云数据仓库ADB如何导出大批量数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
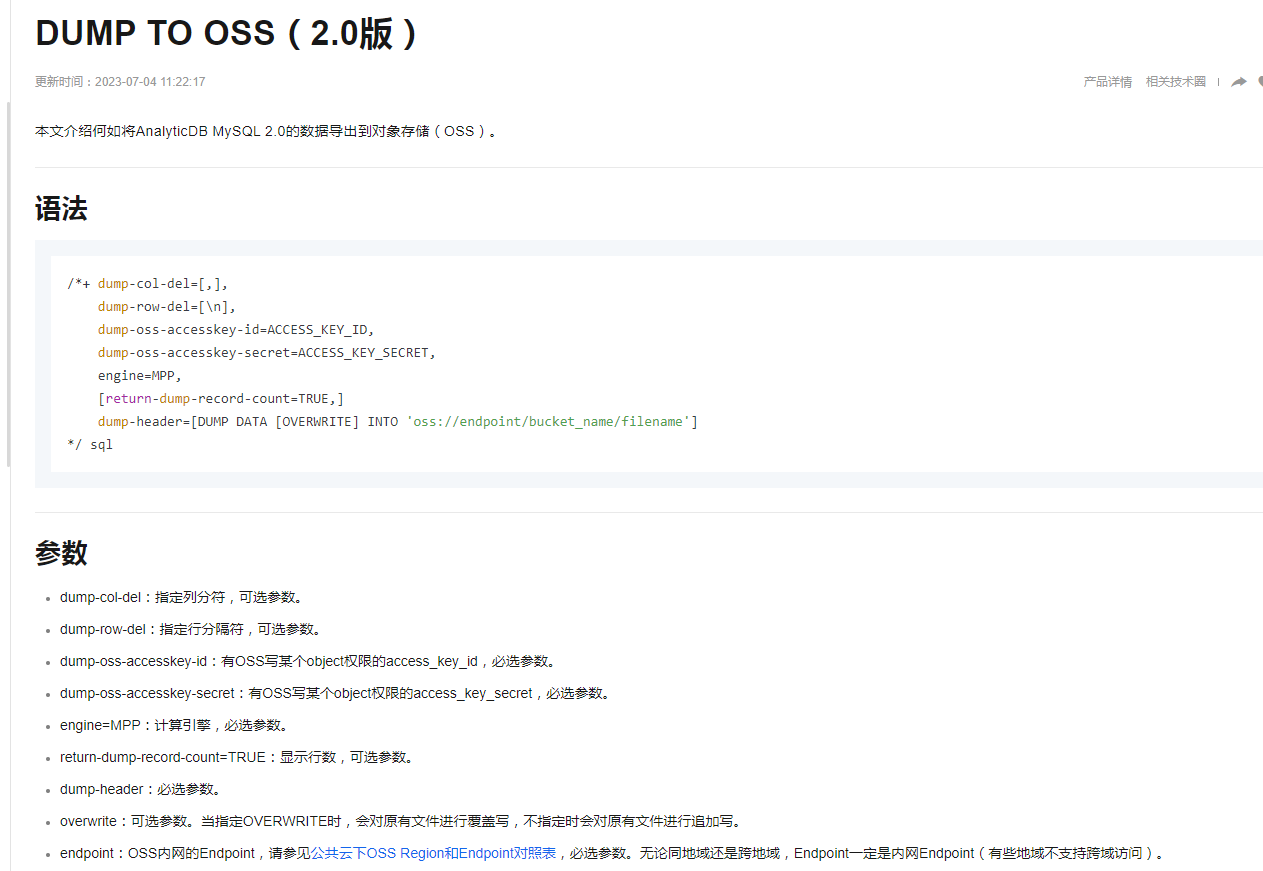
要导出AnalyticDB(ADB)MySQL数据库中的大批量数据,可以采用几种策略:
使用ADB MySQL版导入工具:此工具不仅支持导入,同样适用于导出大量数据到本地文件。首先,你可能需要将数据导出到一个临时表或文件中,然后再利用Linux的split命令对数据进行切分,以便于高效处理和传输。详细操作可参考这里。
LOAD DATA:虽然LOAD DATA通常用于导入,但你可以先使用SELECT INTO OUTFILE或类似命令将数据导出到文件,然后在其他系统中使用LOAD DATA加载这些文件。有关如何使用LOAD DATA导入数据的指南,可以为导出提供一定的参考思路,详情见此处。
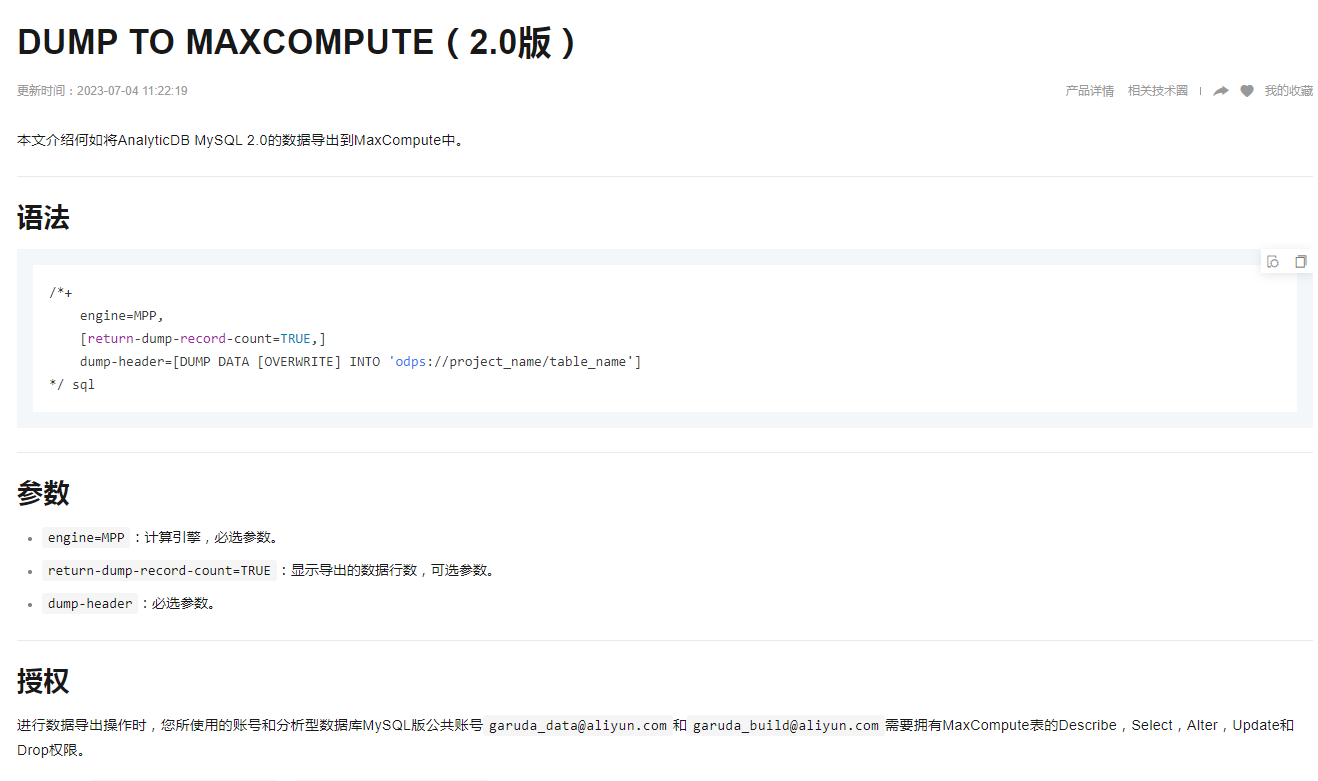
通过DataWorks导入/导出:DataWorks提供了一种灵活的方式来在不同的阿里云服务间移动数据,包括从ADB MySQL版导出数据。对于ADB MySQL版的湖仓版或数仓版,可以参考这篇文章了解如何通过DataWorks将数据导入导出。
异步提交导入任务:虽然SUBMIT JOB语句主要用于数据导入操作,但其背后的原理和技术也可以启示我们如何设计高效的导出流程,尤其是处理大量数据时的并行和异步处理策略。具体语法和使用方法请参考官方文档。
综上所述,虽然直接的大批量数据导出功能可能没有直接提及,但结合ADB MySQL的数据导入工具、SQL命令以及DataWorks等服务,你可以构建出适合大规模数据导出的解决方案。实际操作时,请根据具体需求和数据量选择最合适的方法。此回答整理自钉群“云数据仓库ADB-开发者群”
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。