
在OpenSearch中设计这种一对多(1:N)关联的表结构时,由于OpenSearch直接支持的主辅表关联仅限于N:1或1:1关系,如何调整数据模型以适应这一限制?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是的只支持N:1或1:1,现在没办法实现1:N
参考链接
https://developer.aliyun.com/ask/638451?spm=a2c6h.13066369.0.0.56493153fGrPwb
https://help.aliyun.com/zh/open-search/industry-algorithm-edition/join-operations-on-multiple-tables
回答不易请采纳
调整数据模型以适应特定限制通常涉及对现有数据结构进行优化和重构,以便更好地满足性能、存储或业务需求。以下是一些常见的策略:
规范化与反规范化:
规范化:将数据分解成多个相关表,以减少冗余并提高数据的一致性。这有助于维护数据的完整性,但可能会增加查询的复杂性。
反规范化:通过合并表或添加冗余字段来减少查询时的连接操作,从而提高查询性能。这可能会导致数据冗余,但可以加快读取速度。
索引优化:
创建适当的索引以加速查询操作。确保在经常用于搜索、排序或连接的列上建立索引。
避免过多或不必要的索引,因为过多的索引会增加写操作的开销。
分区:
对于大型表,可以使用分区技术将数据分割成更小、更易管理的部分。例如,按日期、地区或其他逻辑划分数据,可以提高查询和维护的效率。
缓存:
使用缓存机制(如Redis、Memcached)存储频繁访问的数据,减少数据库的负载。
数据压缩:
对存储的数据进行压缩,以减少存储空间的使用。某些数据库系统支持内置的数据压缩功能。
选择合适的数据类型:
根据实际需要选择最合适的数据类型,避免使用过大的数据类型,以节省存储空间和提高处理效率。
归档历史数据:
将不常访问的历史数据迁移到归档存储中,以保持主数据库的性能和响应速度。
分库分表:
对于非常大的数据集,可以考虑将数据水平拆分到多个数据库实例或表中,以分散负载和提高可扩展性。
使用NoSQL数据库:
对于某些类型的应用,NoSQL数据库(如MongoDB、Cassandra)可能比传统的关系型数据库更适合,因为它们提供了更高的灵活性和可扩展性。
定期审查和优化:
定期审查数据模型和数据库性能,根据实际使用情况进行调整和优化。
