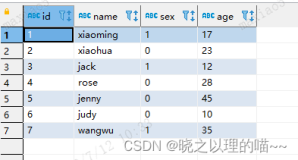
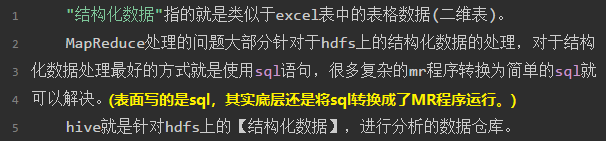
hive出现的原因
Hive 出现的原因主要有以下几个:
- 传统数据仓库无法处理大规模数据:传统的数据仓库通常采用关系型数据库作为底层存储,这种数据库在处理大规模数据时效率较低。
- MapReduce 难以使用:MapReduce 是一种分布式计算框架,它可以用于处理大规模数据,但 MapReduce 的编程模型比较复杂,难以使用。
- 需要一种统一的查询接口:传统的数据仓库和 MapReduce 都提供了数据查询的接口,但这些接口相互独立,难以统一管理。
为了解决这些问题,Facebook 在 2008 年开发了 Hive,Hive 是一种基于 Hadoop 的分布式数据仓库管理系统,它提供了一种 SQL 语法来访问存储在 Hadoop 分布式文件系统 (HDFS) 中的数据。Hive 的出现,解决了传统数据仓库无法处理大规模数据的问题,也简化了 MapReduce 的使用,并提供了一种统一的查询接口。
Hive 的出现,对大数据处理产生了重大影响,它使大数据处理变得更加简单、高效、可扩展。
hive执行过程
- 编写 Hive SQL 程序:首先,需要编写 Hive SQL 程序,这个程序可以通过 Hive CLI、Hive WebUI 等工具进行编写。Hive SQL 程序可以包含各种数据查询语句,例如 select、insert、update、delete 等。
- 提交 Hive SQL 程序:编写完成后,需要将 Hive SQL 程序提交到 Hive 服务器。Hive 服务器会根据 Hive SQL 程序的语法和逻辑进行解析,并生成 MapReduce 任务。
- 执行 MapReduce 任务:MapReduce 任务会将 Hive SQL 程序中的查询语句转换为 Map 和 Reduce 任务。Map 任务会将数据分割成小块,并将数据进行预处理。Reduce 任务会将 Map 任务的输出结果进行合并和聚合。
- 生成查询结果:MapReduce 任务完成后,Hive 服务器会将查询结果生成到 HDFS 中。
- 从 HDFS 中取数:最后,可以通过 Hive CLI、Hive WebUI 等工具从 HDFS 中取出查询结果。
具体来说,Hive SQL 程序的执行过程如下:
- SqlParser 将 Hive SQL 程序解析为 AST(抽象语法树)
- SemanticAnalyzer 对 AST 进行语义分析
- Optimizer 对 AST 进行优化
- Planner 生成执行计划
- Driver 将执行计划发送到 MapReduce 框架
- MapReduce 框架启动 Map 和 Reduce 任务
- Map 和 Reduce 任务生成查询结果
- Hive 服务器将查询结果写入 HDFS
- 用户从 HDFS 中取出查询结果
这个过程可以分为两个阶段:
- Hive SQL 解析和执行阶段:这个阶段是 Hive SQL 程序执行的核心阶段,包括 Hive SQL 程序的解析、优化、计划、执行等过程。
- HDFS 写入和读取阶段:这个阶段是将查询结果写入 HDFS 以及从 HDFS 中取出查询结果的过程。
需要注意的是,Hive SQL 程序的执行过程可以根据 Hive 服务器的配置进行调整。例如,可以通过配置 Hive 的参数来控制 MapReduce 任务的数量和并行度。
hive服务器包含哪些部分
HiveServer2
HiveServer2 是 Hive 的服务器端,它负责接收用户的 Hive SQL 请求,并将这些请求转换为 MapReduce 任务 HiveServer2 的转换步骤如下:
- 解析阶段:HiveServer2 会使用 ANTLR 解析器来解析 Hive SQL 请求,生成抽象语法树 (AST)。AST 是 Hive SQL 请求的结构化表示,它包含了 Hive SQL 请求的语法信息。
- 语义分析阶段:HiveServer2 会使用 SemanticAnalyzer 来对 AST 进行语义分析,检查 Hive SQL 请求的语义是否正确。语义分析会检查 Hive SQL 请求中的变量、常量、表达式等是否正确,以及 Hive SQL 请求是否符合 Hive 的语义规则。
- 优化阶段:HiveServer2 会使用 Optimizer 来对 AST 进行优化,提高 Hive SQL 请求的执行效率。优化会根据 Hive SQL 请求的语义和数据分布情况,生成最优的执行计划。
