

Dify-Plus:企业级AI管理核弹!开源方案吊打SaaS,额度+密钥+鉴权系统全面集成
Dify-Plus 是基于 Dify 二次开发的企业级增强版项目,新增用户额度、密钥管理、Web 登录鉴权等功能,优化权限管理,适合企业场景使用。

Qwen2.5-VL-32B:阿里开源多模态核弹!32B模型吊打自家72B,数学推理封神
阿里巴巴最新开源的Qwen2.5-VL-32B多模态模型,在数学推理、视觉问答等任务中超越前代72B版本,支持图像细粒度理解和复杂逻辑分析,已在HuggingFace开源。
AgentSociety:告别纸上谈兵!AI社会模拟器预判政策漏洞:输入新规秒看30年后社会形态
AgentSociety 是清华大学推出的基于大语言模型的社会模拟器,通过构建类人心智的智能体模拟复杂社会行为,适用于政策沙盒测试、危机预警等场景。

Amazon Nova Act:网页操作全自动!亚马逊黑科技把浏览器变AI机器人,请假/订餐/写邮件一键搞定
Amazon Nova Act是亚马逊AGI实验室推出的通用AI代理系统,通过原子化分解网页操作任务并配合Playwright实现高可靠性浏览器自动化,其配套SDK支持开发者快速构建智能体应用原型。
Mureka V6:10语种AI音乐工厂!昆仑万维「声场黑科技」颠覆作曲
昆仑万维推出的Mureka V6 AI音乐创作基座模型,支持10种语言歌词生成和纯音乐创作,通过自研ICL技术实现声场优化,覆盖爵士/电子/流行等多元风格,为音乐爱好者和专业创作者提供高效工具。

OpenBioMed:开源生物医学AI革命!20+工具链破解药物研发「死亡谷」
OpenBioMed 是清华大学智能产业研究院(AIR)和水木分子共同推出的开源平台,专注于 AI 驱动的生物医学研究,提供多模态数据处理、丰富的预训练模型和多样化的计算工具,助力药物研发、精准医疗和多模态理解。

阿里通义开源全模态大语言模型 R1-Omni:情感分析成绩新标杆!推理过程全程透明,准确率飙升200%
R1-Omni 是阿里通义开源的全模态大语言模型,专注于情感识别任务,结合视觉和音频信息,提供可解释的推理过程,显著提升情感识别的准确性和泛化能力。
Kiss3DGen:基于图像扩散模型的3D资产生成框架
Kiss3DGen是一个创新的3D资产生成框架,通过重新利用预训练的2D图像扩散模型,高效生成、编辑和增强3D对象,支持文本到3D、图像到3D等多种生成任务。

ToddlerBot:告别百万经费!6000刀就能造人形机器人,斯坦福开源全套方案普及机器人研究
ToddlerBot 是斯坦福大学推出的低成本开源人形机器人平台,支持强化学习、模仿学习和零样本模拟到现实转移,适用于运动操作研究和多场景应用。
SmolDocling:256M多模态小模型秒转文档!开源OCR效率提升10倍
SmolDocling 是一款轻量级的多模态文档处理模型,能够将图像文档高效转换为结构化文本,支持文本、公式、图表等多种元素识别,适用于学术论文、技术报告等多类型文档。

PhotoDoodle:设计师必备!AI一键生成装饰元素,30+样本复刻风格+无缝融合的开源艺术编辑框架
PhotoDoodle 是由字节跳动、新加坡国立大学等联合推出的艺术化图像编辑框架,能够通过少量样本学习艺术家的独特风格,实现照片涂鸦和装饰性元素生成。
LazyLLM:还在为AI应用开发掉头发?商汤开源智能体低代码开发工具,三行代码部署聊天机器人
LazyLLM 是一个低代码开发平台,可帮助开发者快速构建多智能体大语言模型应用,支持一键部署、跨平台操作和多种复杂功能。

