datawork是否支持本地化部署?有资料介绍么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
DataWorks是一款大数据开发与管理平台,可以支持多种部署方式,包括公有云部署、私有云部署和本地化部署。
在DataWorks中,本地化部署是指将DataWorks部署在用户的本地服务器上,用户可以通过本地服务器访问DataWorks的功能。本地化部署可以提供更高的数据安全性和隐私保护,并且可以更好地控制资源使用和成本。
以下是一些本地化部署的常见方式:
Docker容器部署:
在DataWorks中,您可以使用Docker容器部署DataWorks。Docker容器是一种轻量级的操作系统虚拟化技术,可以将应用程序和依赖项打包在一个容器中,并可以方便地在不同环境中进行部署。
Kubernetes集群部署:
在DataWorks中,您可以使用Kubernetes集群部署DataWorks。Kubernetes是一种开源的容器编排系统,可以自动管理容器的生命周期、负载均衡、故障恢复等功能。
Hadoop集群部署:
在DataWorks中,您可以使用Hadoop集群部署DataWorks。Hadoop是一种开源的大数据处理框架,可以提供高可靠性和高可扩展性。
以上是一些常见的本地化部署方式,您可以根据自己的需求选择适合自己的方式。如果您还有其他问题,欢迎随时联系我们。
DataWorks 支持与本地化部署的系统集成和交互,,DataWorks能够与本地应用或服务通过多种方式集成,实现数据开发、任务调度、运维监控等功能的扩展与定制,间接体现了与本地化系统的协同能力.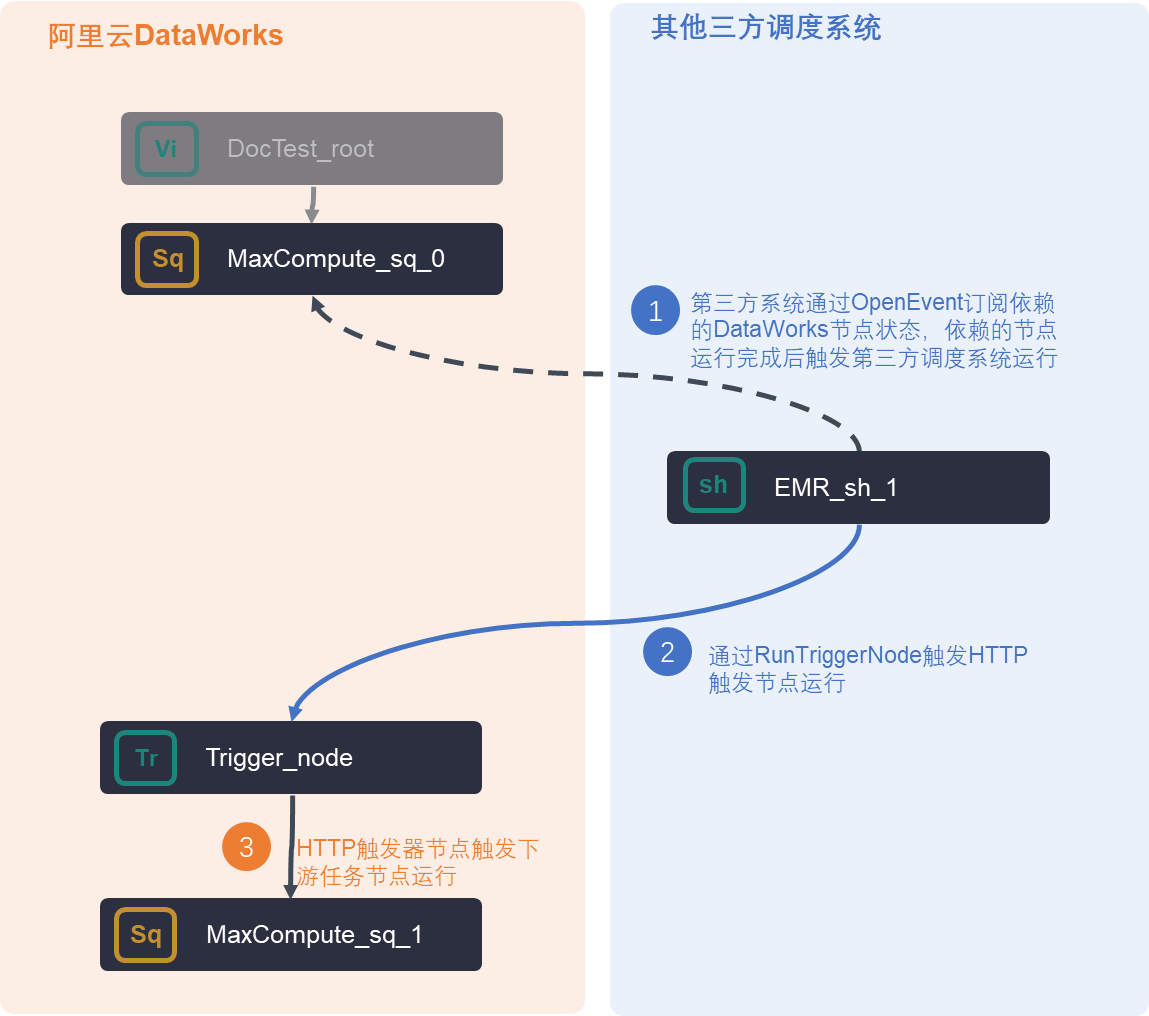
开发部署扩展程序:
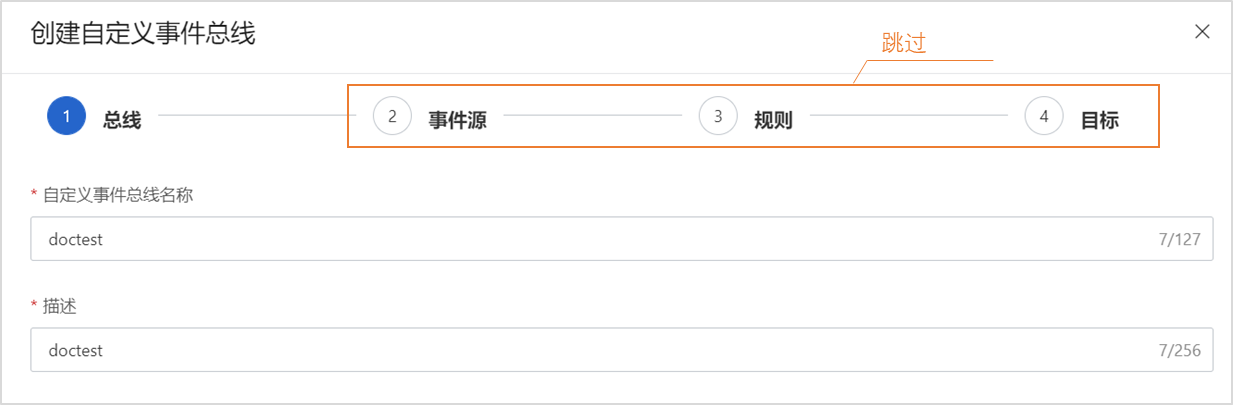
