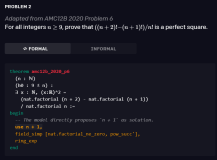
在人工智能领域,大型语言模型(LLM)的飞速发展令人瞩目。然而,如何准确评估这些模型的性能,特别是它们在回答简短问题时的事实性能力,一直是一个挑战。为了解决这个问题,一个由多位研究人员组成的团队推出了名为“Chinese SimpleQA”的全新中文评测集,旨在为LLM的事实性能力提供全面的评估基准。
Chinese SimpleQA具有五个显著特点:中文、多样性、高质量、静态和易于评估。首先,该评测集专注于中文语言,涵盖了六个主要主题和99个不同的子主题,确保了问题的广泛性和代表性。其次,为了保证问题和答案的高质量,研究团队进行了严格的质量控制过程,并确保参考答案是静态的,不会随时间变化。第三,与SimpleQA类似,Chinese SimpleQA的问题和答案都非常简短,使得评估过程更加高效和易于操作。
基于Chinese SimpleQA,研究团队对现有LLM的事实性能力进行了全面评估。结果显示,虽然一些模型在特定领域表现出色,但在整体事实性能力方面仍存在较大差距。特别是,备受瞩目的o1-preview模型在Chinese SimpleQA的评测中仅获得及格分数,这表明即使是最先进的模型也需要进一步提高其在中文语境下的事实性能力。
Chinese SimpleQA的推出对于LLM的发展具有重要意义。首先,它为开发者提供了一个全面、客观的评估工具,帮助他们更好地了解模型在中文语境下的事实性能力,从而有针对性地进行改进。其次,通过与国际知名的SimpleQA基准进行对比,Chinese SimpleQA展示了中文评测集的独特价值和挑战,为未来的研究提供了新的思路和方向。
然而,Chinese SimpleQA也存在一些局限性。首先,由于评测集的规模相对较小,可能无法全面反映LLM在中文语境下的所有能力。其次,评测集的静态特性可能无法适应语言和知识的快速变化,需要定期更新和维护。此外,评测集的易于评估特性虽然提高了效率,但也可能限制了对模型复杂行为的深入理解。
尽管存在这些挑战,Chinese SimpleQA仍然是一个重要的里程碑,为中文LLM的发展提供了宝贵的资源和指导。随着研究的深入和技术的进步,我们有理由相信,未来的LLM将在中文语境下展现出更加出色的事实性能力,为人们的生活和工作带来更多的便利和可能性。
同时,我们也应该意识到,LLM的发展不仅仅是技术层面的突破,更需要关注其对社会、文化和伦理的影响。在推动LLM发展的同时,我们应该加强对其潜在风险的研究和监管,确保人工智能技术能够造福于全人类,而不是成为新的不平等和歧视的来源。只有这样,我们才能真正实现人工智能与人类社会的和谐共生。