
如何判断模型输出是否完整?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
模型训练过程:
监控训练过程中的日志输出,查看是否有错误或警告信息。
检查训练过程中的各项指标(如损失函数值、准确率等)是否符合预期。
模型评估指标:
使用测试数据集对模型进行评估,检查评估指标(如精确度、召回率、F1分数等)是否达到预期。
对比模型在训练集和测试集上的表现,确保没有过拟合或欠拟合。
输出结果检查:
检查模型输出的结果是否符合预期的格式和类型。
如果是分类模型,检查输出的类别标签是否正确;如果是回归模型,检查输出的数值是否在合理的范围内。
在判断模型输出是否完整时,可以从以下几个方面进行考虑:
完整性检查:首先,需要明确模型输出的完整性标准。这通常涉及到输出数据的结构、字段、格式等方面是否符合预期。例如,对于表格数据,可以检查行数、列数是否与预期相符;对于文本数据,可以检查是否包含必要的关键词或短语等。
异常值检测:在模型输出中,可能会存在一些异常值或离群点。这些值可能由于数据输入错误、模型训练不充分等原因产生。因此,在判断输出完整性时,也需要关注这些异常值,并采取相应的处理措施。
缺失值处理:如果模型输出中存在缺失值,那么输出就不完整。此时,需要根据具体情况选择合适的缺失值处理方法,如填充、删除等,以确保输出的完整性。
逻辑一致性检验:对于某些复杂的模型输出,可能需要进行逻辑一致性检验。例如,对于分类模型的输出结果,需要确保每个样本都被正确地分配到了一个类别中,而没有出现重叠或遗漏的情况。
可视化辅助:有时候,通过可视化手段可以更直观地判断模型输出的完整性。例如,绘制柱状图、饼图等图表来展示输出数据的分布情况,从而发现潜在的问题。
对比分析:如果有多个模型或算法对同一数据集进行预测,可以通过对比它们的输出结果来判断单个模型输出的完整性。如果某个模型的输出与其他模型存在显著差异,那么该模型的输出可能存在问题。
专家评审:对于一些专业性很强的领域,可以邀请领域内的专家对模型输出进行评审。他们凭借丰富的经验和专业知识,能够更准确地判断输出的完整性和准确性。
需要注意的是,判断模型输出是否完整是一个相对主观的过程,不同的人可能会有不同的看法。因此,在实际操作中,需要结合具体情况和需求来制定合适的判断标准和方法。同时,随着模型的不断优化和更新,判断标准和方法也可能需要相应地进行调整和改进。
首先,我们需要明确一点:所有的模型输出结果都不可能做到100%准确。 这是因为深度学习模型本身存在一定的随机性和模糊性,同时训练数据也可能存在一些偏差和噪声。 因此,我们不能期望模型总是给出完全正确的答案。
在进行输出结果检查时,我们需要关注以下几个方面:
语法正确性:模型输出的文本是否符合语法规则?如果输出的文本存在语法错误,那么就需要对模型进行调整和优化。同时,我们也可以使用语法检查工具来辅助我们进行输出结果检查。
流畅性和可读性:模型输出的文本是否流畅和易于阅读?如果输出的文本存在语义和语法错误,那么就需要对模型进行调整和优化。同时,我们也可以使用自然语言处理技术来辅助我们进行输出结果检查。
特殊情况处理:对于一些特殊情况,例如输入数据存在异常值或者缺失值等,模型是否能够正确处理?如果模型不能正确处理这些特殊情况,那么就需要对模型进行调整和优化。
在进行输出结果检查时,我们还需要注意以下几点:
一定要重视数据的质量和多样性。训练数据的质量和多样性直接影响了模型的性能和输出结果的质量。因此,我们需要对训练数据进行严格的筛选和清洗,同时也要尽可能地增加数据的多样性。
一定要对模型的输出结果进行充分的测试和评估。我们可以通过对比模型的输出结果和人工结果的差异来评估模型的性能和输出结果的质量。同时,我们也可以通过对比不同模型之间的输出结果来选择最优的模型。
一定要对模型的参数和超参数进行合理的调整和优化。模型的参数和超参数直接影响了模型的性能和输出结果的质量。因此,我们需要对模型的参数和超参数进行合理的调整和优化,以达到最优的性能和输出结果质量。
总之,输出结果检查是使用大型语言模型构建系统过程中非常重要的一环。只有经过严格的输出结果检查和评估,我们才能确保模型的性能和输出结果的质量达到最优水平。同时,我们也需要不断地对模型进行调整和优化,以适应不同的应用场景和需求。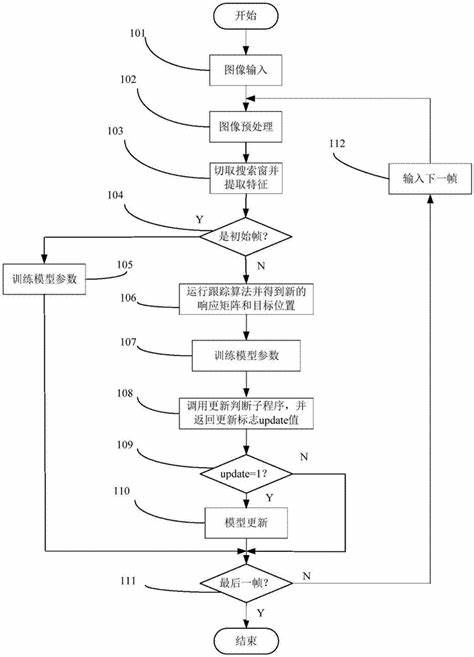
——参考链接。
判断模型输出是否完整涉及多个方面,具体取决于模型的类型、应用场景以及预期的输出格式。以下是一些通用的方法和步骤,可以帮助你评估模型输出的完整性:
对比预期输出:
检查输出格式:
验证数据完整性:
使用校验和或哈希值:
分析异常和错误:
使用测试数据集:
考虑模型性能:
咨询领域专家:
持续监控和反馈:
请注意,以上步骤并非严格意义上的顺序或清单,而是应该根据实际情况灵活应用的方法。对于特定的模型和应用场景,可能需要额外的步骤或方法来验证输出的完整性。
模型服务的输出是否完整通常可以通过检查返回的HTTP状态码和错误信息来判断。若接口调用返回的HTTP状态码为200,并且status和code字段表明请求成功,那么模型输出就是完整的。如果status和message内容表示成功,即输出无误。如有错误代码,参考提供的错误码信息来调试问题。记得检查返回的data字段,它应包含模型的响应内容。