自建服务方式:提供了另一种集成方式,用户可以自建服务来处理DataWorks的扩展点事件。通过OpenEvent订阅事件、注册扩展程序,并通过OpenAPI回调处理结果给DataWorks,这一过程支持用户在本地搭建服务与DataWorks交互,实现流程控制的自定义。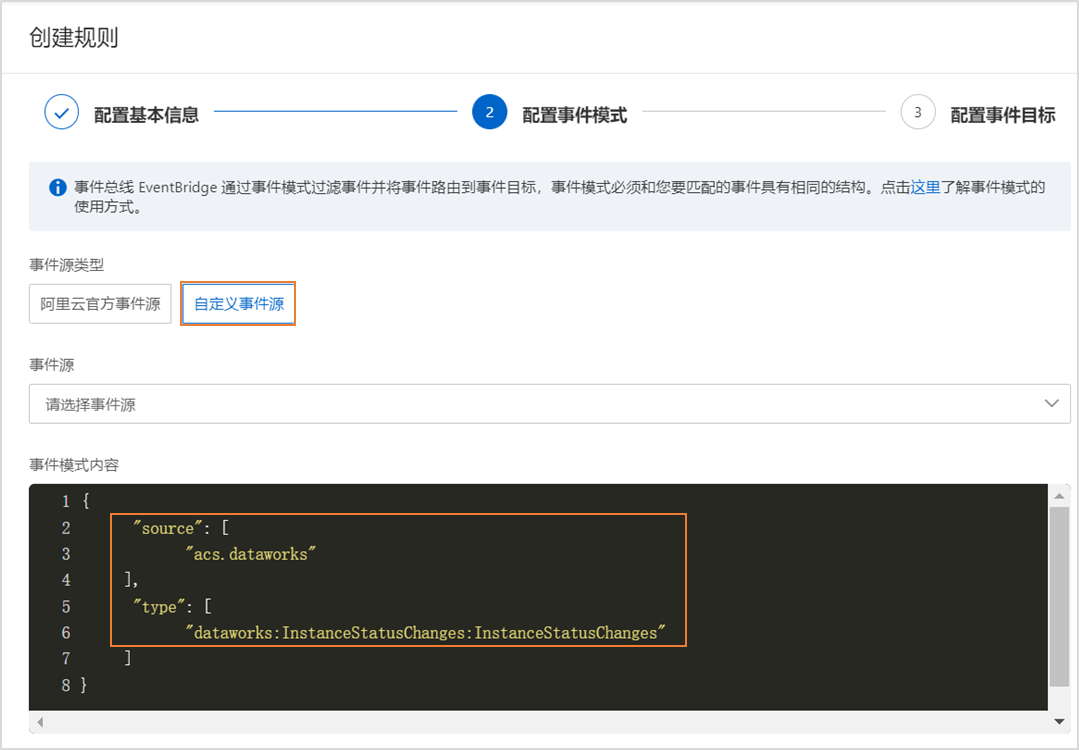
最佳实践案例:展示了如何在本地环境进行开发和测试,比如使用Java、Node.js等技术栈开发应用,与DataWorks的OpenAPI进行交互,实现数据开发任务的提交、运行监控,以及自定义运维大屏和第三方调度系统的集成。这些案例虽未直接描述DataWorks本身的本地部署,但强调了与本地应用的紧密集成能力。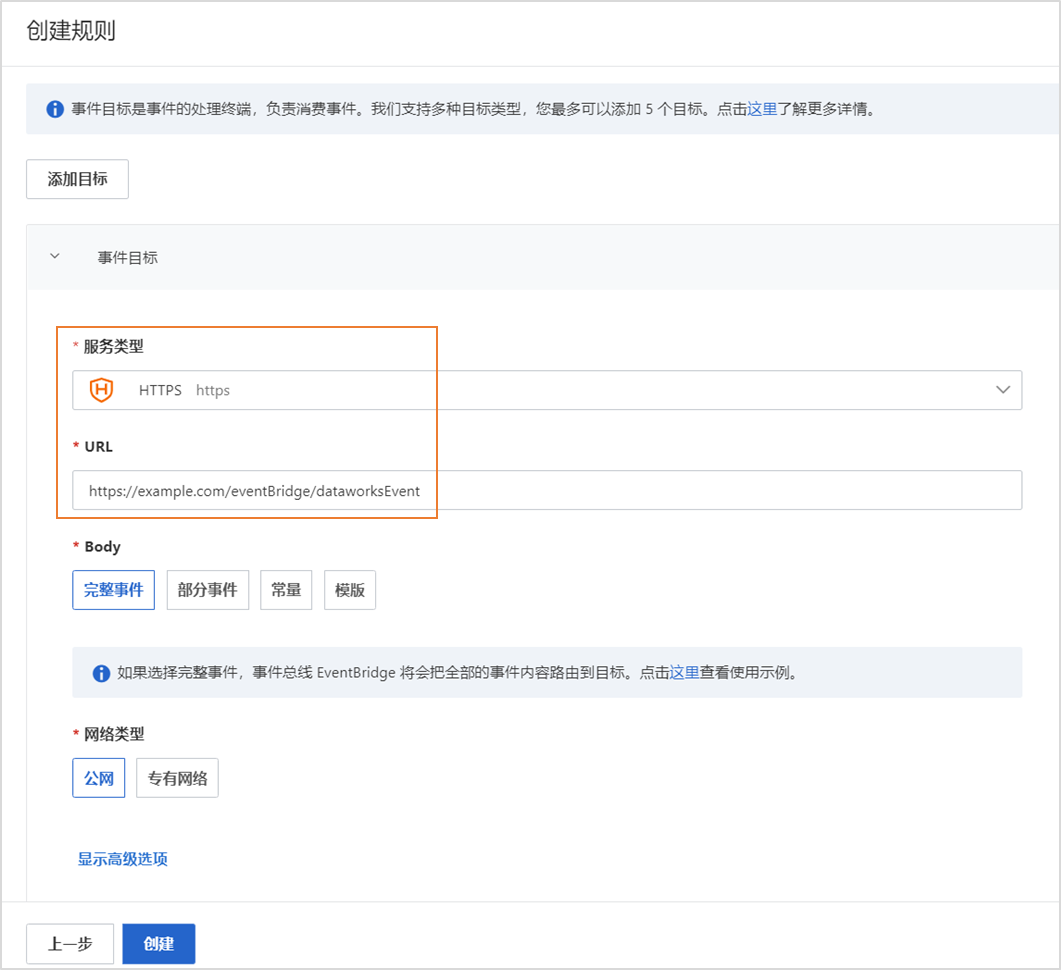
综上所述,DataWorks更多地作为一个云端数据开发与运维平台,鼓励用户通过API、函数计算、自建服务等方式与本地系统集成,实现灵活的功能扩展和定制,而不是直接进行平台的本地部署。用户可以根据具体需求,利用上述机制与本地应用或服务无缝对接。
相关链接
最佳实践:集成第三方调度系统 三方系统配置:开发触发HTTP触发节点运行的逻辑 https://help.aliyun.com/zh/dataworks/user-guide/best-practices-for-integrating-a-third-party-scheduling-system-with-the-dataworks-scheduling-system
DataWorks目前不提供本地化部署的选项,它是一款专为云端环境设计的产品,旨在帮助用户在阿里云上进行大数据工作流的开发、管理和运维。
