DataWorks中语义分析异常-无法解析?odps-0130071:[16,31] Semantic analysis exception - column od.trade_unique_id cannot be resolved
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中遇到语义分析异常 "odps-0130071: [16,31] Semantic analysis exception - column od.trade_unique_id cannot be resolved" 通常意味着系统无法识别或解析您在SQL语句中引用的列名 od.trade_unique_id。以下是一些可能的原因和解决方案:
od),确保别名正确对应到相应的表。trade_unique_id在表od中确实存在。od作为别名的表确实包含了trade_unique_id列。SELECT od.trade_unique_id FROM some_table AS od;,确保some_table确实有trade_unique_id列。od表和trade_unique_id列。以下是一个示例SQL语句,展示了如何正确使用别名和列名:
-- 假设表名为 trade_data,其中包含列 trade_unique_id
SELECT od.trade_unique_id
FROM trade_data AS od
WHERE od.trade_unique_id IS NOT NULL;
确保在实际使用中,trade_data 表确实存在,并且有 trade_unique_id 这一列。
通过以上步骤,应该能够解决“Semantic analysis exception - column od.trade_unique_id cannot be resolved”的问题。如果问题仍然存在,可能需要更深入地检查系统的配置和权限设置。
这个错误提示表示DataWorks无法解析您的查询语句,具体原因可能是您的查询语句中包含无法解析的列名。以下是一个示例查询语句:
select * from mytable where trade_unique_id > 1000;
在上述查询语句中,“trade_unique_id”是一个列名,如果DataWorks无法解析该列名,就会抛出错误提示。
要解决这个问题,您可以尝试以下方法:
检查列名是否正确:
在DataWorks中,列名是区分大小写的,因此您需要确保查询语句中的列名与数据源中的列名完全匹配。例如,如果您的数据源中包含一个名为“trade_unique_id”的列,那么在查询语句中就需要使用相同的列名。
检查数据源是否正确:
在DataWorks中,查询语句需要指定数据源,如果数据源不正确,就会抛出错误提示。因此,您需要确保查询语句中指定的数据源是正确的。
检查查询语句是否正确:
在DataWorks中,查询语句需要符合一定的语法规则,如果查询语句不正确,就会抛出错误提示。因此,您需要检查查询语句是否正确,并确保查询语句中的关键字、括号、引号等符号使用正确。
系统无法识别或找到指定的列od.trade_unique_id。此问题通常与数据表结构变动或引用错误
确认数据表od中是否存在trade_unique_id这一列。如果表结构近期有调整,可能导致该列被移除或重命名。
刷新数据集:在仪表板编辑界面,尝试刷新数据集列表,确保其反映了最新的表结构变化。
重新配置字段:若刷新无效,可尝试先切换到其他有效数据集,然后再切回原数据集,并重新勾选需要的字段,确保所选字段与当前数据表结构匹配。
ODPS-0130071错误表示语义分析异常,通常是由于引用了不存在的列。在您的情况中,列od.trade_unique_id无法被解析,可能是因为表od中没有这个列,或者拼写、大小写有误。请检查SQL语句中的表结构和列名是否正确无误,确保列
名存在于对应的表中,并保持大小写一致
在阿里云DataWorks中使用数据开发任务时,可能会遇到语义分析异常的问题。这种异常通常表明系统无法解析执行计划中的某个部分,导致任务无法正常执行。具体来说,这种错误可能由多种原因引起,例如SQL语句错误、数据源配置错误、列名不匹配等。为了更全面地理解和解决这类问题,下面将从多个角度进行分析:
检查数据源和列配置
数据源列数不符:一种常见的错误是数据源中列的数量与DataWorks任务中预期的列数不符。例如,如果DataWorks任务期望数据源有5列,但实际数据源只有1列,则会出现此类错误。确保数据源的列数符合DataWorks任务的要求,并且列名与DataWorks中的字段定义一致。
分区表全扫描:在使用分区表时,如果没有指定分区或不允许全表扫描(set odps.sql.allow.fullscan=true;),也可能导致语义分析异常。在查询分区表时,应指定具体的分区条件,避免全表扫描。
验证SQL语句和数据类型
SQL语句错误:SQL语句中的错误是导致语义分析异常的一个常见原因。这包括语法错误、错误的表名或列名、错误的数据类型等。仔细检查SQL语句,确保所有的引用和命令都是正确的。
数据类型不匹配:如果SQL语句中引用的列数据类型与实际数据源中的数据类型不匹配,也会导致语义分析异常。特别是在进行JOIN操作或数据转换时,数据类型的一致性非常重要。
配置和权限检查
数据源权限:不足的权限也可能导致语义分析异常。如果当前账户没有访问特定表或列的权限,查询将失败并出现语义错误。确保有足够的权限来访问所有涉及的数据源和表。
刷新元数据:如果表结构或列名最近被修改过,但在DataWorks中未刷新元数据,也可能导致语义分析异常。重新同步数据源,确保元数据反映最新的表结构。
环境和依赖检查