在调整数据模型时,重要的是要权衡各种因素,包括性能、可维护性、开发成本和业务需求。建议在进行重大更改之前,先在测试环境中验证调整的效果,以确保不会对现有系统造成负面影响。
OpenSearch支持多表join,但是数据表关联关系上有一定的限制:
目前主辅表,数据关联仅支持 N:1 或 1:1 的关系,不支持 1:N(即多表数据关联关系中,多的一方只能是主表)。
主辅表需通过应用表外键与辅表主键进行数据关联,且表外键只能关联辅表主键。
最多只支持3层关联。辅表最多添加10张。
只能配置一张主表。
注意OpenSearch中的表需存在关联关系,如需添加独立的表进行查询建议购入新的实例进行配置。
多表join的配置可参考:配置多表join。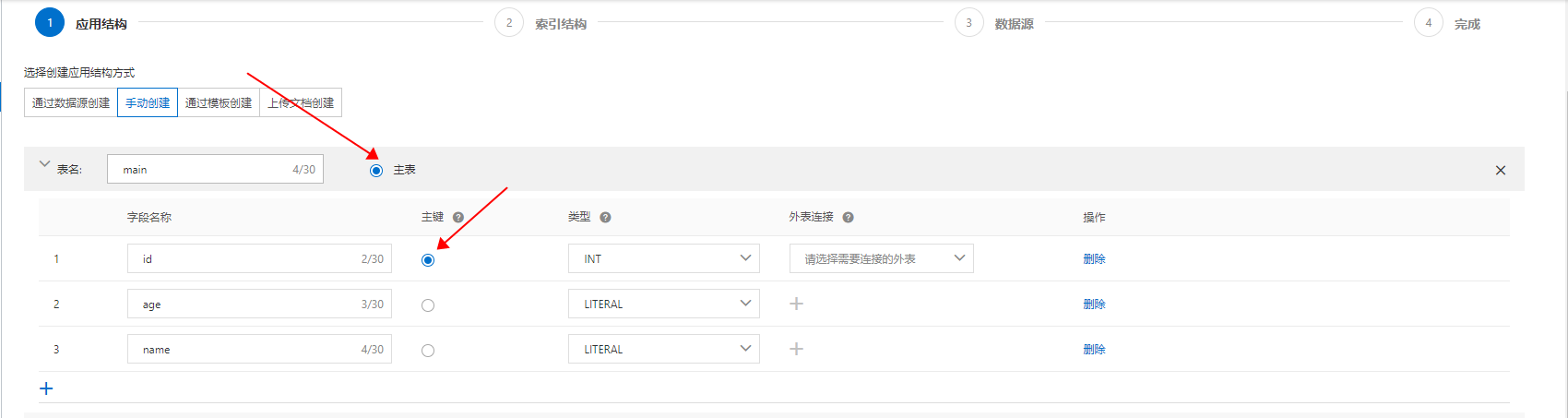
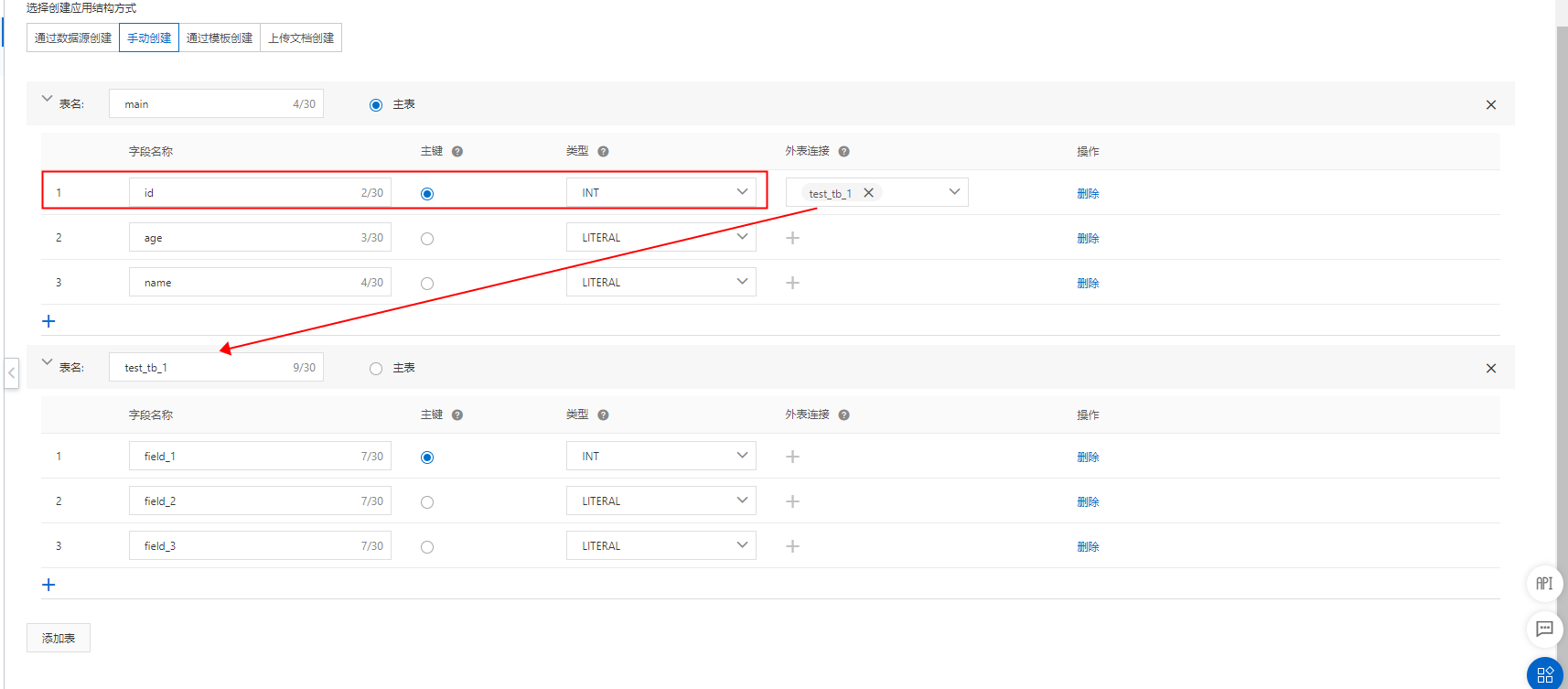
如果您配置了多张表,并且主辅表的Join关系为1:N,可能引发如下问题:
主表主键 辅表主键 辅表字段xxx
1 1 1
1 1 2
1 1 3
OpenSearch在join的时候时候left join,如果 主辅表的Join关系为1:N, OpenSearch只会join最新辅表数据,并展示。如上述,如果辅表字段xxx 最新的是3,那么最终查询出来的结果只有1一条,辅表字段xxx为3,如果更新了 辅表字段xxx 为2 的记录,那么此次的join结果也会改变。因此不建议用户配置 主辅表的Join关系为1:N。
——参考链接。
OpenSearch当前不直接支持1:N(多对一)关联关系。不过,有变通的办法。您可以将数据重新组织,比如将一个主表拆分为多个具有1:1关系的子表,使得每个子表与原来的从属表形成1:1的关系。这样通过多次1:1关联,您可以模拟出1:N的效果。别忘了,每张主表最多可以有10张辅表,并且join层数不超过2层。确保字段结构一致,并注意更新延迟问题,特别是当N值较大时。
在OpenSearch(以前称为Elasticsearch)中,由于其直接支持的主辅表关联仅限于N:1或1:1关系,对于一对多(1:N)的关系处理需要采取一些策略来适应这种限制。下面是一些常见的方法来调整数据模型以适应这一限制:
这是最直接的方法之一。如果你的一对多关系中的“多”端数据量不是特别大,并且这些数据不经常独立更新,你可以将“多”端的数据嵌入到“一”端的文档中。例如,如果有一个user和多个order的关系,你可以在每个user文档中包含一个数组字段,该字段存储了与用户相关的所有订单信息。
示例:
{
"user_id": "u123",