如果您需要本地部署大数据处理的解决方案,阿里云提供了开源的大数据组件,例如MaxCompute(开源名为Open Data Processing Service, ODPS)、Apache Flink等,这些可以结合自建的Hadoop集群或其他大数据平台进行本地部署和使用。
DataWorks本地化部署:
DataWorks支持本地化部署,即在用户的私有环境中搭建DataWorks平台。本地化部署通常涉及服务器部署、网络架构设置、数据库配置以及高可用性和容灾性能的考虑。
相关资料:
部署步骤:
进入DataWorks控制台创建工作空间。
选择MaxCompute引擎。
创建完成后进入数据开发。
新建表填入路径和表名称。
提交开发以及生产环境。
导入本地的数据。
新建odpssql节点运行查询sql。
操作指南:
阿里云提供了详细的官方文档,包含功能介绍、操作指南等内容。
DataWorks各版本详解,介绍了不同版本的具体功能和支持情况。
最佳实践:
官方支持的最佳实践指南,如高效数据治理实施指南。
实践案例,如基于DataWorks平台实现网站用户画像分析。
培训课程:
阿里云提供的在线培训课程,从入门到进阶内容。
社区论坛:
阿里云社区提供用户经验分享和问题交流平台。
技术支持:
遇到具体问题或需求时,可直接联系阿里云官方技术支持团队获取帮助。
DataWorks支持本地化部署,即用户可以根据自己的需求将DataWorks部署在自己的私有环境中,包括数据中心或私有云环境中,以满足组织对数据安全和合规性的要求。这种部署方式通常包括服务器部署、网络架构设置、数据库设置以及高可用和容灾性能的考虑。
具体来说,虽然DataWorks核心服务作为一个云端大数据开发运维平台,主要面向云上部署和管理,但它提供了与本地开发流程相结合的能力,尤其是在扩展程序开发与部署的场景里。用户可以在本地完成开发工作,比如编写处理特定事件的代码,利用相关库来运行请求处理程序,并将成果部署到云端以与DataWorks平台集成。此外,DataWorks还提供了一系列功能,包括数据集成、数据开发、数据运维和数据治理等,帮助企业构建大数据生态系统,提升数据开发效率和数据处理能力。
