

这个模型产生的契机是,Meta希望推动创意表达,将这种文本到图像的趋势与以前的草图到图像模型相结合,从而产生文本和以草图为条件的图像生成之间的奇妙融合。
这意味着我们可以快速勾勒出一只猫,写出自己想要什么样的图像。遵循草图和文本的指导,这个模型会在几秒钟内,生成我们想要的完美插图。

你可以把这种多模态生成AI方法看作是一个对生成有更多控制的Dall-E模型,因为它还可以将快速草图作为输入。
之所以称它为多模态,是因为它可以将多种模态作为输入,比如文本和图像。相比之下,Dall-E只能从文本生成图像。
为了生成视频,就需要加入时间的维度,因此研究人员在Make-A-Scene模型中添加了时空管道。

加入时间维度后,这个模型就不是只生成一张图片,而是生成16张低分辨率的图片,以创建一个连贯的短视频。
这个方法其实与文本到图像模型类似,但不同之处在于:在常规的二维卷积的基础上,它增加一维卷积。
只是简单地增加了一维卷积,研究人员就能保持预先训练的二维卷积不变的同时,增加一个时间维度。然后,研究人员就可以从头开始训练,重新使用Make-A-Scene图像模型的大部分代码和参数。
在文本到图像方法中使用常规二维卷积模块之后,增加一维卷积模块
同时,研究人员还想用文本输入来指导这个模型,这将与使用CLIP嵌入的图像模型非常相似。
在这种情况下,研究人员是在将文本特征与图像特征混合时,增加空间维度,方法同上:保留Make-A-Scene模型中的注意力模块,并为时间增加一个一维注意力模块——复制粘贴图像生成器模型,为多一个维度重复生成模块,来获得16个初始帧。
在文本到图像方法中使用常规的二维注意力模块之后,增加一维注意力模块
但是只靠这16个初始帧,还不能生成视频。
研究人员需要从这16个主帧中,制作一个高清晰度的视频。他们采用的方法是:访问之前和未来的帧,并同时在时间和空间维度上对它们进行迭代插值。
就这样,他们在这16个初始帧之间,根据前后的帧生成了新的、更大的帧,这样就使运动变得连贯,整体视频变得流畅了。
这是通过一个帧插值网络完成的,它可以采取已有的图像来填补空白,生成中间的信息。在空间维度上,它会做同样的事情:放大图像,填补像素的空白,使图像更加高清。

总而言之,为了生成视频,研究人员微调了一个文本到图像的模型。他们采用了一个已经训练好的强大模型,对它进行调整和训练,让它适应视频。
因为添加了空间和时间模块,只要简单地让模型适应这些新数据就可以了,而不必重新训练它,这就节省了大量的成本。
这种重新训练使用的是未标记的视频,只需要教模型理解视频和视频帧的一致性就可以了,这就可以更简单地建立数据集。