"name": "John Doe",
"orders": [
{
"order_id": "o456",
"amount": 100,
"date": "2023-01-01"
},
{
"order_id": "o789",
"amount": 200,
"date": "2023-01-02"
}
]
}
OpenSearch/Elasticsearch提供了父子文档的功能,允许在一个索引内建立父子关系。这种方式适合于需要维持复杂查询和聚合操作的情况。通过使用join字段类型,可以定义两个不同类型的文档之间的关系。
创建索引时定义父子关系:
PUT /my_index
{
"mappings": {
"properties": {
"type": { "type": "keyword" },
"join_field": {
"type": "join",
"relations": {
"user": "order"
}
}
}
}
}
添加父文档:
POST /my_index/_doc
{
"type": "user",
"join_field": {
"name": "user"
},
"user_id": "u123",
"name": "John Doe"
}
添加子文档:
POST /my_index/_doc
{
"type": "order",
"join_field": {
"name": "order",
"parent": "u123"
},
"order_id": "o456",
"amount": 100,
"date": "2023-01-01"
}
另一种方式是利用外部ID进行关联。即,在“多”端的每个文档中保存一个指向“一”端文档的引用。这种方法适用于当你需要保持两边文档的独立性,或者当“多”端的数据量非常大时。
示例:
# User文档
{
"user_id": "u123",
"name": "John Doe"
}
# Order文档
{
"order_id": "o456",
"amount": 100,
"date": "2023-01-01",
"user_id": "u123"
}
在这种情况下,可以通过user_id来查询所有属于某个用户的订单。
选择哪种方法取决于你的具体需求,包括性能要求、查询模式以及数据规模等因素。每种方法都有其优缺点,你需要根据实际情况做出最佳选择。
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。