需要注意的是,本地化部署需要具备一定的技术能力,并且可能需要支付额外的部署和维护费用。因此,在选择本地化部署之前,建议用户先评估自己的技术能力和经济实力。
综上所述,DataWorks不仅支持云上部署,也支持本地化部署,以满足不同用户的多样化需求。关于DataWorks本地化部署的详细步骤和最佳实践,可以参考阿里云官方文档和相关技术社区的资源。
DataWorks产品主要面向云端部署,提供SaaS化的大数据开发、调度、运维和管理等能力,旨在帮助企业用户快速构建数据仓库、数据湖、ETL流程等大数据应用。根据现有资料,DataWorks并不直接支持本地化部署的模式。其设计和服务均围绕阿里云平台展开,强调与阿里云上的各类服务如MaxCompute、Function Compute等的深度集成与优化。
如果您有特定需求关于在本地环境或者私有云中部署类似DataWorks功能的解决方案,可能需要探索其他开源或商业的大数据平台,如Apache Airflow、Luigi等,它们提供了不同程度的可定制化和本地部署能力。而对于希望利用阿里云生态优势和一站式大数据开发管理体验的用户,推荐使用云端的DataWorks服务。
综上所述,DataWorks不支持本地化部署,而是作为阿里云上的一项服务提供给用户。
相关链接
开发部署扩展程序:函数计算方式 使用限制 https://help.aliyun.com/zh/dataworks/user-guide/develop-and-deploy-a-custom-extension
开发部署扩展程序:自建服务方式 使用限制 https://help.aliyun.com/zh/dataworks/user-guide/preparations
