
一直以来,我们和数据之间始终存在距离,要从数据中获取洞察,需要拖拽字段、配置图表,甚至写 SQL 语句、Python 代码。而 chatBI 的出现,似乎可以让这一切变得前所未有的简单,只要会打字、会提问,就能轻松获得结果。chatBI 就像个玩具一样容易上手,让人很乐意去“玩”一下数据。
然而,当我们真正想把 chatBI 应用到实际业务中时,却会遇到不少问题。
问题一,大模型的“幻觉”让 chatBI 不可信赖
chatBI 的核心 -- 大模型技术,本质上是概率模型,其训练目标是生成流畅文本,而不是精确的数据查询结果。虽然大模型已经非常强大了,但天生存在的“幻觉”问题并没有解决——它可能会编造数据、混淆概念,甚至给出完全错误的结论。
无论用户输入怎样的问题,大模型永远都会给出一个结果,即使数据库中数据根本就无法计算这个任务目标,大模型也不会拒绝,不懂编程的业务用户根本没办法发现和纠正大模型的错误。这在商业决策中是无法容忍的,一个错误的数据可能导致严重的后果。
实际上,大家并不敢完全相信 chatBI 给出的结论,只是随便聊聊天玩玩而已。
问题二,chatBI 缺乏 BI 领域的专业知识
大模型虽然擅长理解自然语言,但并不掌握当前业务领域的知识,包括:数据结构、业务规则和编程知识。缺乏这些领域知识,chatBI 自然难以完成相关的 BI 任务,只能当成一个玩具了。
虽然大模型可以通过微调来获取这些领域知识,但是,微调需要用大量计算资源和高质量的标注数据对大模型进行训练,技术难度大,资源成本高,开发周期长。而且,一旦业务规则或者数据结构发生变化,模型就要重新微调,非常不灵活。
简单在提示词中嵌入领域知识,一定程度上也可以让大模型获取这些知识。不过,这种做法也无法确保得到正确的查询结果,而且还会让提示词变得很长,导致性能下降,token 费用上升。
问题三,chatBI 无法计算复杂的指标
真正的商业分析远不止简单计数、求和。像“客户留存率”、“日活月活”等复杂指标,有经验的程序员写代码实现都需要较长时间,若用大模型生成代码将会非常困难,即使给出代码也很难判断是否正确。
当前的 chatBI 大多停留在基础查询层面,难以实现这些很有价值的分析场景。
从“玩具”到“工具”:润乾报表 NLQ 组件的突破
像玩具一样容易上手的 chatBI 问题多多,也像玩具一样只能玩玩,无法起到数据分析支撑业务的作用。
面对 chatBI 的这些局限,润乾报表团队基于多年 BI 领域的技术积累,推出了全新的 NLQ(自然语言查询)组件,能让 AI 式数据查询从“能玩的玩具”变成“好用的工具”。
可信赖的结果,确保正确性