- 生成执行计划阶段:HiveServer2 会使用 Planner 来生成执行计划。执行计划是 Hive SQL 请求的执行指南,它包含了 MapReduce 任务的数量、分区、输入输出等信息。
- 执行阶段:HiveServer2 会将执行计划发送到 MapReduce 框架,由 MapReduce 框架执行 Hive SQL 请求。MapReduce 框架会将 Hive SQL 请求拆分为多个 Map 和 Reduce 任务,并在多个节点上并行执行。
Hive Metastore
Hive Metastore 是 Hive 的元数据存储,它存储了 Hive 数据库、表、列、分区等元数据信息 Hive Metastore 使用 MySQL 存储元数据,提供以下优点:
可扩展性:MySQL 是一个可扩展的数据库,可以支持大量的并发连接。可靠性:MySQL 支持 ACID 事务,保证了数据的一致性和完整性。性能:MySQL 是一个高性能的数据库,可以满足 Hive 的性能需求。
性能优化
要尽可能减少生成的 MapReduce 任务量,在编写 HiveSQL 时应该注意以下几点:
- 尽量使用 join 而不是 union。 union 操作会导致两个表的数据分别作为 MapReduce 任务的输入,而 join 操作只会生成一个 MapReduce 任务。
- 尽量使用 where 子句来过滤数据。 where 子句可以过滤掉不需要的数据,减少 MapReduce 任务处理的数据量。
- **尽量使用分区表。**分区表可以将数据分布到多个文件中,减少 MapReduce 任务之间的数据 shuffle 量。
- 使用 coalesce 函数合并小文件。 coalesce 函数可以将多个小文件合并为一个大文件,减少 MapReduce 任务之间的数据 shuffle 量。
- 使用 mapjoin 操作。 mapjoin 操作可以将 Map 任务和 Reduce 任务合并为一个任务,减少 MapReduce 任务的数量。
以下是一些具体的示例:
- 使用 join 而不是 union:
# 使用 union,生成两个 MapReduce 任务 select * from table1 union all select * from table2; # 使用 join,生成一个 MapReduce 任务 select * from table1 join table2 on table1.id = table2.id;
- 使用 where 子句来过滤数据:
# 不使用 where 子句,生成一个 MapReduce 任务 select * from table1; # 使用 where 子句,生成一个 MapReduce 任务 select * from table1 where id = 1;
- 使用分区表:
# 使用不分区表,生成一个 MapReduce 任务 select * from table1; # 使用分区表,生成多个 MapReduce 任务 select * from table1 partition(d1, d2, d3);
- 使用 coalesce 函数合并小文件:
# 不使用 coalesce 函数,生成多个 MapReduce 任务 select * from table1; # 使用 coalesce 函数,生成一个 MapReduce 任务 select * from table1 coalesce(1000);
- 使用 mapjoin 操作:
# 不使用 mapjoin 操作,生成两个 MapReduce 任务 select * from table1 join table2 on table1.id = table2.id; # 使用 mapjoin 操作,生成一个 MapReduce 任务 select * from table1 mapjoin table2 on table1.id = table2.id;
总结
也就是说,hive sql通过将sql转换成map reduce任务,使得开发人员可以通过编写sql来替代写map reduce代码,由于sql是通用的,很多数据分析人员都有此技术栈,相对写map reduce代码要容易上手很多。对于同样一个取数需求,hive sql编写方式的不同,会导致Map Reduce任务的创建量不同,所以尽可能编写少的Map Reduce的任务的SQL也是性能优化需要关注的点。