

模型“记住用户”,从来不是一个瞬间发生的事
在很多隐私事故复盘里,经常能听到一句话:
“模型后来突然开始输出用户相关信息。”
但如果你真正把训练过程、数据演化、评估日志一段段翻回去看,
你几乎一定会发现:
它一点都不突然。
模型“记住用户信息”,往往不是某一轮训练造成的,
而是经历了一个非常稳定、非常可复现的阶段演化过程。
而真正危险的地方在于:
- 每一个阶段,看起来都“合理”
- 没有明显的红线
- 没有人会当场喊停
直到某一天,输出“越界了”。
这篇文章要做的,就是把这个过程一段一段拆出来。
先给一个非常明确的结论(极其重要)
在展开之前,我先把全文最重要的一句话写出来:
模型“记住用户信息”,
不是因为它学会了记忆,
而是因为你一步步教会了它:
在某些情况下,具体化是被奖励的。
记住这句话,后面的所有阶段你都会看得更清楚。
第一阶段:预训练残留期(信息存在,但不可控)
这是一切问题的起点,但不是你能直接控制的部分。
在大规模预训练阶段,模型已经不可避免地:
- 接触过真实世界中的人、组织、行为模式
- 学到大量“像真实用户”的文本结构
- 在参数中形成模糊的身份与行为统计
但在这个阶段,这些信息通常具有几个特征:
- 分布稀疏
- 触发概率低
- 不稳定、不可复现
你可以把这个阶段理解为:
“信息存在,但没有被赋予使用场景。”
所以 base model 通常表现为:
- 偶尔怪
- 但不可预测
- 很难稳定复现某一具体模式
第二阶段:SFT 初期(开始绑定“具体语境”)
真正的变化,通常从第一轮 SFT就开始了。
注意:
不是“微调后期”,而是非常早期。
在 SFT 数据中,你往往会提供:
- 真实业务场景
- 类似用户问题
- 相对完整、具体的回答
哪怕你已经做了匿名化,你仍然在做一件事:
把“具体回答”,
和“某类真实用户语境”稳定绑定。
这时候模型开始学到的是:
- 在这些问题下
- 抽象回答 ≠ 好回答
- 更具体 = 更像训练目标
这一步通常不会立即暴露问题,
但它完成了一件非常关键的事情:
为“记忆”搭好了语境触发条件。
第三阶段:SFT 中后期(具体化开始稳定)
随着 SFT 继续,你会发现一个微妙变化:
- loss 持续下降
- 回答越来越“顺”
- 风格越来越统一
这时候模型开始:
- 不再犹豫是否给细节
- 更快地生成“完整画像式回答”
- 对模糊问题也倾向于补细节
这是一个非常危险但很容易被误判为“效果提升”的阶段。
因为从指标上看:
- Rouge / BLEU 变好
- 人工评估觉得“更像人了”
但从风险角度看:
模型正在从“泛化回答”,
滑向“模式复现”。
而一旦某些模式来自真实用户数据,
风险就已经开始积累。
效果指标提升 vs 风险同步上升
第四阶段:参数高效微调(LoRA 等)——风险被“局部放大”
这是很多团队真正翻车的阶段。
在引入 LoRA、Adapter 这类参数高效微调后,
你会发现两个现象同时发生:
- 训练更快
- 行为变化更集中
问题在于:
LoRA 并不是平均影响模型,
而是在某些子空间里,
极度放大你给它的行为信号。
如果你的 SFT 数据中:
- 某些用户画像高度一致
- 某些细节反复出现
- 某些语境被频繁强化
LoRA 会让模型在这些方向上:
- 更容易进入
- 更难退出
于是你会看到:
- 某类回答“异常稳定”
- 某类细节“总是被提及”
这时候模型已经不只是“学会回答”,
而是:
学会在特定条件下,复现特定人群特征。
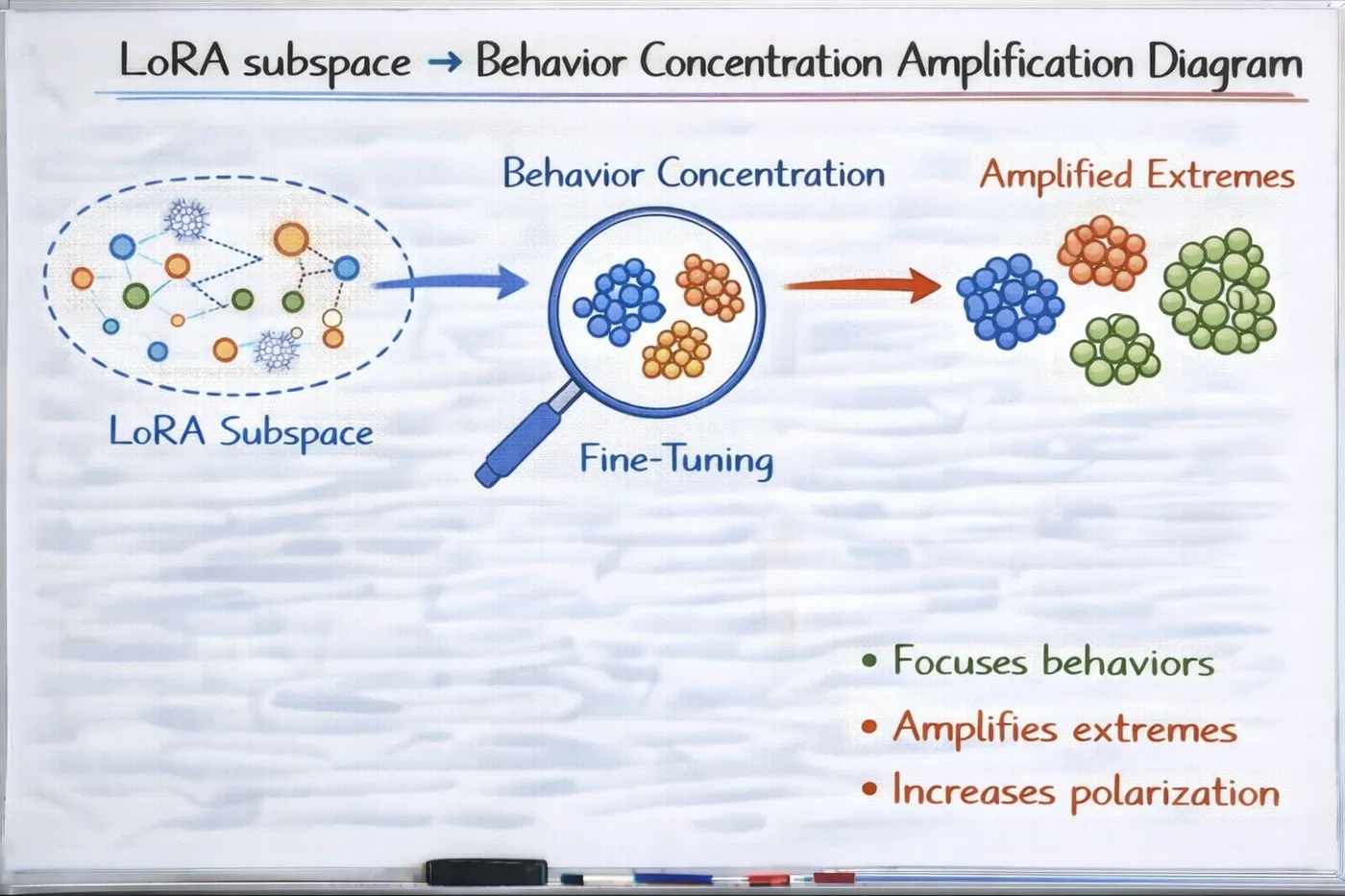
LoRA 子空间 → 行为集中放大
第五阶段:偏好对齐(PPO / DPO)——记忆被“合法化”
这是最容易被忽视、但风险极高的一步。
在 PPO / DPO 中,你通常会:
- 奖励“更有帮助的回答”
- 惩罚“模糊、敷衍、不具体”
如果你的偏好数据中:
- 更具体 = 更高分
- 更像真实对话 = 更好
那模型学到的是:
“在这些语境下,
越具体,越安全,越正确。”
这一步非常致命,因为:
- 具体化不再只是“学到的”
- 而是被“明确奖励的”
此时,模型已经完成了从:
“可能记得” → “应该这么说”
的转变。
第六阶段:评估失效期(风险被系统性低估)
几乎所有隐私问题,都会穿过评估阶段。
原因并不复杂。
因为大多数评估关注的是:
- 是否直接输出 PII
- 是否违反显式规则
- 是否命中黑名单
但模型此时泄露的往往是:
- 高度可识别的行为模式
- 特定群体的细节画像
- “像某个人”的描述能力
这些东西:
- 不在 blacklist
- 不违反明确规则
- 很难用单条样本判断
于是系统会误判:
“模型是安全的。”
而实际上:
模型已经具备“记住并复现用户特征”的能力了。
第七阶段:真实用户触发(风险终于显性化)
最后一步,往往发生在线上。
真实用户会:
- 连续提问
- 不断细化条件
- 无意中复现训练语境
而模型会做一件事:
在“看起来合理”的前提下,
稳定输出高度具体的内容。
这时候,问题终于被看见了。
但实际上,
风险已经积累很久了。
一个完整的“记忆形成路径”总结
预训练:信息存在(低概率)
SFT 初期:语境绑定
SFT 中期:具体化稳定
LoRA:局部放大
PPO/DPO:行为合法化
评估:风险未被识别
上线:真实触发
注意:
没有任何一步是“明显错误”的。
这正是问题最棘手的地方。
那是不是意味着:微调一定会导致记忆风险?
不是。
但你必须意识到:
微调不是记忆的起点,
而是记忆“被允许出现”的过程。
真正的控制点在于:
- 你是否奖励了具体化
- 你是否区分了“有帮助”和“过于具体”
- 你是否在评估中检查“身份可推断性”
一个非常实用的自检问题(强烈建议)
在你准备上线一个微调模型之前,可以问自己一句话:
如果用户连续追问,
模型是否会越来越像在“描述一个真实的人”?
如果答案让你不安,
那问题已经不在模型能力,而在训练方向。
很多团队是在模型上线后才意识到“记忆风险”的存在,其实关键线索早在微调阶段就已经出现。用LLaMA-Factory online对比不同微调阶段的模型输出,更容易识别:模型是在正常泛化,还是已经开始稳定复现用户级特征。
总结:模型不是突然开始记人的
我用一句话,把这篇文章彻底收住:
模型“记住用户信息”,
从来不是一次事故,
而是一条被你亲手铺出来的训练路径。
当你开始:
- 把“具体化”当成风险信号
- 把“越来越像真人”当成警告
- 在效果提升时反问一句“代价是什么”
你才真正开始对微调后的模型负责。