判断模型输出是否完整通常取决于你的具体应用场景和模型的类型。以下是一些常见的方法来检查模型输出的完整性:
确保模型输出的数据符合预期的格式和内容。
def is_output_complete(output):
required_fields = ['field1', 'field2', 'field3']
for field in required_fields:
if field not in output:
return False
# 检查数据类型
if not isinstance(output['field1'], int):
return False
# 检查数据范围
if not (0 <= output['field1'] <= 100):
return False
# 检查数据长度
if len(output['field2']) != 10:
return False
return True
对于一些特定类型的模型,可以使用校验算法来确保输出的完整性。
import hashlib
def calculate_hash(data):
return hashlib.sha256(json.dumps(data, sort_keys=True).encode('utf-8')).hexdigest()
expected_hash = "your_expected_hash_value"
output = your_model.generate_output()
actual_hash = calculate_hash(output)
if actual_hash == expected_hash:
print("Output is complete and correct.")
else:
print("Output is incomplete or incorrect.")
确保模型输出与输入或其他相关数据保持一致。
def check_consistency(input_data, output_data):
# 检查输入输出的一致性
if input_data['key'] != output_data['key']:
return False
# 其他一致性检查
if input_data['value'] * 2 != output_data['value']:
return False
return True
在数据库中,可以使用完整性约束(如外键、唯一约束等)来确保数据的完整性。
-- 创建表时添加外键约束
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
-- 创建表时添加唯一约束
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50) UNIQUE
);
通过日志记录和监控系统来跟踪模型输出的情况,及时发现并处理不完整的输出。
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def process_output(output):
if not is_output_complete(output):
logger.error(f"Incomplete output: {output}")
# 发送警报
send_alert()
else:
logger.info(f"Complete output: {output}")
# 处理完整的输出
handle_complete_output(output)
编写单元测试和集成测试来验证模型输出的完整性。
import unittest
class TestModelOutput(unittest.TestCase):
def test_output_completeness(self):
output = your_model.generate_output()
self.assertTrue(is_output_complete(output))
if __name__ == '__main__':
unittest.main()
根据你的具体需求和应用场景,选择合适的方法来判断模型输出是否完整。常见的方法包括数据验证、完整性校验、一致性检查、完整性约束、日志和监控以及单元测试和集成测试。通过这些方法,你可以有效地确保模型输出的完整性和正确性。
模型评估主要理论、评估方法及性能度量
3.1 模型评估的引出及思考
精度与错误率
我们通常将分类错误的样本数占总样本数的比例称为“错误率”,也即当在m个样本中有α个样本分类错误时,错误率E等于α除以m。相应地,1减去错误率就是精度,也即“精度=1-错误率”。更一般地,我们将学习器的实际预测输出与样本的真实输出之间的差异称为“误差”。
训练误差和泛化误差——我要得到什么?
我们还可以将学习器在训练集上的误差称为“训练误差”或“经验误差”,在新样本上的误差称为“泛化误差”。显然,我们希望得到泛化误差小的学习器。然而,由于我们事先并不知道新样本是什么样的,所以实际上我们只能尽力使经验误差最小化。
精度越大越好?
在很多情况下,我们可以学习到经验误差很小、在训练集上表现很好的学习器。
例如,甚至可以对所有训练样本都分类正确,也即分类错误率为零,分类精度为100%。然而,这样的学习器是否是我们想要的呢?遗憾的是,这样的学习器在多数情况下都不理想。


