



有信念,没有搞不定的屎

暂时未有相关通用技术能力~
阿里云技能认证
详细说明背景:分区表到底是什么?分区作为传统企业级数据库的特性,早已经在很多大数据和数仓场景中得到广泛应用。基于维基百科的解释,分区是将逻辑数据库或其组成元素如表、表空间等划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性的原因,或者是为了负载平衡。它在分布式数据库管理系统中很流行,其中每个分区可能分布在多个节点上,节点上的用户在分区上执行本地事务。这提高了具有涉及某些数据视图的常规事务的站
升级概述为什么选择升级到PolarDB MySQL 8.0?PolarDB MySQL 8.0.1 (基于官方MySQL 8.0.13内核版本)发布于2019-12-03和PolarDB MySQL 8.0.2(基于官方MySQL 8.0.18内核版本)发布于2020-07-22*,增强了诸多卓越的架构增强和内核能力,为业务提供更灵活的技术解决方案和强大收益的性能提升,主要包括:Serverles
升级概述PolarDB MySQL 5.7/RDS 5.7 向 8.0 升级过程中,经常遇到的问题主要是性能问题、语法兼容性问题,以及周边组件是否的支持,查询的性能问题一般是由于优化器升级导致执 行计划有变,此类问题需要对性能低下的语句进行针对性的性能优化,但性能问题基本不会引发业务报错以及代码的改写问题,此类问题不在本文讨论范围之内。本文主要讨论真实的兼容性问题,此类问题需要在数据库升级过程中,
背景数据库的可用性对于客户是至关重要的,根据CAP理论,分布式和一致性、可用性只能二选一,所以在云原生数据库(依赖多副本)或者分布式TP系统中,大多都选择牺牲一些一致性来保证分布式和可用性,足以看出可用性的地位是及其重要的,所以任何数据库内核都会针对可用性做很多特性改进,比如热备、双活多活、异地灾备、增强一致性协议和主从复制能力、甚至增强备份恢复能力等等。我们了解,影响可用性的无外乎几种场景,如严
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
前沿引用来自百度百科的话术:在数据库技术发展历史上,1970 年是发生伟大转折的一年,因为这一年的6月,IBM的圣约瑟研究实验室的高级研究员Edgar Frank Codd在Communications of ACM 上发表了《A Relational Model of Data for Large Shared Data Banks》。ACM 后来在1983 年把这篇论文列为从1958年以来的2
背景因为曾经从事DB2内核开发工作,所以一直想写一篇关于DB2优化器相关的文章。DB2和Oracle数据库一样,作为老的企业级数据库的代表,从诞生到现在已经多年了。1973年,IBM研究中心启动System R项目,为DB2的诞生打下良好基础。System R 是 IBM 研究部门开发的一种产品,这种原型语言促进了技术的发展并最终在1983年将 DB2 带到了商业市场。在这期间,IBM发表了很多数
背景因为曾经从事DB2内核开发工作,所以一直想写一篇关于DB2优化器相关的文章。DB2和Oracle数据库一样,作为老的企业级数据库的代表,从诞生到现在已经多年了。1973年,IBM研究中心启动System R项目,为DB2的诞生打下良好基础。System R 是 IBM 研究部门开发的一种产品,这种原型语言促进了技术的发展并最终在1983年将 DB2 带到了商业市场。在这期间,IBM发表了很多数
查询分析和调优背景在数据库的使用过程,我们经常会碰到SQL突然变慢,是由于下面导致的问题:选择错误的索引选择错误的连接顺序范围查询使用了不同的快速优化策略子查询选择的执行方式变化半连接选择的策略方式变化如何使用分析工具OPTIMIZER TRACE来理解优化过程和原理来深度分析和调优慢SQL就成为高级DBA的利器。我们先来了解下查询优化整体的过程:该过程主要考虑的因素是访问方式、连接顺序和方法已经
简介: PolarDB MySQL是因云而生的一个数据库系统, 除了云上OLTP场景,大量客户也对PolarDB提出了实时数据分析的性能需求。对此PolarDB技术团队提出了In-Memory Column Index(IMCI)的技术方案,在复杂分析查询场景获得的数百倍的加速效果。本文阐述了IMCI背后技术路线的思考和具体方案的取舍。
云原生的Serverless数据库,正在成为下一个五年的云数据库发展趋势。 近日,在国际数据库顶级会议2021 ACM SIGMOD上,一篇以PolarDB Serverless为主题的论文,被评委会认为指引了下一代数据库服务的发展方向。 这篇题为《PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers》的论文,介绍了阿里云自研数据库PolarDB基于计算存储分离,实现的最新Serverless技术架构研究进展。 PolarDB Serverless论文的录用,标志着阿里云PolarDB数据库在最新一
