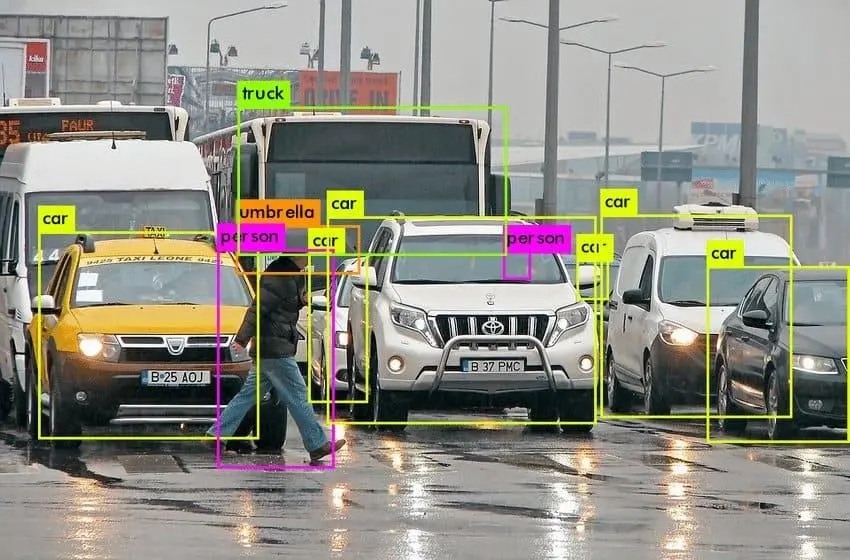
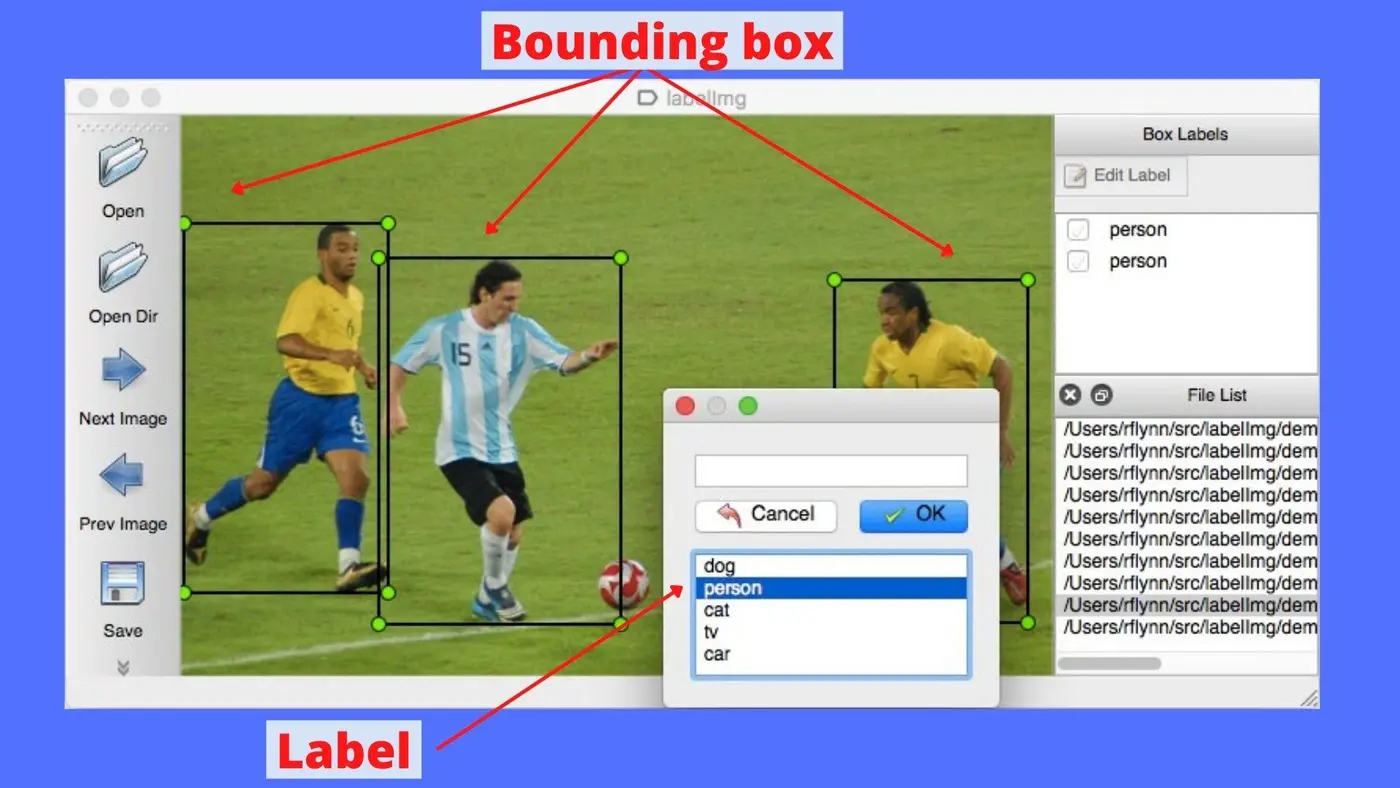
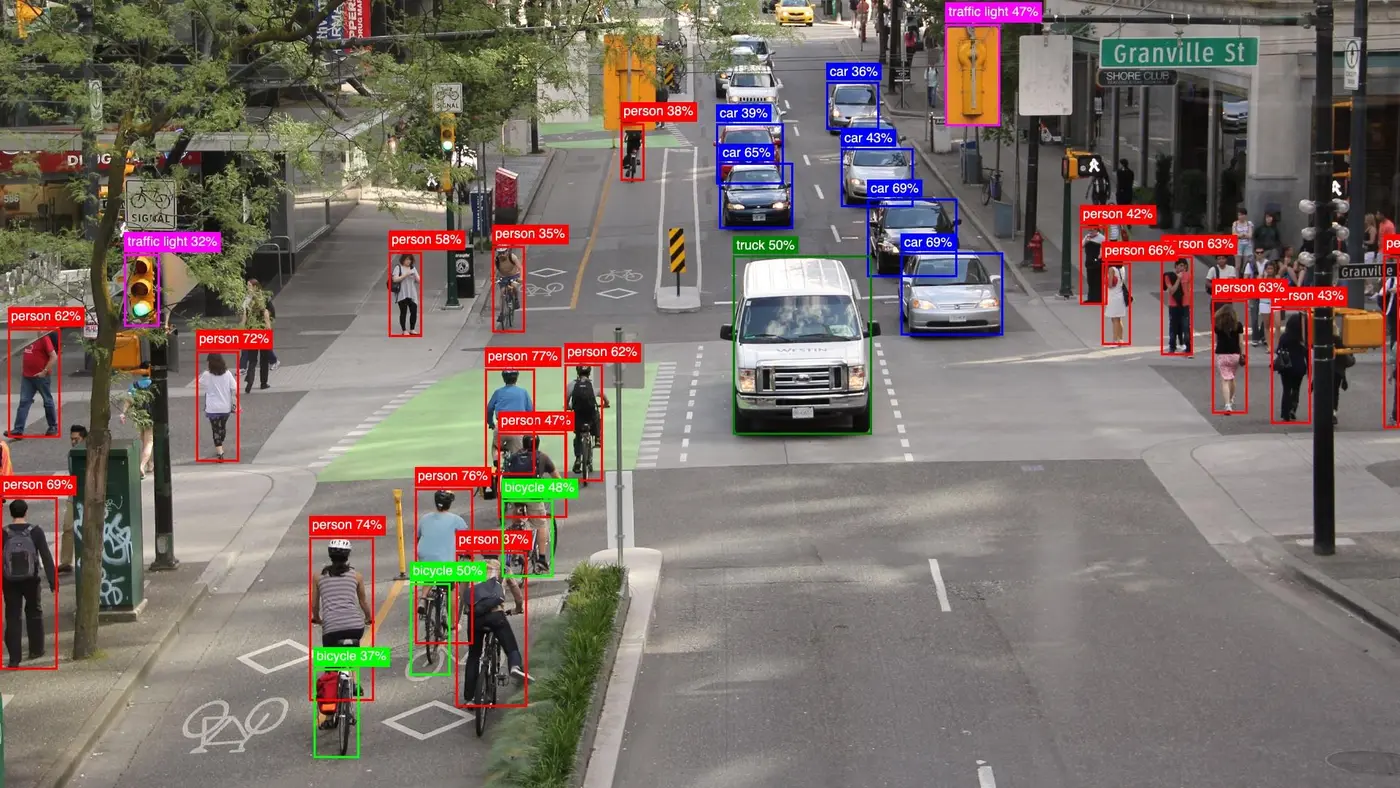
你要做的事情只有:
- 框住目标
- 选择类别
- 保存
保存后会生成 .txt 文件,比如:
0 0.52 0.48 0.20 0.30
1 0.33 0.40 0.15 0.22
YOLO格式解释:
class x_center y_center width height
(都是归一化后的比例)
👉 重点一句话:
YOLO吃的不是像素坐标,是“比例坐标”
三、第二步:整理数据集结构(很多人这里就崩了)
YOLO标准结构:
dataset/
├── images/
│ ├── train/
│ ├── val/
├── labels/
│ ├── train/
│ ├── val/
你必须保证:
👉 图片和标签一一对应
比如:
images/train/0001.jpg
labels/train/0001.txt
四、用 Python 自动划分训练集(实战)
手动分数据?太原始了,我们直接 Python 搞定:
import os
import random
import shutil
img_dir = "dataset/images/all"
