
CIFAR10数据集介绍
CIFAR-10 数据集由10个类别的60000张32x32彩色图像组成,每类6000张图像。有50000张训练图像和10000张测试图像。数据集分为五个训练批次
和一个测试批次,每个批次有10000张图像。测试批次包含从每个类别中随机选择的1000张图像。训练批次包含随机顺序的剩余图像,但一些训练批次
可能包含比另一个类别更多的图像。在它们之间训练批次包含来自每个类的5000张图像。以下是数据集中的类,以及每个类中的10张随机图像:

因为CIFAR10数据集颜色通道有3个,所以卷积层L1的输入通道数量(in_channels)需要设为3。全连接层fc1的输入维度设为400,这与上例设为256有所不同,原因是初始输入数据的形状不一样,经过卷积池化后,输出的数据形状是不一样的。如果是采用动态图开发模型,那么有一种便捷的方式查看中间结果的形状,即在forward()方法中,用print函数把中间结果的形状打印出来。根据中间结果的形状,决定接下来各网络层的参数。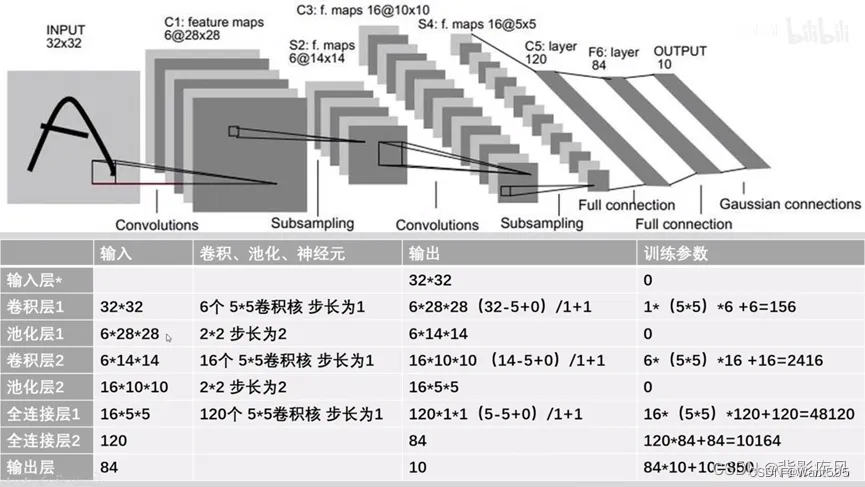
1. 数据的下载
import torch import torchvision.transforms as transforms from torchvision.datasets import CIFAR10 train_dataset = CIFAR10(root="./data/CIFAR10",train=True,transform=transforms.ToTensor(),download=True) test_dataset = CIFAR10(root="./data/CIFAR10", train=False,transform=transforms.ToTensor())
Files already downloaded and verified
train_dataset[0][0].shape
torch.Size([3, 32, 32])
train_dataset[0][1]
6
2.修改模型与前面的参数设置保持一致
from torch import nn
class Lenet5(nn.Module): def __init__(self): super(Lenet5,self).__init__() #1+ 32-5/(1)==28 self.features=nn.Sequential( #定义第一个卷积层 nn.Conv2d(in_channels=3,out_channels=6,kernel_size=(5,5),stride=1), nn.ReLU(), nn.AvgPool2d(kernel_size=2,stride=2), #定义第二个卷积层 nn.Conv2d(in_channels=6,out_channels=16,kernel_size=(5,5),stride=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2,stride=2), ) #定义全连接层 self.classfier=nn.Sequential(nn.Linear(in_features=400,out_features=120), nn.ReLU(), nn.Linear(in_features=120,out_features=84), nn.ReLU(), nn.Linear(in_features=84,out_features=10), ) def forward(self,x): x=self.features(x) x=torch.flatten(x,1) result=self.classfier(x) return result
3. 新建模型
model=Lenet5() device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model=model.to(device)
4. 从数据集中分批量读取数据
#加载数据集 batch_size=32 train_loader= torch.utils.data.DataLoader(train_dataset, batch_size, shuffle=True) test_loader= torch.utils.data.DataLoader(test_dataset, batch_size, shuffle=False) # 类别信息也是需要我们给定的 classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
5. 定义损失函数
from torch import optim
loss_fun=nn.CrossEntropyLoss() loss_lst=[]
6. 定义优化器
optimizer=optim.SGD(params=model.parameters(),lr=0.001,momentum=0.9)
7. 开始训练
import time start_time=time.time() #训练的迭代次数 for epoch in range(10): loss_i=0 for i,(batch_data,batch_label) in enumerate(train_loader): #清空优化器的梯度 optimizer.zero_grad() #模型前向预测 pred=model(batch_data) loss=loss_fun(pred,batch_label) loss_i+=loss loss.backward() optimizer.step() if (i+1)%200==0: print("第%d次训练,第%d批次,损失为%.2f"%(epoch,i,loss_i/200)) loss_i=0 end_time=time.time() print("共训练了%d 秒"%(end_time-start_time))