PolarDB由阿里巴巴自主研发的下一代关系型分布式云原生数据库。在兼容传统数据库生态的同时,突破了传统单机硬件的限制,为用户提供大容量,高性能,极致弹性的数据库服务。
阿里云研发的下一代云原生数据库PolarDB Serverless的论文被ACM SIGMOD录用,标志着阿里云PolarDB数据库在最新一代架构上领先于业界其他云厂商。
PolarDB与开源MySQL及其它类MySQL的产品相比,除了计算与存储分离的先进架构之外,另外一个最核心的技术突破就是开发了其它类MySQL产品没有的并行查询引擎,通过并行查询引擎,PolarDB除了保持自身对OLTP应用的优势之外,还对OLAP的支持能力有了一个质的飞越,遥遥领先于其它类MySQL产品。
本文基于MySQL 8.0.25源码进行分析和总结。这里MySQL Server层指的是MySQL的优化器、执行器部分。我们对MySQL的理解还建立在5.6和5.7版本的理解之上,更多的是对比PostgreSQL或者传统数据库。然而从MySQL 8.0开始,持续每三个月的迭代和重构工作,使得MySQL Server层的整体架构有了质的飞越。下面来看下MySQL最新的架构。
简介我们知道查询优化问题其实是一个搜索问题。基于代价的优化器 ( CBO ) 由三个模块构成:计划空间、搜索算法和代价估计 [1] ,分别负责“看到”最优执行计划和“看准”最优执行计划。如果不能“看准”最优执行计划,那么优化器基本上就是瞎忙活,甚至会产生严重的影响,出现运算量特别大的 SQL ,造成在线业务的抖动甚至崩溃。在上图中,代价估计用一个多项式表示,其系数 c 反应了硬件环境和算子特性,而
背景优化器是关系数据库的重要模块 [1] [2],它决定 SQL 执行计划的好坏。但是,优化器的影响因素很多,由于数据变化和估计准确性等因素,它不能总是产出最优的执行计划 [3] 。选择了不同的执行计划,执行效果差异可能非常大,甚至达到数量级差异,可能对生产系统产生严重影响。虽然学术和业界长期致力于优化器的改进,但对于业务系统而言,在优化器犯错的时候,需要有一些直接有效的干预办法。Optimize
PolarDB 作为阿里云的重磅明星产品,是目前唯一 100% 兼容 MySQL 5.6/5.7/8.0 的云原生数据库产品。 通过多节点集群架构,存储与计算分离,共享存储等一系列创新技术, PolarDB 拥有卓越的计算性能,100TB的存储容量,100%兼容MySQL,1/10其他商用数据库的成本,为阿里云客户以及阿里集团提供强有力的数据库服务。我们的技术不仅服务于千万阿里云线上客户,创造PolarDB系列产品的营收神话,还多次登上数据库顶级会议SIGMOD,VLDB等的世界舞台。
背景MySQL默认的存储引擎是InnoDB,而引入Secondary Engine,用来实现同时支持第二引擎,在同一个MySQL Server上挂多个存储引擎,在支持InnoDB的同时,还可以把数据存放在其他的存储引擎上。 全量的数据都存储在Primary Engine上,某些指定数据在Secondary Engine 上也存放了一份,然后在访问这些数据的时候,会根据系统参数和cost选择存储引擎
概述条件查询被广泛的使用在SQL查询中,复杂条件是否能在执行过程中被优化,比如恒为true或者false的条件,可以合并的条件。另外,由于索引是MySQL访问数据的基本方式,已经追求更快的访问方式,SARGable这个概念已经被我们遗忘了,因为他已经成为默认必要的方法(Search ARGument ABLE)。MySQL如何组织复杂条件并计算各个Ranges所影响到的对应可以使用的索引的代价和使
MySQL Join MySQL本身没有常规意义上的执行计划,一般情况就是通过JOIN和QEP_TAB这两个结构组成。QEP_TAB 的全称是Query Execution Plan Table,这个“Table“可以是物理表、内存表、常量表、子查询的结果表等等。作为整个单独JOIN执行计划载体之前还承担着整个执行路径的调用和流转,但是从8.0.20后,全面的生成了独立的
# MySQL的总体架构 通常我们认为MySQL的整体架构如下, 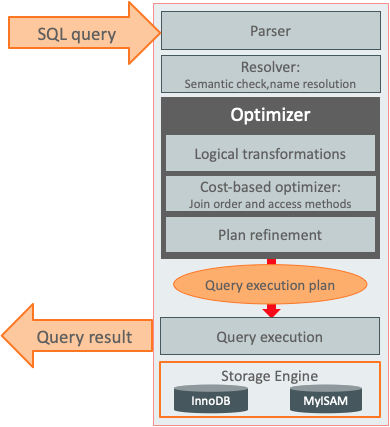 官方10年前开始就一直在致力于优化器代码的重构工作,目的是能确保在SQL的执行过程中有清晰的阶段,包括分离Parse和Resol
MySQL 8.0.21发布了,其中一个新特性是JSON_VALUE()函数。主要的动机是简化JSON数据的索引创建,但是还有更多的原因。
在这篇博客文章中,我将向您展示如何做到这一点,并讨论JSON_TABLE如何启用使用SQL处理JSON数据的新方法。
在MySQL · 特性分析 · 到底是谁执行了FTWL中 文章中,分析了为何出现大量Waiting for global read lock的连接。但是实际操作起来很多gdb版本不支持pset操作,而且连接过多,导致不可能手动打印每一个THD的state,所以笔者写了一个gdb的脚本供大家使用: 首先,先保存下面脚本到/tmp/getlockconn MySQL8.
