
前言
过去几年,云原生已经从“新技术趋势”逐渐演变为企业数字化建设的基础设施标准。
根据 CNCF 发布的云原生调查报告,全球超过 90% 的企业已经在生产环境中使用 Kubernetes 或正在规划 Kubernetes 相关项目。
与此同时,国内越来越多企业开始将业务迁移到云原生平台:
- 微服务架构
- DevOps体系
- AI大模型平台
- 数据中台
- IoT平台
这些系统背后,都离不开 Kubernetes 的支撑。
然而对于很多开发者而言:
Kubernetes 会用,不代表 Kubernetes 用得好。
大量团队上线后会遇到:
- Pod频繁重启
- 集群资源浪费
- 节点扩缩容失控
- 服务发布故障
- GPU资源利用率低
本文将从 Kubernetes 基础原理出发,结合 ACK(阿里云容器服务 Kubernetes 版)生产实践,分享企业落地经验、避坑指南以及成本优化方案。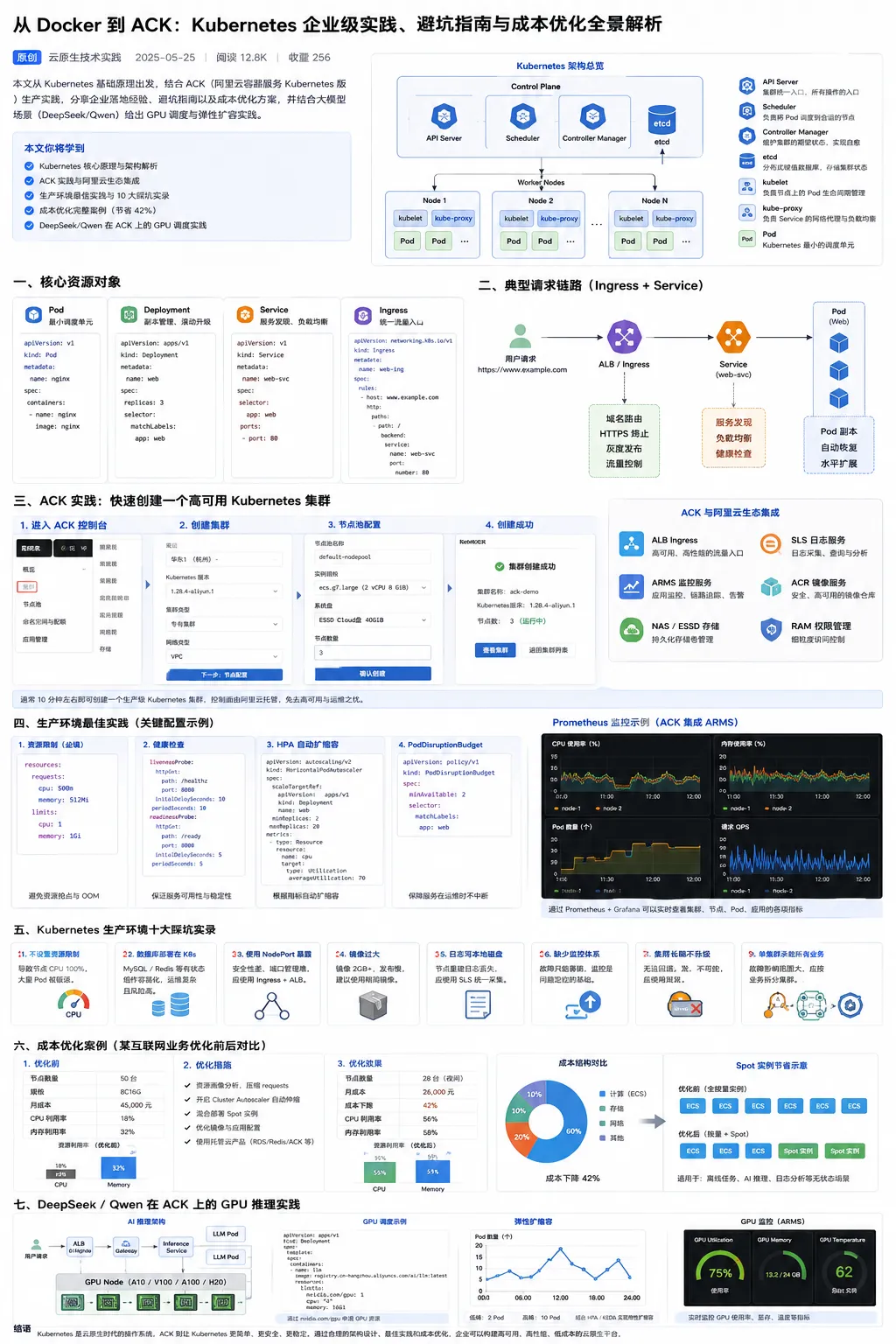
一、为什么 Kubernetes 会成为云原生事实标准
在虚拟机时代,一个应用对应一台服务器:
APP1 -> VM1
APP2 -> VM2
APP3 -> VM3
资源利用率普遍不足:
CPU利用率
10% ~ 20%
Docker 出现后:
Server
├─ Container A
├─ Container B
├─ Container C
资源利用率大幅提升。
但新的问题出现:
当容器数量达到数百个时:
- 如何部署?
- 如何升级?
- 如何扩容?
- 如何恢复?
Kubernetes 正是为了解决这些问题而诞生。
二、Kubernetes 核心架构解析
Kubernetes 集群由两部分组成:
Control Plane
|
|
Worker Nodes
Control Plane
负责整个集群管理。
核心组件:
API Server
集群统一入口。
所有命令最终都会调用:
kubectl -> API Server
Scheduler
负责调度 Pod。
例如:
Node1
Node2
Node3
Scheduler 根据:
- CPU
- Memory
- Affinity
- Taints
选择最优节点。
Controller Manager
负责状态管理。
核心思想:
期望状态
=
实际状态
如果不一致:
自动修复。
etcd
集群状态数据库。
存储:
- Deployment
- Service
- ConfigMap
- Secret
等资源信息。
三、生产环境必懂的核心对象
Pod
最小运行单元。
kind: Pod
但生产环境几乎不会直接创建 Pod。
Deployment
最常用资源对象。
提供:
- 副本管理
- 自动恢复
- 滚动升级
replicas: 3
Service
解决 Pod IP 变化问题。
Client
↓
Service
↓
Pod
实现服务发现。
Ingress
统一流量入口。
Internet
