丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
热门
SEND模型如何解决重叠语音的说话人识别问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
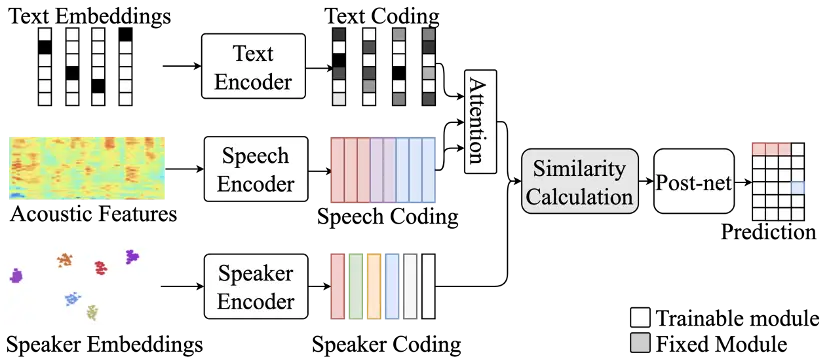
基于嵌入码的说话人日志模型(Speaker Embedding-aware Neural Diarization,SEND)。该模型通过动态维护说话人嵌入码记忆单元的数量,提高了对说话人数量的灵活性,既能够应对较多的说话人也不需要提前设定说话人数量;另外,通过幂集编码将重叠语音的说话人日志任务由多标签预测问题重新建模为单标签分类问题,大大提高了对重叠语音的说话人识别率。我们还利用语音中丰富的语义信息,将所提出的方法进行扩展,进一步提高了模型的识别性能。
——参考链接。