个人介绍
李昂 高级数据研发工程师 Apache Doris & Hudi Contributor
业务背景
部门成立早期, 为了应对业务的快速增长, 数仓架构采用了最直接的Lambda架构
1. 对数据新鲜度要求不高的数据, 采用离线数仓做维度建模, 采用每小时调度binlog+每日主键归并的方式实现T+1数据更新
2. 对数据时效性要求比较高的业务, 采用实时架构, 保证增量数据即时更新能力, 另一方面, 为了保证整体上线效率, 存量数据采用离线SQL处理, 以提高计算吞吐量
Lambda整体架构如下

此时的架构存在以下缺陷
1. 逻辑冗余 : 同一个业务方案, 往往有离线与实时两套开发逻辑, 代码复用性低, 需求迭代成本大, 任务交接、项目管理复杂
2. 数据不一致 : 应用层数据来源有多条链路, 在处理逻辑异构的情况下, 存在数据不一致的问题, 且问题排查成本大, 周期长
3. 数据孤岛 : 随着业务增长, 为了应对离线批处理、OLAP分析、C端高并发点查等场景, 引入的存储引擎越来越多, 存在数据孤岛
基于上述Lambda架构存在的缺陷, 我们希望对其作出改进, 实现以下目的
1. 流批一体 : 同一个业务方案, 可以由一套代码逻辑或者核心逻辑一致的SQL实现
2. 数据整合 : 统一离线批处理与OLAP分析的数据存储口径, 同时查询支持SparkSQL与Doris-Multi-Catalog, 打破数据孤岛
选型调研
| 对比项 \ 选型 | Apache Hudi | Apache Iceberg | Apache Paimon |
| 增量实时upsert支持&性能 | 好 | 较好 | 好 |
| 存量离线insert支持&性能 | 好 | 较好 | 好 |
| 增量消费 | 支持 | 依赖Flink State | 支持 |
| 社区活跃度 | Fork 2.4K , Star 4.6K | Fork 1.8K , Star 4.9K | Fork 0.6K , Star 1.4K |
| Doris-Multi-Catalog支持 | 1.2+ 支持 | 1.2+ 支持 | 2.0+ 支持 |
综合考虑以下几点
1. 项目成熟度 : 社区活跃度、国内Committer数量、国内群聊活跃度、各公司最佳实践发文等
2. 数据初始化能力 : 考虑到需要对历史项目进行覆盖, 需要考虑存量数据写入能力
3. 数据更新能力 : 一方面是数据根据PrimaryKey或者UniqueKey的实时Upsert、Delete性能, 另一方面是Compaction性能
4. CDC : 如果需要分层处理, 则要求数据湖作为Flink Source时有产生撤回流的能力
我们最终选定使用Apache Hudi作为数据湖底座
方案选型
业务痛点
实时流 join 是事实数仓的痛点之一, 在我们的场景下, 一条事实数据, 需要与多个维度的数据做关联, 例如一场司法拍卖, 需要关联企业最新名称、董监高、企业性质、上市信息、委托法院、询价评估机构等多个维度;一方面, 公司与董监高是1:N的对应关系, 无法实现一条写入, 多条更新; 另一方面, 企业最新名称的变更, 可能涉及到历史冷数据的更新
方案设计
FlinkSQL+离线修复
方案描述
通过FlinkSQL实现增量数据的计算, 每日因为状态TTL过期或者lookup表变更而没有被命中的数据, 通过凌晨的离线调度进行修复

优点
• SQL开发 : 便于维护
• 架构简洁 : 不涉及其他非必要组件
缺点
• 批流没有完全一体 : 同一逻辑仍然并存FlinkSQL与SparkSQL两种执行方式
• 维护Flink大状态 : 为保证数据尽可能的join到, 需要设置天级甚至周级的TTL
• 时效性下限较低 : 最差仍然可能存在T+1的延迟
MySQL中间表
方案描述 使用MySQL实现数仓分层, 为每张上游表, 都开发lookup逻辑, Hudi只负责做MySQL表的镜像