NLQ 组件采用规则引擎技术,通过抽象汉语规律得到规则模型,可以实现精准的 AI 式数据查询,彻底杜绝大模型的幻觉问题。
NLQ 如果识别不了用户的输入,会提示无法查询,请用户换一种说法再尝试。而不会像大模型那样总是给个不知对错的答案。
NLQ 组件给出结果后,会以用户看得懂的形式对这个语句进行解释,如果有多种解释也会让用户选择,比如日期可以是发货日期或者收货日期:
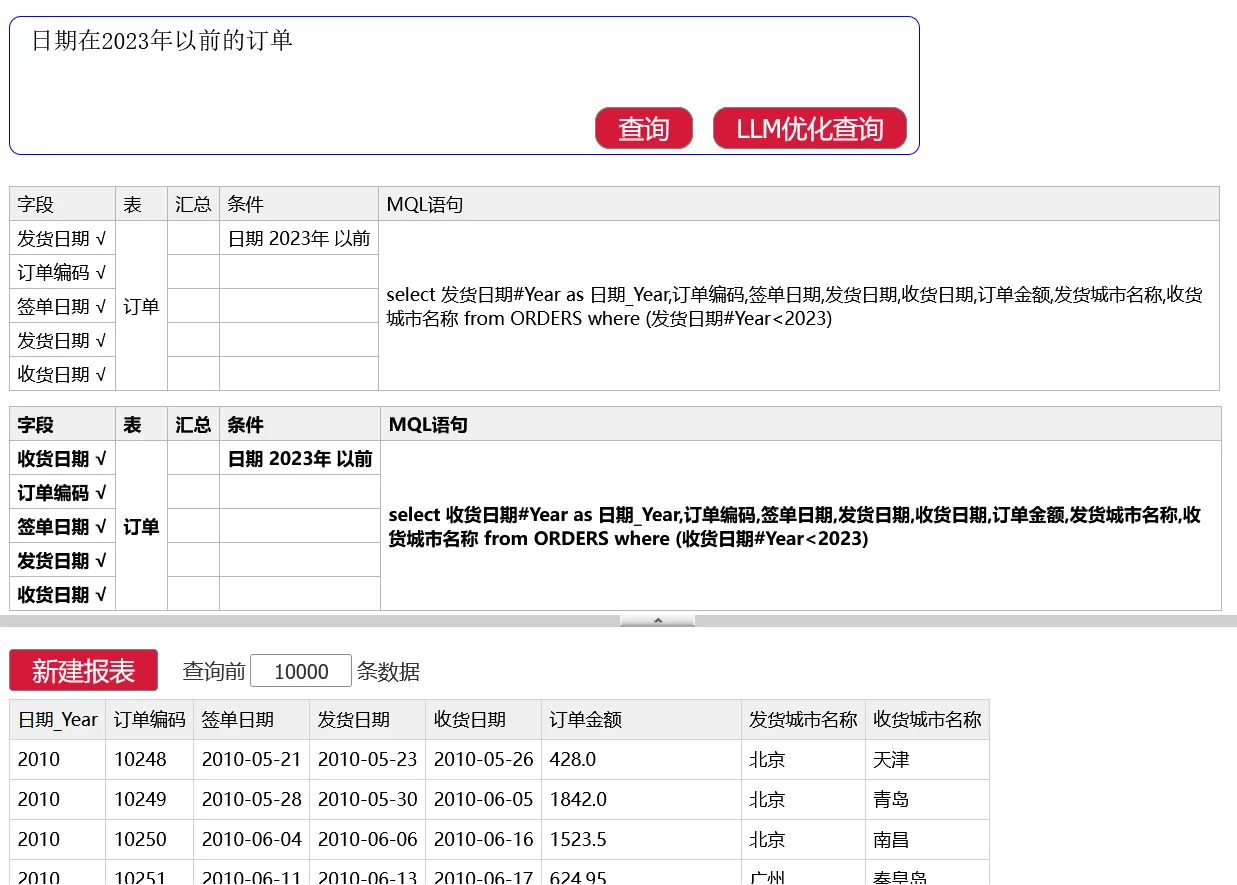
NLQ 组件预先用领域知识建立词典,导入数据结构,定义数据表、字段、维度指标等专用词。词典中还包含比较词、量纲、聚合词、连接词等查询要素。
词典中的词承载了领域知识,构成了领域知识的完美容器。从用户输入的自然语言词句匹配到词典中的词,就是应用领域知识的过程:
打个比方,规则引擎的领域知识是“手册”中的明文规定, 大模型的知识则是“模糊记忆”。假如用户要查“昨日存款总金额”,规则引擎可以明确定义这个指标的计算公式,各个币种要折合成人民币再汇总。缺乏领域知识时,大模型就很可能忽略币种和汇率,按照一般思路对金额求和得出错误的结果。
支持有复杂指标的高级分析
NLQ 组件内置的查询语言 MQL 包括 DQL 和 SPL。DQL 是超维查询语言,一次建模就可以简化表间关联,消除大部分 JOIN 运算,负责把多表关联查询简化为单表查询,大幅提高 AI 式自然语言查询的成功率。
SPL 是创新的结构化、半结构化数据计算编程语言,用于计算留存率、日活月活这些复杂指标,编程效率要比 SQL、Python 提高很多,代码也短的多。
当 MQL 中不涉及复杂指标时,将直接生成 DQL 交由数据库计算。有复杂指标时,MQL 将先用 DQL 取数据后再调用 SPL 编写的自定义函数实现指标计算。
搭配大模型,润乾报表 NLQ 使 ChatBI 不仅好玩而且管用
规则引擎对自然语言的规范性有一定要求,不能使用太随意的词句。我们可以通过适当的培训,让用户习惯用相对规范的自然语言表达,就可以达到很好的使用效果。实际上,用户使用大模型也常常要学习“提示工程”,了解如何写提示词才能得到较好的结果。
NLQ 组件不依赖大模型就可以工作,搭配大模型后还能进一步提升用户体验,可以用更为随意的自然语言来查询数据:

这样做一举两得,可玩性和正确性都能得到保证。
真正的商业智能工具不应该只是让人“玩一下”的新奇玩具,而应该是能够支撑企业决策判断的可靠伙伴。NLQ 组件能做到像 chatBI 一样“好玩易用”,同时还避免了其“不可靠”的缺陷,让 AI 式数据查询告别“玩具”阶段,进入真正的商业应用场景。