DataWorks各版本详解 DataWorks各版本支持的功能详情 https://help.aliyun.com/zh/dataworks/product-overview/differences-among-dataworks-editions
最佳实践:表管理OpenAPI基础实践 实践4:查找表对应的节点 https://help.aliyun.com/zh/dataworks/user-guide/call-api-operations-to-perform-operations-related-to-tables
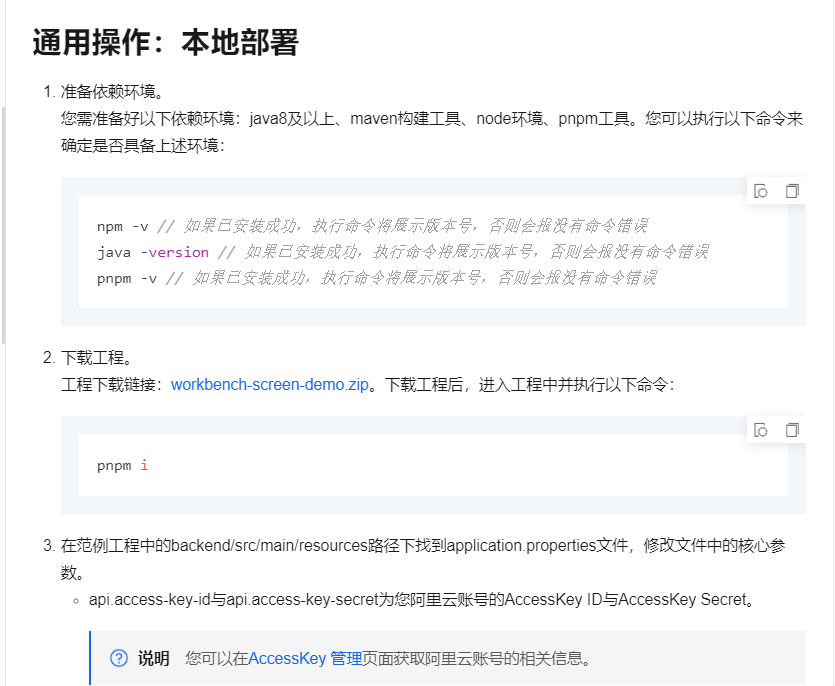
最佳实践:搭建自定义运维大屏 通用操作:本地部署 https://help.aliyun.com/zh/dataworks/user-guide/build-a-custom-o-and-m-dashboard
阿里云DataWorks是一个集数据集成、开发、治理于一体的数据中台产品,它主要用于构建企业级的数据仓库、数据湖以及数据分析平台。DataWorks本身是一个云端服务,主要在阿里云平台上运行,旨在提供高效、安全的数据处理能力。
目前,DataWorks并不支持本地化部署。它的设计初衷是为了充分利用云计算的优势,包括弹性扩展、高可用性、安全性等,以及方便与其他阿里云服务集成。这意味着DataWorks的所有功能和服务都需要在阿里云的基础设施上运行。
如果您希望了解有关DataWorks的更多信息,可以参考以下资源:
官方文档:阿里云提供了详细的官方文档,其中包含了DataWorks的功能介绍、操作指南、最佳实践等内容。您可以在阿里云DataWorks文档中心找到这些信息。
社区论坛:阿里云社区是一个非常好的交流平台,您可以在那里找到其他用户的使用经验分享,也可以提问获取帮助。阿里云社区上有专门的DataWorks板块。