优点
1. 真正流批一体 : 整个链路彻底摆脱离线逻辑
2. **时效性最高 : **所有更新都能及时反映到下游
缺点
1. 维护成本大 : 每张Hudi表都镜像于一张MySQL表, 链路加长, 复杂度提高
2. 存储冗余 : 每张表各在MySQL与Hudi存一份, 同时, lookup还需要索引支撑, 磁盘占用高
最终结论
1. 因为C端业务的特殊性, 需要MySQL提供点查能力, 所以第二种方案的磁盘冗余处于可接受范围
2. 第一种方案T+1的下限无法被接受, 若提高离线修复的频率, 考虑到Flink已经维护大状态, 或将需要较大的内存开销
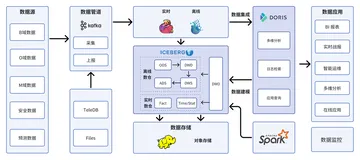
所以最终方案选定为第二种 : MySQL中间表方案, 优化后的整体架构如下

1. ODS层的Hudi充当一个Queryable Kafka, 提供CDC给下游数据
2. 实时ETL通过MySQL完成, 对于每一张新的结果表, 都会原样镜像一份到Hudi
3. Doris与Hive通过读RO表完成与Hudi的统一集成
方案实施
增量实时写入
table.type
根据上述方案, 我们的数据写入是完全镜像于每个flink job的产出MySQL表, 绝大部分表日更新量在50w~300w, 为了保证写入的稳定性, 我们决定采用MOR表
index.type
在选择index的时候, 因为BLOOM随着数据量的上升, 瓶颈出现比较快, 我们的候选方式有FLINK_STATE与BUCKET, 综合考虑以下几点要素
1. 数据量 : 当数据量超过5e, 社区的推荐方案是使用BUCKET, 目前我们常见的表数据量浮动在2e - 4e
2. 维护成本 : 使用Flink_STATE作为index时, 程序重启如果没有从检查点恢复, 需要开始bootstrap重新加载索引
3. 资源占用 : 为保证稳定, FLINK_STATE需要TaskManager划分0.5~1G左右的内存用于运行Rocksdb, 而BUCKET则几乎不需要状态开销
4. 横向扩展 : bucket_num一经确认, 则无法更改(高版本的CONSISTENT_HASHING BUCKET依赖Clustering可以实现动态bucket_num), FLINK_STATE无相关概念
我们最终选择使用BUCKET
1. 它不与RocksDB绑定, 资源占用较低
2. 不需要bootstrap, 便于维护
3. 考虑到数据量与横向扩展, 我们预估数据量为5e~10e, 在该场景下, BUCKET会有更好的表现
同时, 综合参考社区推荐与相关最佳实践的文献,
1. 我们限制每个Parquet文件在2G以内
2. 假设Parquet+Gzip的压缩比率在5:1
3. 预估数据量在10e量级的表
最终, 我们设置bucket_num为128
离线写入
为了快速整合到历史已经上线的表, 存量数据的快速导入同样也是必不可少的, 通过官网学习, 我们设计了两种方案
1. bulk_insert : 优点是速度快, 没有log小文件, 缺点是不够便捷, 需要学习和引入成本
2. 大并发的upsert : 优点是只需要加大并行度, 使用最简单, 缺点是产生大量小文件, 写入完毕后第一次compaction非常耗费资源
在分别对上述2种方案进行测试后, 我们决定采用bulk_insert的方式, 最大的因素还是大并发的Upsert在第一次写入后, 需要的compaction资源非常大, 需要在第一次compaction后再次调整运行资源, 不便于自动化
Compaction
• 同步
• 优点 : 便于维护
• 缺点 : 流量比较大的时候, 干扰写流程; 在存量数据大, 增量数据小的情况下, 资源难以分配
• 异步
• 优点 : 与同步任务隔离, 不干扰写流程, 可自由配置资源
• 缺点 : 对于每个表, 都需要单独维护一个定时任务
综合考虑运维难度与资源分配后, 我们决定采用异步调度的方式, 因为我们读的都是RO表, 所以对Compaction频率和单次Compaction时间都有限制, 目前的方案是Compacion Plan由同步任务生成, Checkpoint Interval为1分钟, 触发策略为15次Commits
成果落地
流批一体
整合实时链路与离线链路, 所有产出表均由实时逻辑产出
• 开发工时由之前普遍的离线2PD+实时3PD提升至实时3PD, 效率提升40%
• 每个单元维护成本由1名实时组同学+1名离线组同学变更为只需要1位实时组同学, 维护成本节约50%
数据整合
配合Doris多源Catalog, 完成数据整合, 打破数据孤岛
• 使司内Doris集群完成存算分离与读写分离, 节约磁盘资源30T+, 减少Tablet维护开销, 稳定性提升70%
• 下线高性能(SSD存储)HBase与GaussDB, 节约成本50w/年
平衡计算压力
之前Hive的每日数据由单独离线集群通过凌晨的多路归并完成多版本合并, 目前只需要一个实时集群
• 退订离线集群70%弹性节点, 节约成本30w/年
经验总结
Checkpoint反压优化
在我们测试写入的时候, Checkpoint时间比较长, 而且会有反压产生, 追踪StreamWriteFunction.processElement()方法, 发现数据缓情况如下