视觉分词器突破天花板!GigaTok:港大字节联手打造3B参数视觉分词器,突破图像生成瓶颈
GigaTok是香港大学与字节跳动联合研发的3B参数视觉分词器,通过语义正则化技术和创新架构设计,解决了图像重建与生成质量间的矛盾,显著提升自回归模型的表示学习能力。

快速生成商业级高清图!SimpleAR:复旦联合字节推出图像生成黑科技,5亿参数秒出高清大图
SimpleAR是复旦大学与字节Seed团队联合研发的自回归图像生成模型,仅用5亿参数即可生成1024×1024分辨率的高质量图像,在GenEval等基准测试中表现优异。

这个AI能把PSD变视频!人物/场景/道具任意组合!SkyReels-A2:昆仑万维推出的可控多元素视频生成框架
SkyReels-A2是昆仑万维推出的创新视频生成框架,通过扩散模型和图像-文本联合嵌入技术,实现多元素精准组合与高质量视频输出。

音乐人狂喜!AbletonMCP:让AI帮你写歌,一句话生成专业编曲,Demo级作品秒出
AbletonMCP 是一个开源项目,通过模型上下文协议(MCP)将 Ableton Live 与 Claude AI 连接,实现 AI 辅助音乐制作,支持创建、修改 MIDI 和音频轨道等操作。

AIMv2:苹果开源多模态视觉模型,自回归预训练革新图像理解
AIMv2 是苹果公司开源的多模态自回归预训练视觉模型,通过图像和文本的深度融合提升视觉模型的性能,适用于多种视觉和多模态任务。

R1-Onevision:开源多模态推理之王!复杂视觉难题一键解析,超越GPT-4V
R1-Onevision 是一款开源的多模态视觉推理模型,基于 Qwen2.5-VL 微调,专注于复杂视觉推理任务。它通过整合视觉和文本数据,能够在数学、科学、深度图像理解和逻辑推理等领域表现出色,并在多项基准测试中超越了 Qwen2.5-VL-7B 和 GPT-4V 等模型。
MeteoRA:多任务AI框架革新!动态切换+MoE架构,推理效率提升200%
MeteoRA 是南京大学推出的多任务嵌入框架,基于 LoRA 和 MoE 架构,支持动态任务切换与高效推理。

HealthGPT:你的AI医疗助手上线了:支持X光到病理切片,诊断建议+报告生成全自动
HealthGPT 是浙江大学联合阿里巴巴等机构开发的先进医学视觉语言模型,具备医学图像分析、诊断辅助和个性化治疗方案建议等功能。

导演失业预警!Seaweed-7B:字节7B参数模型让剧本自动变电影!20秒长镜头丝滑生成
Seaweed-7B是字节跳动推出的70亿参数视频生成模型,支持从文本、图像或音频生成高质量视频内容,具备长镜头生成、实时渲染等先进特性,通过优化架构显著降低计算成本。

月之暗面开源16B轻量级多模态视觉语言模型!Kimi-VL:推理仅需激活2.8B,支持128K上下文与高分辨率输入
月之暗面开源的Kimi-VL采用混合专家架构,总参数量16B推理时仅激活2.8B,支持128K上下文窗口与高分辨率视觉输入,通过长链推理微调和强化学习实现复杂任务处理能力。

从商业海报到二次元插画多风格通吃!HiDream-I1:智象未来开源文生图模型,17亿参数秒出艺术大作
HiDream-I1是智象未来团队推出的开源图像生成模型,采用扩散模型技术和混合专家架构,在图像质量、提示词遵循能力等方面表现优异,支持多种风格生成。

OmniAlign-V:20万高质量多模态数据集开源,让AI模型真正对齐人类偏好
OmniAlign-V 是由上海交通大学、上海AI Lab等机构联合推出的高质量多模态数据集,旨在提升多模态大语言模型与人类偏好的对齐能力。该数据集包含约20万个多模态训练样本,涵盖自然图像和信息图表,结合开放式问答对,支持知识问答、推理任务和创造性任务。