技术博客:阿里云官网还提供了很多技术博客文章,涵盖了各种使用案例和技术解析。您可以在阿里云技术博客搜索相关文章。
培训课程:如果您想深入了解DataWorks的功能和使用方法,还可以参加阿里云提供的在线培训课程。这些课程通常涵盖从入门到进阶的内容,有助于加深理解和提高技能。
官方支持:如果您有更具体的需求或遇到问题,可以直接联系阿里云的官方技术支持团队。他们可以为您提供专业的咨询和支持服务。
如果您对DataWorks有本地化部署的需求,可能需要考虑使用其他工具或解决方案,例如Apache Hadoop、Apache Spark等开源大数据框架,或者探索阿里云提供的私有云解决方案,如混合云部署方案。这些方案可以满足本地部署的需求,但同时也需要自行维护和管理相应的基础设施。
理论上是支持的, 你可以看这个文档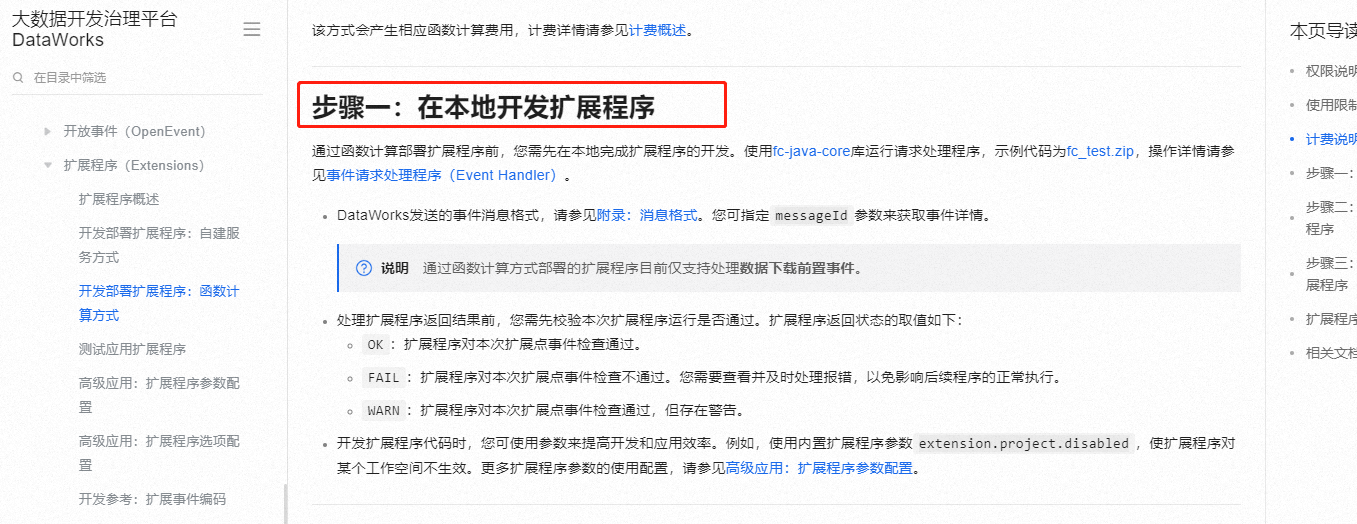
DataWorks 支持与本地环境的集成与交互,尤其是在开发部署扩展程序的场景中。虽然DataWorks本身作为一个云端大数据开发运维平台,主要面向的是云上部署和管理,但它提供了与本地开发流程相结合的能力,尤其是通过函数计算方式部署扩展程序时,允许在本地完成扩展程序的开发
。以下是关键步骤和注意事项:
本地开发扩展程序:
在本地环境中,首先完成扩展程序的开发工作。这包括编写处理特定事件(如数据下载前置事件)的代码,利用如fc-java-core库来运行请求处理程序
开发过程中需参考DataWorks发送的事件消息格式,以便正确解析和处理这些消息
代码中可以利用扩展程序参数来优化开发效率,比如使用extension.project.disabled参数控制扩展程序在特定工作空间的生效情况
函数计算部署:
完成本地开发后,需要将扩展程序部署至阿里云的函数计算服务上。这意味着尽管开发活动在本地进行,实际运行环境位于云端