↓
Ingress
↓
Service
↓
Pod
实现:
- HTTPS
- 域名路由
- 灰度发布
四、为什么越来越多企业选择 ACK
理论上:
企业可以自建 Kubernetes。
实际上:
多数企业最终会选择托管 Kubernetes。
原因非常现实。
自建集群的痛点
企业需要维护:
API Server
Scheduler
Controller
etcd
并处理:
- Master高可用
- 集群升级
- 安全漏洞
- 备份恢复
这些工作通常不产生业务价值。
ACK 的价值
ACK 提供:
- Kubernetes 托管
- 高可用控制面
- 自动升级
- 云产品集成
企业只需关注业务本身。
ACK 与阿里云生态整合
典型架构:
ALB
↓
ACK
↓
RDS
↓
Redis
↓
OSS
统一纳管。
真正实现云原生平台化。
五、生产环境最佳实践
1. 所有服务必须设置资源限制
错误示例:
resources: {
}
后果:
CPU抢占
OOM
节点雪崩
推荐:
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 1
memory: 1Gi
2. 必须配置健康检查
LivenessProbe
判断:
程序是否存活
异常自动重启。
ReadinessProbe
判断:
是否可接收流量
失败自动摘流。
3. 配置 HPA
自动扩容:
minReplicas: 2
maxReplicas: 20
根据:
- CPU
- Memory
- Prometheus指标
动态调整。
4. 使用 PodDisruptionBudget
避免节点升级导致服务中断。
minAvailable: 2
保证业务连续性。
六、Kubernetes 生产环境十大踩坑实录
下面这些问题,几乎每个团队都会遇到。
坑1:不设置资源限制
现象:
节点CPU 100%
大量 Pod 被驱逐。
坑2:把数据库部署进 K8s
很多团队:
MySQL
Redis
Kafka
全部容器化。
结果:
运维复杂度提升
数据风险增加
建议:
优先使用:
- RDS
- Redis企业版
- Kafka托管版
坑3:NodePort 暴露服务
错误:
公网
↓
NodePort
问题:
- 安全性差
- 管理困难
推荐:
ALB
↓
Ingress
坑4:镜像过大
常见镜像:
2GB+
发布时间:
5分钟+
推荐:
- Alpine
- Distroless
- 多阶段构建
坑5:日志写本地磁盘
节点重建:
日志全部丢失
正确方案:
SLS
ELK
OpenSearch
统一采集。
坑6:缺少监控体系
没有监控:
故障 = 猜
有监控:
故障 = 定位
坑7:集群版本长期不升级
最终:
无法升级
形成技术债务。
建议:
每半年评估一次版本升级。
坑8:大量使用 latest 标签
错误:
image: app:latest
导致:
无法回滚
推荐:
image: app:v1.3.2
坑9:单集群承载所有业务