label_dir = "dataset/labels/all"
train_img_dir = "dataset/images/train"
val_img_dir = "dataset/images/val"
train_label_dir = "dataset/labels/train"
val_label_dir = "dataset/labels/val"
os.makedirs(train_img_dir, exist_ok=True)
os.makedirs(val_img_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
files = os.listdir(img_dir)
random.shuffle(files)
split = int(len(files) * 0.8)
train_files = files[:split]
val_files = files[split:]
def move(files, img_dst, label_dst):
for f in files:
name = os.path.splitext(f)[0]
shutil.copy(f"{img_dir}/{f}", f"{img_dst}/{f}")
shutil.copy(f"{label_dir}/{name}.txt", f"{label_dst}/{name}.txt")
move(train_files, train_img_dir, train_label_dir)
move(val_files, val_img_dir, val_label_dir)
五、配置 YOLO(核心一步)
我们用现在最流行的 Ultralytics YOLO
安装:
pip install ultralytics
创建数据配置文件 data.yaml:
path: dataset
train: images/train
val: images/val
nc: 2
names: ["person", "car"]
六、开始训练(真正的“起飞时刻”)
Python 一行启动训练:
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.train(
data="data.yaml",
epochs=50,
imgsz=640,
batch=16
)
训练过程你会看到:
Epoch 1/50: loss xxx
Epoch 10/50: mAP ↑
Epoch 50/50: final model saved
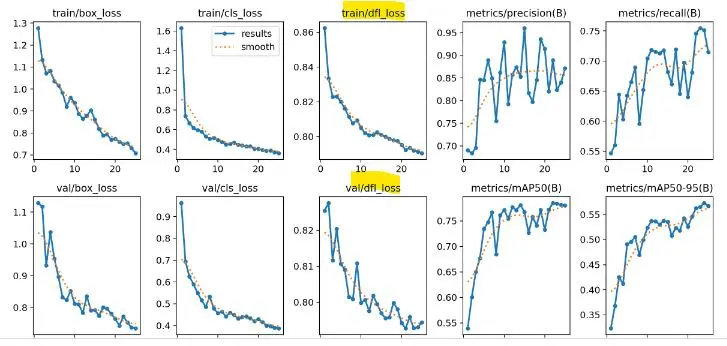
七、训练结果长什么样?