配置函数计算服务时,涉及创建服务、函数,上传本地开发的代码包(如fc_test.zip),并根据代码需求选择合适的运行环境
此外,还有实践案例展示了如何在本地部署并运行代码以订阅实例状态变更消息,虽非直接关于DataWorks本地化部署,但体现了DataWorks与本地开发环境的联动能力,通过构建应用并监听EventBridge消息来响应DataWorks中的事件
综上所述,虽然DataWorks核心服务倾向于云上部署,它确实支持与本地开发环境的协同工作模式,特别是在扩展程序开发与部署的场景里。用户可以在本地完成开发工作,然后将成果部署到云端以与DataWorks平台集成。支持的
本地部署运行
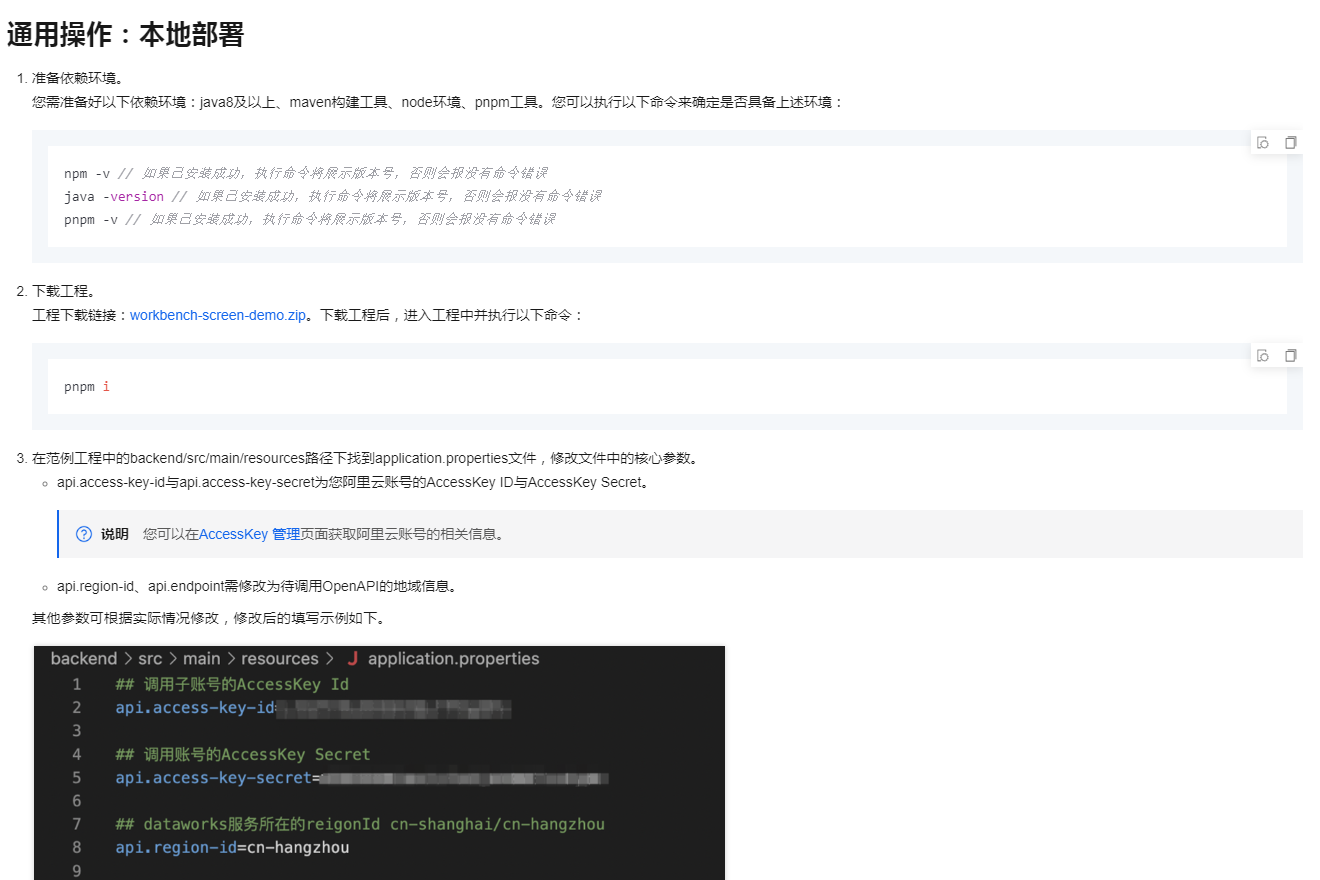
下载工程:
依赖环境:java8及以上,maven构建工具。
工程下载链接:schedule-integration-demo.zip。
下载工程后,进入工程根目录下执行:
mvn clean package -Dmaven.test.skip=true spring-boot:repackage
获得可直接运行的jar后执行:
java -jar target/schedule-integration-demo-1.0.jar
完成后,在浏览器输入http://localhost:8080/index会得到"hello world!",表示应用成功部署。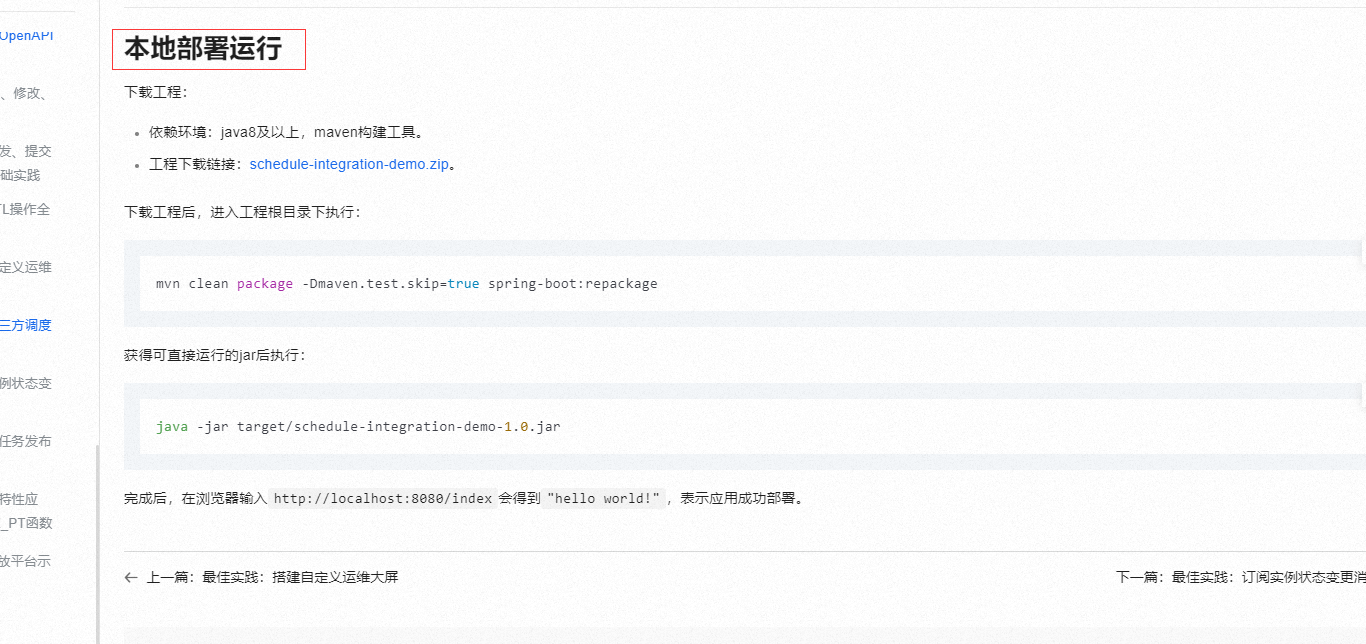
参考文档 https://help.aliyun.com/zh/dataworks/user-guide/best-practices-for-integrating-a-third-party-scheduling-system-with-the-dataworks-scheduling-system?spm=a2c6h.13066369.question.6.cc801458o2C8jI#section-ppu-zjx-hh0