查询执行 查询计划是由运算符组成的,而运算符实例就是操作符运算在一段数据上的一次调用,任务就是一系列这样的操作符实例的执行序列。 数据库调度 对于每一个查询计划,数据库系统需要决定什么时候,在什么地方,怎么样去执行。
今日议题 背景介绍 用户自定义函数的内联 背景介绍 数据库客户端API 目前我们假设所有的用户逻辑都在客户自己的应用中,然后通过客户端协议如JDBC/ODBC和数据库进行通信获取和存储数据,如下图: 嵌入式数据库逻辑 数据库允许将应用逻辑移植到数据库中减少网络通信的交互次数,这样的好处是高效和可重用。
数据库架构 从整体数据库架构来看,我们可以知道分为网络协议层、优化器层、执行器、存储,详见下图:SQL从客户端发送到数据库服务端,经过解析器、语法语义分析、逻辑优化和物理优化,从一个字符串转换为解析树、语法树到最终的执行计划,那么最终是如何变成机器可以执行的操作呢,本文重点就是来讲执行器的一些重要组件和原理。
--- title: MySQL · 源码分析 · 聚合函数(Aggregate Function)的实现过程 author: 道客 --- ## 总览 聚合函数(Aggregate Function)顾名思义,就是将一组数据进行统一计算,常常用于分析型数据库中,当然在应用中是非常重要不可或缺的函数计算方式。比如我们常见的COUNT/AVG/SUM/MIN/MAX等等。本文主要分析下
2013年10月,创建了两个主要的基础架构:Dynamic Background Workers 和 Dynamic Shared Memory。 2014年11月,Amit Kapila发布了并行顺序扫描(parallel sequential scan)的草案补丁,Robert Haas 发布了并行模式和并行上下文的(parallel mode and parallel contexts)草
今天突然看到一篇文章《方便面销量3年下降80亿包:干掉你的,往往不是你的对手》 ,结合之前MySQL和PostgreSQL的世纪大战,做为一个多年从事数据库行业研发的老司机,禁不住想说些什么。 谈到世纪之争,不如先看下上世纪没有云计算的时代,我们能听到的耳熟能详的经典数据库有
关于时间管理方面的文章、讲座和书籍,总是那么吸引人。因为每个人都希望让自己在有限的时间内做更多的事情,当然这些事情不仅仅是工作、学习和玩乐。其中的方法都是显而易见和容易上手的。我也经常思考,如何去管理时间呢?为什么有了好的方法,仍然无法坚持下去呢?
前言 为什么MySQL InnoDB需要Purge操作?明确这个问题的答案,首先还得从InnoDB的并发机制开始。为了更好的支持并发,InnoDB的多版本一致性读是采用了基于回滚段的的方式。另外,对于更新和删除操作,InnoDB并不是真正的删除原来的记录,而是设置记录的delete mark为1。
翻译来源:https://www.2ndquadrant.com/en/postgresql/postgresql-vs-mysql/ PostgreSQL和MySQL 之间有着根本的区别。
PostgreSQL其实没有只读用户的语法,那么PostgreSQL提供了用户/角色属性来达到只读用户的效果,步骤如下: 1. 创建一个用户名为<readonlyuser>,密码为<your_own_password>的用户 CREATE USER <readonlyuser> ...
 发表了文章
2023-07-13
发表了文章
2023-02-13
发表了文章
2023-01-16
发表了文章
2022-11-27
发表了文章
2022-11-07
发表了文章
2022-11-07
发表了文章
2022-11-07
发表了文章
2022-10-27
发表了文章
2022-10-27
发表了文章
2022-10-27
发表了文章
2022-10-27
发表了文章
2022-10-27
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-17
发表了文章
2022-10-17
发表了文章
2022-10-17
发表了文章
2022-09-05
发表了文章
2022-09-05
发表了文章
2023-07-13
发表了文章
2023-02-13
发表了文章
2023-01-16
发表了文章
2022-11-27
发表了文章
2022-11-07
发表了文章
2022-11-07
发表了文章
2022-11-07
发表了文章
2022-10-27
发表了文章
2022-10-27
发表了文章
2022-10-27
发表了文章
2022-10-27
发表了文章
2022-10-27
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-17
发表了文章
2022-10-17
发表了文章
2022-10-17
发表了文章
2022-09-05
发表了文章
2022-09-05

 回答了问题
2021-01-16
回答了问题
2019-07-17
回答了问题
2021-01-16
回答了问题
2019-07-17