第0次训练,第199批次,损失为2.30 第0次训练,第399批次,损失为2.30 第0次训练,第599批次,损失为2.30 第0次训练,第799批次,损失为2.30 第0次训练,第999批次,损失为2.30 第0次训练,第1199批次,损失为2.30 第0次训练,第1399批次,损失为2.30 第1次训练,第199批次,损失为2.30 第1次训练,第399批次,损失为2.30 第1次训练,第599批次,损失为2.30 第1次训练,第799批次,损失为2.30 第1次训练,第999批次,损失为2.29 第1次训练,第1199批次,损失为2.27 第1次训练,第1399批次,损失为2.18 第2次训练,第199批次,损失为2.07 第2次训练,第399批次,损失为2.04 第2次训练,第599批次,损失为2.03 第2次训练,第799批次,损失为2.00 第2次训练,第999批次,损失为1.98 第2次训练,第1199批次,损失为1.96 第2次训练,第1399批次,损失为1.95 第3次训练,第199批次,损失为1.89 第3次训练,第399批次,损失为1.86 第3次训练,第599批次,损失为1.84 第3次训练,第799批次,损失为1.80 第3次训练,第999批次,损失为1.75 第3次训练,第1199批次,损失为1.71 第3次训练,第1399批次,损失为1.71 第4次训练,第199批次,损失为1.66 第4次训练,第399批次,损失为1.65 第4次训练,第599批次,损失为1.63 第4次训练,第799批次,损失为1.61 第4次训练,第999批次,损失为1.62 第4次训练,第1199批次,损失为1.60 第4次训练,第1399批次,损失为1.59 第5次训练,第199批次,损失为1.56 第5次训练,第399批次,损失为1.56 第5次训练,第599批次,损失为1.54 第5次训练,第799批次,损失为1.55 第5次训练,第999批次,损失为1.52 第5次训练,第1199批次,损失为1.52 第5次训练,第1399批次,损失为1.49 第6次训练,第199批次,损失为1.50 第6次训练,第399批次,损失为1.47 第6次训练,第599批次,损失为1.46 第6次训练,第799批次,损失为1.47 第6次训练,第999批次,损失为1.46 第6次训练,第1199批次,损失为1.43 第6次训练,第1399批次,损失为1.45 第7次训练,第199批次,损失为1.42 第7次训练,第399批次,损失为1.42 第7次训练,第599批次,损失为1.39 第7次训练,第799批次,损失为1.39 第7次训练,第999批次,损失为1.40 第7次训练,第1199批次,损失为1.40 第7次训练,第1399批次,损失为1.40 第8次训练,第199批次,损失为1.36 第8次训练,第399批次,损失为1.37 第8次训练,第599批次,损失为1.38 第8次训练,第799批次,损失为1.37 第8次训练,第999批次,损失为1.34 第8次训练,第1199批次,损失为1.37 第8次训练,第1399批次,损失为1.35 第9次训练,第199批次,损失为1.31 第9次训练,第399批次,损失为1.31 第9次训练,第599批次,损失为1.31 第9次训练,第799批次,损失为1.31 第9次训练,第999批次,损失为1.34 第9次训练,第1199批次,损失为1.32 第9次训练,第1399批次,损失为1.31 共训练了156 秒
8.测试模型
len(test_dataset)
10000
correct=0 for batch_data,batch_label in test_loader: pred_test=model(batch_data) pred_result=torch.max(pred_test.data,1)[1] correct+=(pred_result==batch_label).sum() print("准确率为:%.2f%%"%(correct/len(test_dataset)))
准确率为:0.53%
9. 手写体图片的可视化
from torchvision import transforms as T
import torch
len(train_dataset)
50000
train_dataset[0][0].shape
torch.Size([3, 32, 32])
import matplotlib.pyplot as plt plt.imshow(train_dataset[0][0][0],cmap="gray") plt.axis('off')
(-0.5, 31.5, 31.5, -0.5)

plt.imshow(train_dataset[0][0][0]) plt.axis('off')
(-0.5, 31.5, 31.5, -0.5)

10. 多幅图片的可视化
from matplotlib import pyplot as plt plt.figure(figsize=(20,15)) cols=10 rows=10 for i in range(0,rows): for j in range(0,cols): idx=j+i*cols plt.subplot(rows,cols,idx+1) plt.imshow(train_dataset[idx][0][0]) plt.axis('off')

import numpy as np img10 = np.stack(list(train_dataset[i][0][0] for i in range(10)), axis=1).reshape(32,320) plt.imshow(img10) plt.axis('off')
(-0.5, 319.5, 31.5, -0.5)

img100 = np.stack( tuple( np.stack( tuple( train_dataset[j*10+i][0][0] for i in range(10) ), axis=1).reshape(32,320) for j in range(10)), axis=0).reshape(320,320) plt.imshow(img100) plt.axis('off')
(-0.5, 319.5, 319.5, -0.5)