支持的。
本地部署运行
下载工程:
依赖环境:java8及以上,maven构建工具。
工程下载链接:schedule-integration-demo.zip。
下载工程后,进入工程根目录下执行:
mvn clean package -Dmaven.test.skip=true spring-boot:repackage
获得可直接运行的jar后执行:
java -jar target/schedule-integration-demo-1.0.jar
完成后,在浏览器输入http://localhost:8080/index会得到"hello world!",表示应用成功部署。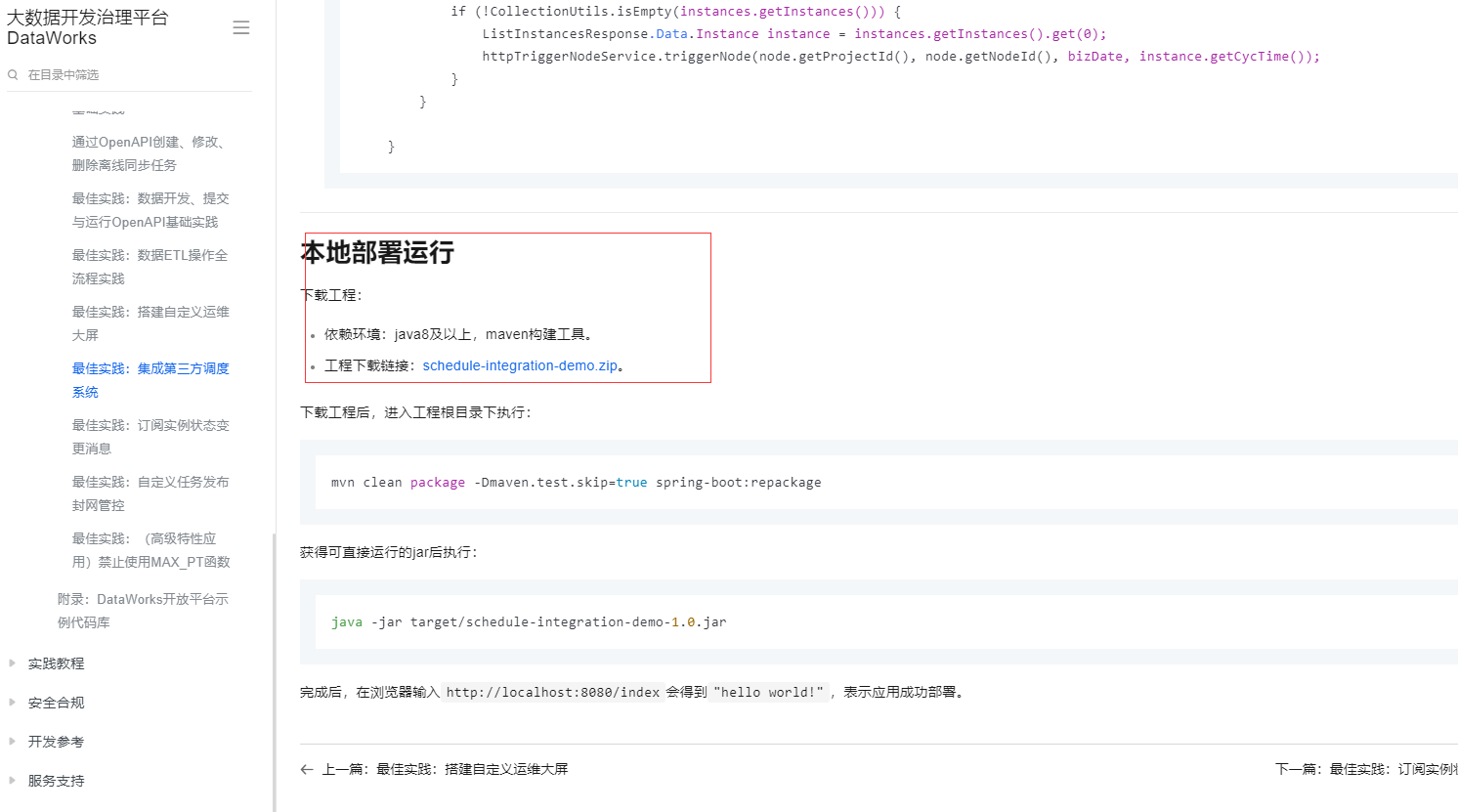
参考文档https://help.aliyun.com/zh/dataworks/user-guide/best-practices-for-integrating-a-third-party-scheduling-system-with-the-dataworks-scheduling-system?spm=a2c4g.11186623.0.i2
DataWorks提供了丰富的OpenAPI,您可以根据需要使用DataWorks的OpenAPI等开放能力实现各种业务场景。
npm -v // 如果已安装成功,执行命令将展示版本号,否则会报没有命令错误
java -version // 如果已安装成功,执行命令将展示版本号,否则会报没有命令错误
pnpm -v // 如果已安装成功,执行命令将展示版本号,否则会报没有命令错误
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。