结果:
故障影响全公司
建议:
按业务拆分:
- 生产集群
- 测试集群
- AI集群
坑10:没有灾备方案
必须考虑:
- 跨可用区
- 跨地域
- 数据备份
否则一次故障可能导致重大损失。
七、ACK 成本优化实战案例
某互联网客户:
50台ECS
8C16G
月成本:
45000元
资源利用率:
CPU 18%
第一步:资源画像
通过 Prometheus 分析:
发现:
request:
cpu: 2
实际:
200m
超配10倍。
第二步:压缩 Request
优化后:
request:
cpu: 300m
利用率:
18%
↓
56%
第三步:Cluster Autoscaler
自动扩缩容。
夜间:
50台
↓
28台
第四步:Spot实例混合部署
适用于:
- AI推理
- 大数据任务
- 离线计算
节约:
30%~70%
优化结果
45000元
↓
26000元
节省:
42%
八、大模型时代:DeepSeek/Qwen 如何部署到 ACK
2025年以来。
越来越多企业开始建设:
- AI助手
- 企业知识库
- 智能客服
- Agent平台
底层基本采用:
Kubernetes + GPU
方案。
AI推理架构
ALB
↓
API Gateway
↓
Inference Service
↓
LLM Pod
↓
GPU Node
ACK GPU 调度
支持:
A10
V100
A100
H20
H100
等 GPU 资源。
通过:
resources:
limits:
nvidia.com/gpu: 1
即可申请 GPU。
弹性推理
高峰:
10 Pod
低峰:
2 Pod
结合:
- HPA
- KEDA
- ACK弹性节点
实现自动扩缩容。
企业收益
相比传统固定部署:
资源利用率提升
+
GPU成本下降
+
部署效率提升
特别适合:
- DeepSeek
- Qwen
- Llama
- 通义千问
等大模型服务。
九、云原生未来趋势
未来三年。
Kubernetes 将持续向以下方向发展:
Serverless
开发者无需管理节点。
AI Native
AI工作负载全面云原生化。
GitOps
Git 成为唯一事实来源。
Platform Engineering
企业内部平台团队崛起。
开发人员只关注业务。
结语
从 Docker 到 Kubernetes,再到 ACK,企业关注的已经不再是“如何运行容器”,而是“如何构建稳定、高效、低成本的云原生平台”。
Kubernetes 提供了统一的资源调度与编排能力;
ACK 降低了 Kubernetes 的使用门槛;
而云原生理念,则正在改变整个软件交付体系。
对于开发者而言,掌握 Kubernetes 已经成为云原生时代的重要技能;对于企业而言,建设基于 ACK 的云原生平台,也正在成为数字化转型的重要基础设施能力。
未来,无论是微服务、DevOps,还是 AI 大模型平台,Kubernetes 都将继续扮演云原生时代“操作系统”的角色。

