
AI系统专家/移动视觉/强化学习
2024年12月
 发表了文章
2024-12-07 19:19:59
发表了文章
2024-12-07 19:19:59
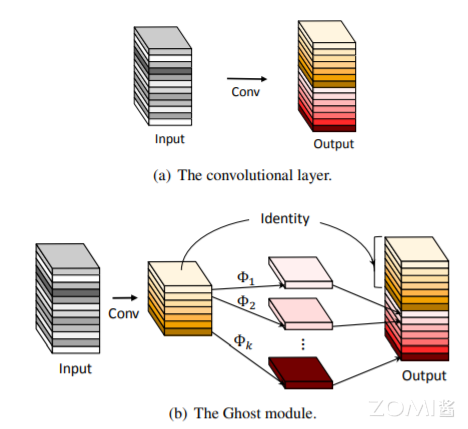 发表了文章
2024-12-07 18:36:03
发表了文章
2024-12-07 18:36:03
 发表了文章
2024-12-07 16:12:55
发表了文章
2024-12-07 16:12:55
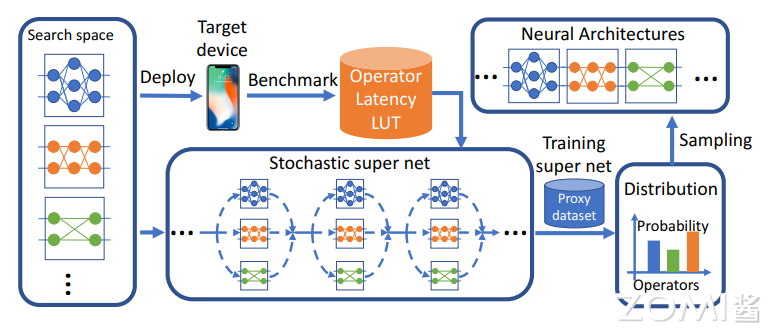 发表了文章
2024-12-06 18:45:31
发表了文章
2024-12-06 18:45:31
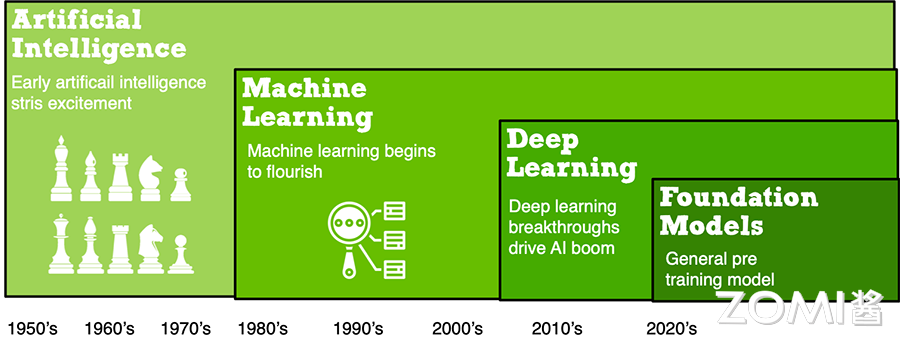 发表了文章
2024-12-06 18:27:54
发表了文章
2024-12-06 18:11:06
发表了文章
2024-12-06 17:40:44
发表了文章
2024-12-06 17:29:32
发表了文章
2024-12-06 17:12:43
发表了文章
2024-12-06 18:27:54
发表了文章
2024-12-06 18:11:06
发表了文章
2024-12-06 17:40:44
发表了文章
2024-12-06 17:29:32
发表了文章
2024-12-06 17:12:43
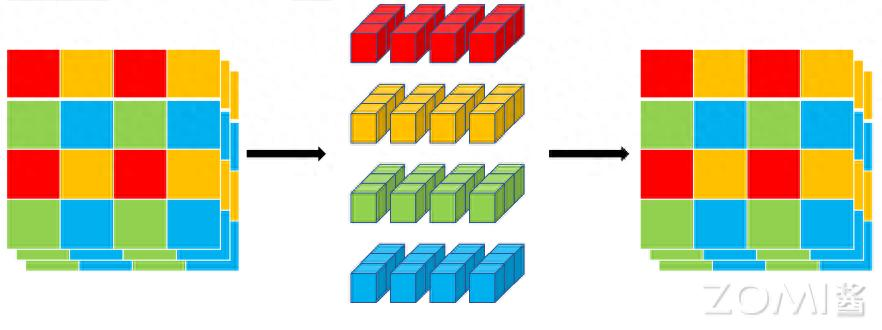 发表了文章
2024-12-06 16:57:11
发表了文章
2024-12-06 16:16:23
发表了文章
2024-12-06 15:42:51
发表了文章
2024-12-06 15:26:29
发表了文章
2024-12-06 15:00:53
发表了文章
2024-12-06 14:53:05
发表了文章
2024-12-05 18:44:36
发表了文章
2024-12-05 17:22:10
发表了文章
2024-12-05 17:16:56
发表了文章
2024-12-05 17:08:11
发表了文章
2024-12-05 17:04:07
发表了文章
2024-12-05 16:50:56
发表了文章
2024-12-06 16:57:11
发表了文章
2024-12-06 16:16:23
发表了文章
2024-12-06 15:42:51
发表了文章
2024-12-06 15:26:29
发表了文章
2024-12-06 15:00:53
发表了文章
2024-12-06 14:53:05
发表了文章
2024-12-05 18:44:36
发表了文章
2024-12-05 17:22:10
发表了文章
2024-12-05 17:16:56
发表了文章
2024-12-05 17:08:11
发表了文章
2024-12-05 17:04:07
发表了文章
2024-12-05 16:50:56
 发表了文章
2024-12-05 16:44:07
发表了文章
2024-12-05 16:36:28
发表了文章
2024-12-05 16:11:46
发表了文章
2024-12-05 15:58:03
发表了文章
2024-12-05 14:48:55
发表了文章
2024-12-05 14:42:13
发表了文章
2024-12-05 14:37:58
发表了文章