最后,研究人员再次使用了图像优化模型,提高了空间分辨率,并使用了帧插值组件增加了更多的帧,使视频变得流畅。
当然,目前Make-A-Video的结果还存在缺点,就如同文本到图像的模型一样。但我们都知道,AI领域的进展是多么神速。
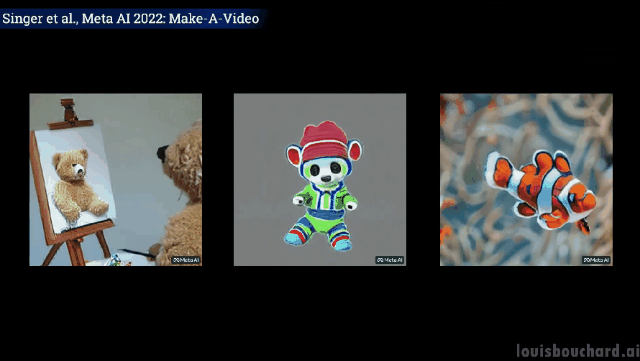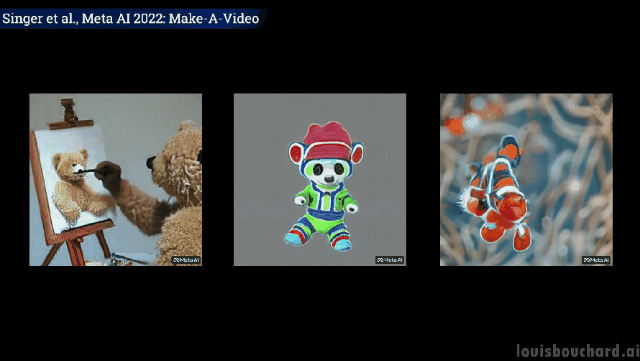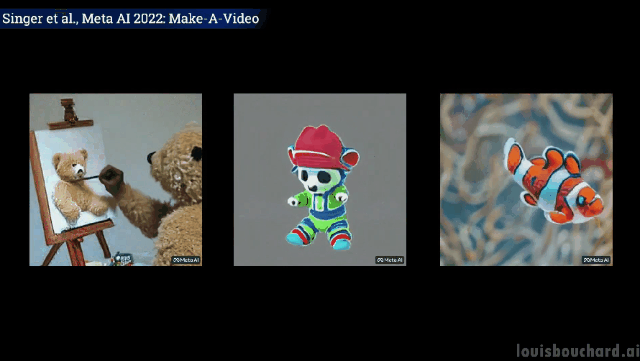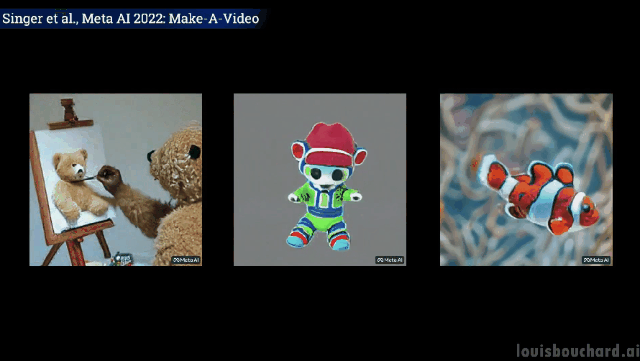
如果你想进一步了解,可以参考链接中Meta AI的论文。社区也正在开发一个PyTorch的实现,如果你想自己实现它,请继续关注。

作者介绍
这篇论文中有多位华人研究人员参与:殷希、安捷、张宋扬、Qiyuan Hu。

殷希,FAIR研究科学家。此前曾供职微软,任Microsoft Cloud and AI 的高级应用科学家。在密歇根州立大学计算机科学与工程系获博士学位,2013年毕业于武汉大学电气工程专业,获学士学位。主要研究领域为多模态理解、大规模目标检测、人脸推理等。

安捷,罗切斯特大学计算机科学系博士生。师从罗杰波教授。此前于 2016 年和 2019 年在北京大学获得学士和硕士学位。研究兴趣包括计算机视觉、深度生成模型和AI+艺术。作为实习生参与了Make-A-Video研究。

张宋扬,罗切斯特大学计算机科学系博士生,师从罗杰波教授。在东南大学获得学士学位,在浙江大学获得硕士学位。研究兴趣包括自然语言矩定位、无监督语法归纳、基于骨架的动作识别等。作为实习生参与了Make-A-Video研究。

Qiyuan Hu,时任FAIR的AI Resident,从事提高人类创造力的多模态生成模型的研究。她在芝加哥大学获得医学物理学博士学位,曾从事AI辅助的医学图像分析工作。现已供职Tempus Labs,任机器学习科学家。
网友大受震撼
前段时间,谷歌等大厂纷纷放出自家的文本到图像模型,如Parti,等等。
有人甚至认为文本到视频生成模型还有一段时间才能到来。
没想到,Meta这次投了一颗重磅炸弹。
其实,同在今天,还有一个文本到视频生成模型Phenaki,目前已提交到ICLR 2023,由于还处于盲审阶段,作者机构还是未知。
网友称,从DALLE到Stable Diffuson再到Make-A-Video,一切来得太快。

参考资料:https://makeavideo.studio/https://makeavideo.studio/Make-A-Video.pdfhttps://www.louisbouchard.ai/make-a-video/