CogView4:智谱开源中文文生图新标杆,中文海报+任意分辨率一键生成
CogView4 是智谱推出的开源文生图模型,支持中英双语输入和任意分辨率图像生成,特别优化了中文文字生成能力,适合广告、创意设计等场景。
结合DeepSeek-R1强化学习方法的视觉模型!VLM-R1:输入描述就能精确定位图像目标
VLM-R1 是基于强化学习技术的视觉语言模型,通过自然语言指令精确定位图像目标,支持复杂场景推理与高效训练。

CLaMP 3:音乐搜索AI革命!多模态AI能听懂乐谱/MIDI/音频,用27国语言搜索全球音乐
CLaMP 3是由清华大学团队开发的多模态、多语言音乐信息检索框架,支持27种语言,能够进行跨模态音乐检索、零样本分类和音乐推荐等任务。

傅利叶开源人形机器人,提供完整的开源套件!Fourier N1:具备23个自由度和3.5米/秒运动能力
傅利叶推出的开源人形机器人N1搭载自研动力系统与多模态交互模块,具备23个自由度和3.5米/秒运动能力,提供完整开源套件助力开发者验证算法。

SpatialVLA:上海AI Lab联合上科大推出的空间具身通用操作模型
SpatialVLA 是由上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构共同推出的新型空间具身通用操作模型,基于百万真实数据预训练,赋予机器人强大的3D空间理解能力,支持跨平台泛化控制。

多模态模型卷王诞生!InternVL3:上海AI Lab开源78B多模态大模型,支持图文视频全解析!
上海人工智能实验室开源的InternVL3系列多模态大语言模型,通过原生多模态预训练方法实现文本、图像、视频的统一处理,支持从1B到78B共7种参数规模。
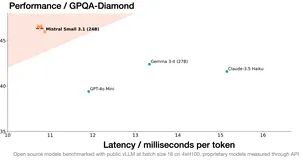
Mistral Small 3.1:240亿参数多模态黑马!128k长文本+图像分析,推理速度150token/秒
Mistral Small 3.1 是 Mistral AI 开源的多模态人工智能模型,具备 240 亿参数,支持文本和图像处理,推理速度快,适合多种应用场景。

昆仑万维开源 Skywork R1V:开源多模态推理核弹!视觉链式分析超越人类专家
Skywork R1V 是昆仑万维开源的多模态思维链推理模型,具备强大的视觉链式推理能力,能够在多个权威基准测试中取得领先成绩,推动多模态推理模型的发展。

快速切换多种画风!FlexIP:腾讯开源双适配器图像生成框架,精准平衡身份保持与个性化编辑
本文解析腾讯最新开源的FlexIP图像框架,其通过双适配器架构与动态门控机制实现身份保持与个性化编辑的精准平衡,在CLIP-I指标上取得0.873的高分验证了技术突破。

OmniCam:浙大联合上海交大推出多模态视频生成框架,虚拟导演打造百万级影视运镜
OmniCam是由浙江大学与上海交通大学联合研发的多模态视频生成框架,通过LLM与视频扩散模型结合实现高质量视频生成,支持文本、轨迹和图像等多种输入模态。
MV-MATH:中科院开源多模态数学推理基准,多视觉场景评估新标杆
MV-MATH 是中科院自动化所推出的多模态数学推理基准数据集,旨在评估多模态大语言模型在多视觉场景中的数学推理能力。该数据集包含2009个高质量的数学问题,涵盖11个数学领域和3个难度级别,适用于智能辅导系统和多模态学习研究。

PodAgent:港中文、微软、小红书联合推出的播客生成框架
PodAgent 是由香港中文大学、微软和小红书联合推出的播客生成框架,基于多智能体协作系统,自动生成高质量对话内容,支持声音角色匹配和语音合成,适用于媒体、教育、企业推广等多个场景。