2024-12-05 14:28:11
发表了文章
2024-12-05 16:44:07
发表了文章
2024-12-05 16:36:28
发表了文章
2024-12-05 16:11:46
发表了文章
2024-12-05 15:58:03
发表了文章
2024-12-05 14:48:55
发表了文章
2024-12-05 14:42:13
发表了文章
2024-12-05 14:37:58
发表了文章
2024-12-05 14:28:11
 发表了文章
2024-12-05 14:15:49
发表了文章
2024-12-05 14:09:35
发表了文章
2024-12-05 14:05:26
发表了文章
2024-12-05 12:05:09
发表了文章
2024-12-04 17:40:40
发表了文章
2024-12-04 16:55:19
发表了文章
2024-12-04 13:58:51
发表了文章
2024-12-04 11:53:21
发表了文章
2024-12-04 11:47:10
发表了文章
2024-12-02 19:00:01
发表了文章
2024-12-02 18:54:38
发表了文章
2024-12-02 18:04:04
发表了文章
2024-12-02 18:00:48
发表了文章
2024-12-02 17:57:09
发表了文章
2024-12-02 17:04:36
发表了文章
2024-12-02 16:59:15
发表了文章
2024-12-02 16:51:06
发表了文章
2024-12-02 16:28:57
发表了文章
2024-12-02 16:15:42
发表了文章
2024-12-02 15:13:57
发表了文章
2024-12-02 15:09:03
发表了文章
2024-12-19
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-08
发表了文章
2024-12-05 14:15:49
发表了文章
2024-12-05 14:09:35
发表了文章
2024-12-05 14:05:26
发表了文章
2024-12-05 12:05:09
发表了文章
2024-12-04 17:40:40
发表了文章
2024-12-04 16:55:19
发表了文章
2024-12-04 13:58:51
发表了文章
2024-12-04 11:53:21
发表了文章
2024-12-04 11:47:10
发表了文章
2024-12-02 19:00:01
发表了文章
2024-12-02 18:54:38
发表了文章
2024-12-02 18:04:04
发表了文章
2024-12-02 18:00:48
发表了文章
2024-12-02 17:57:09
发表了文章
2024-12-02 17:04:36
发表了文章
2024-12-02 16:59:15
发表了文章
2024-12-02 16:51:06
发表了文章
2024-12-02 16:28:57
发表了文章
2024-12-02 16:15:42
发表了文章
2024-12-02 15:13:57
发表了文章
2024-12-02 15:09:03
发表了文章
2024-12-19
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-09
发表了文章
2024-12-08