为了将flush的压力分摊开, 我们的方案就是减小buffer

ps : 默认write.task.max.size必须大于228M 最终的参数 :
-- index 'index.type' = 'BUCKET', 'hoodie.bucket.index.num.buckets' = '128', -- write 'write.tasks' = '4', 'write.task.max.size' = '512', 'write.batch.size' = '8', 'write.log_block.size' = '64',
FlinkSQL TIMESTAMP类型兼容性
当表结构中有TIMESTAMP(0)数据类型时, 在使用bulk_insert写入存量数据后, 对接upsert流并进行compaction时, 会报错
Caused by: java.lang.IllegalArgumentException: INT96 is deprecated. As interim enable READ_INT96_AS_FIXED flag to read as byte array.
提交issue https://github.com/apache/hudi/issues/9804 与社区沟通 最终发现是TIMESTAMP类型, 目前只对TIMESTAMP(3)与TIMESTAMP(6)进行了parquet文件与avro文件的类型标准化 解决方法是暂时使用TIMESTAMP(3)替代TIMESTAMP(0)
Hudi Hive Sync Fail
将Hudi表信息同步到Hive原数据时, 遇到报错, 且无法通过修改pom文件依赖解决
java.lang.NoSuchMethodError: org.apache.parquet.schema.Types$PrimitiveBuilder.as(Lorg/apache/parquet/schema/LogicalTypeAnnotation;)Lorg/apache/parquet/schema/Types$Builder 与社区沟通, 发现了相同的问题 https://github.com/apache/hudi/issues/3042 解决方法是修改源码的 packaging/hudi-flink-bundle/pom.xml , 加入 <relocation> <pattern>org.apache.parquet</pattern> <shadedPattern>${flink.bundle.shade.prefix}org.apache.parquet</shadedPattern> </relocation> 并使用 mvn clean install package -Dflink1.17 -Dscala2.12 -DskipTests -Drat.skip=true -Pflink-bundle-shade-hive3 -T 10
手动install源码, 在程序的pom文件中, 使用自己编译的jar包
Hudi Hive Sync 使用 UTC 时区
当使用FlinkSQL TIMESTAMP(3)数据类型写入Hudi, 并开启Hive Sync的时, 查询Hive中的数据, timestamp类型总是比原值多8小时 原因是Hudi写入数据时, 支持UTC时区, 详情见issue https://github.com/apache/hudi/issues/9424 目前的解决方法是写入数据时, 使用FlinkSQL的
CONVERT_TZ 函数 insert into dwd select id,CAST(CONVERT_TZ(CAST(op_ts AS STRING), 'Asia/Shanghai', 'UTC') AS TIMESTAMP(3)) op_ts from ods;
HoodieConfig.setDefaults() NPE
在TaskManager初始化阶段, 偶尔遇到NPE, 且调用栈如下
java.lang.NullPointerException: null at org.apache.hudi.common.config.HoodieConfig.setDefaults(HoodieConfig.java:123)
通过与社区交流, 发现是ReflectionUtils的CLAZZ_CACHE使用HashMap存在线程安全问题 解决方法是引入社区提供的PR : https://github.com/apache/hudi/pull/9786 通过ConcurrentHashMap解除线程安全问题
未来规划
Metric监控
对接Pushgateway、Prometheus与Grafana, 通过图形化更直截了当的监控Hudi内部相关服务、进程的内存与CPU占用情况, 做到
1. 优化资源, 提升程序稳定性
2. 排查潜在不确定因素, 风险预判
3. 接入告警, 加速问题响应
统一元数据管理
目前是采用封装工具类的方式, 让每个开发同学在产出一张结果表的同时, 在同一个job中启动一条Hudi同步链路, 缺少对Hudi同步任务的统一管理与把控, 后续准备对所有Hudi链路迁出, 进行统一的任务整合与元数据管理
引入CONSISTENT_HASHING BUCKET
后续计划中我们希望在1.0发行版中可以正式将CONSISTENT_HASHING BUCKET投入到线上环境, 现在线上许多3e~5e量级的表都是提前按照10e数据量来预估资源与bucket_num, 有资源浪费的情况, 希望可以通过引入一致性hash的bucket索引, 来解决上述问题