丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
热门
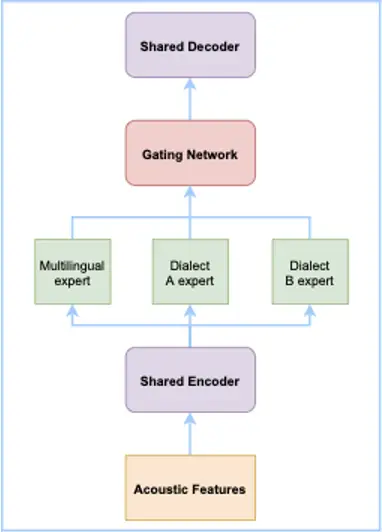
针对方言识别问题,达摩院语音实验室提出了什么解决方案?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
借鉴了中英文自由说模型的方案,对每一种方言设计一个专家网络,同时考虑到每种方言的发音相似性,我们增加了一个共享的专家网络来学习方言之间的共性。和中英文自由说模型类似,最后通过一个门控模块对每个专家网络的输出进行加权。
考虑到方言种类比较多,每个专家网络通过简单的两层线性层来建模。进一步我们结合达摩院语音实验室自研的 SAN-M 网络,打造了达摩院语音实验室新一代的端到端方言自由说语音识别系统。在不需要提供方言id的情况下,用一个模型识别十四种常用方言,并且保证纯中文相对于单语模型的识别性能基本不降。
——参考链接。