一般会输出:
runs/detect/train/
├── weights/
│ ├── best.pt
│ ├── last.pt
├── results.png
你会看到:


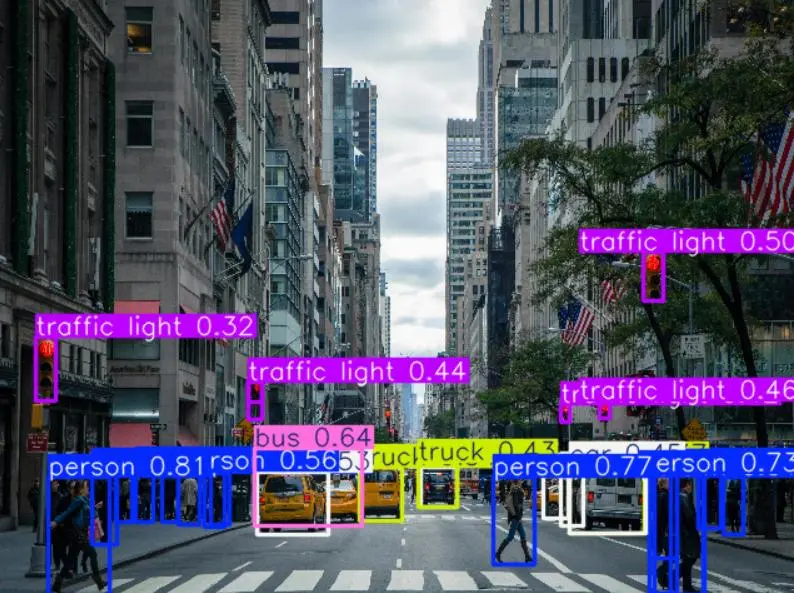

八、推理测试(最爽的一步)
from ultralytics import YOLO
model = YOLO("runs/detect/train/weights/best.pt")
results = model("test.jpg")
results.show()
或者直接:
model.predict(source="test.jpg", save=True)
输出结果:
- 框
- 类别
- 置信度
九、真实工程中 YOLO 的坑(很重要)
我说点实话,这部分比代码更值钱:
1)数据质量 > 模型结构
很多人上来就换 YOLOv11、YOLOv12……
但:
标注歪了,神仙模型也救不了
2)类别不平衡是大坑
比如:
- person 5000张
- helmet 50张
结果:
👉 模型直接忽略 helmet
3)小目标检测难
比如:
- 远处人脸
- 小零件检测
解决方法:
- 提高分辨率
- 增加数据
- mosaic增强
十、我的一点真实感受
做 YOLO 这类项目久了,你会有一个很明显的体感:
AI不是“模型聪明”,而是“数据工程决定一切”。
很多人以为:
- 换模型 = 提升效果
但现实是:
数据干净 + 标注合理 + 训练稳定
比任何复杂模型都重要
YOLO给我的最大启发其实不是AI,而是:
工程世界没有魔法,只有流程。
你把流程跑通,它就稳定产出结果。
十一、如果你想继续深入(下一步可以做什么)
如果你已经跑通 YOLO,我建议下一步:
- 加入 Flask 做推理服务
- 接入 RTSP 视频流(监控系统)
- 做工业缺陷检测
- 做边缘设备部署(Jetson)
甚至可以扩展成:
一个完整的“AI视觉检测系统”
最后总结一句话
YOLO这套东西,其实没你想的那么玄:
它不是让机器“看懂世界”,而是让工程把“视觉问题标准化”。
当你真正跑通一次训练流程,你会发现:
👉 AI不是高深理论
👉 是一条可以复制的生产线
如果你下一步想玩点更狠的,我可以帮你继续写一篇:
👉《YOLO + Flask + 实时视频流:做一个工业级AI检测系统》
直接带你从“训练模型”进化到“上线系统”。