环境差异:开发环境和生产环境之间的差异也可能导致语义分析异常。在开发环境中测试成功的任务,在生产环境中可能因为配置或数据不同而失败。确保两个环境的配置尽可能一致,并在生产环境部署前进行充分测试。
依赖项缺失:任务运行依赖的其他任务或资源失败或不可用,也会导致语义分析异常。检查任务依赖项是否正确配置,并确保所有依赖项在运行时都是可用的。
高级设置和优化
使用完全限定名:为了避免列名或表名解析错误,使用完全限定名(即包括数据库和模式名)来引用表和列。这可以减少因模糊引用导致的语义分析异常。
优化SQL性能:某些语义分析异常可能与查询的性能有关。优化SQL语句,减少不必要的计算量和数据扫描,可以提高查询效率并减少错误发生的机会。
除了上述主要方案之外,还需要注意以下几个关键点:
定期审核权限和资源配置:随着项目复杂度的增加,定期审核并调整权限设置和资源配置是必要的。这不仅能保证项目成员能够访问所需资源,还能提高项目整体的安全性。
深入了解DataWorks特性:熟悉并深入了解DataWorks提供的各项特性和功能,如实例生成策略、调度依赖配置等,有助于更高效地管理和使用DataWorks。
保持工作空间版本的更新:确保使用的DataWorks工作空间版本是最新的。旧版工作空间可能不支持某些新功能或改进,及时更新可避免此类问题。
综上所述,解决DataWorks中的语义分析异常需要从多个方面入手,包括检查数据源和列配置、验证SQL语句和数据类型、配置和权限检查、环境和依赖检查以及高级设置和优化等。通过这些措施,可以有效地解决大部分语义分析异常问题。同时,持续学习和适应DataWorks的更新和特性变化,也是确保顺利使用的关键。
当在DataWorks中遇到“语义分析异常 - 无法解析”的错误时,通常意味着SQL查询中的某个表或列不存在、拼写错误或是表结构发生了变化。以下是解决这个问题的具体方法:
检查列名和表名:
确保你使用的列名 trade_unique_id 在表 od 中确实存在并且拼写正确。
如果 od 是一个表的别名,确保别名的使用是正确的。例如,如果 od 是 orders_daily 表的别名,需要确认是否正确地定义了别名并在SQL中引用了它:SELECT od.trade_unique_id FROM orders_daily od;。
检查表结构:
使用命令查看表 od 的结构:DESC od;,确认 trade_unique_id 列是否存在。
检查SQL语句:
仔细检查你的SQL语句,确保所有表名和列名都是正确的。
数据源问题:
确认你正在查询的表存在于正确的数据源中,并且你有访问该数据源的权限。
如果你最近修改了表结构或新增了列,确保在DataWorks中刷新元数据。可以通过重新同步数据源的方式更新元数据。
权限问题:
确认你有足够的权限去读取表 od 和列 trade_unique_id。
表别名问题:
如果你在SQL中使用了表别名,确保别名是正确的并且没有冲突。
调试SQL:
在DataWorks或其他工具中单独运行SQL语句,看是否能够正常执行。
查看日志:
在DataWorks中查看具体的执行日志,可能会提供更多关于错误的信息。
此外,在处理DataWorks中的语义分析异常时,还应注意以下几点:
避免全表扫描:对于分区表,要指明分区或者不允许全表扫描,可以通过设置 set odps.sql.allow.fullscan=true; 来允许全表扫描。
指定分区谓词:在查询分区表时,必须始终指定分区谓词,以便仅检索所需的分区。例如,如果有一个按日期分区的表,只想查询最近一个月的数据,则可以指定分区谓词:SELECT * FROM bank_data_pt WHERE date >= DATEADD(month, -1, current_date)。
函数定义和参数传递:如果使用了自定义函数(UDF/UDAF/UDTF),需要确保函数定义正确无误,参数传递方式和格式正确,输入参数和输出结果类型与使用场景匹配,以及依赖项配置正确。
总的来说,解决DataWorks中语义分析异常的关键在于细致地检查SQL语句中的表名、列名、数据源、权限以及别名等元素,并确保它们的正确性。同时,注意避免全表扫描,指定分区谓词以提高查询效率。如果使用了自定义函数,还需要检查函数的定义和参数传递是否正确。在排查过程中,查看执行日志和联系技术支持也是解决问题的有效途径。
在DataWorks中遇到“语义分析异常 - 无法解析”的错误(odps-0130071:[16,31] Semantic analysis exception - column od.trade_unique_id cannot be resolved),通常意味着SQL查询中引用的列名无法在上下文中找到对应的列。
以下是一个示例,展示了如何使用完全限定名来避免别名相关的错误:
SELECT your_table_name.trade_unique_id
FROM your_database.your_table_name AS od
WHERE some_condition;
ODPS-0130071错误表示语义分析异常,通常是由于引用了不存在的列。在您提到的场景中,column od.trade_unique_id cannot be resolved说明od.trade_unique_id这个列在当前上下文中没有被正确识别。请检查您的SQL语句,确保od表中确实存在trade_unique_id这一列,或者确认表名和列名的拼写无误,包括大小写。可参考文档ODPS-0130071
在DataWorks中遇到Semantic analysis exception - column od.trade_unique_id cannot be resolved(语义分析异常 - 无法解析列 od.trade_unique_id)这个问题,通常意味着SQL查询中的某个表或列不存在、拼写错误或是表结构发生了变化等原因导致的。下面是一些排查和解决此问题的方法: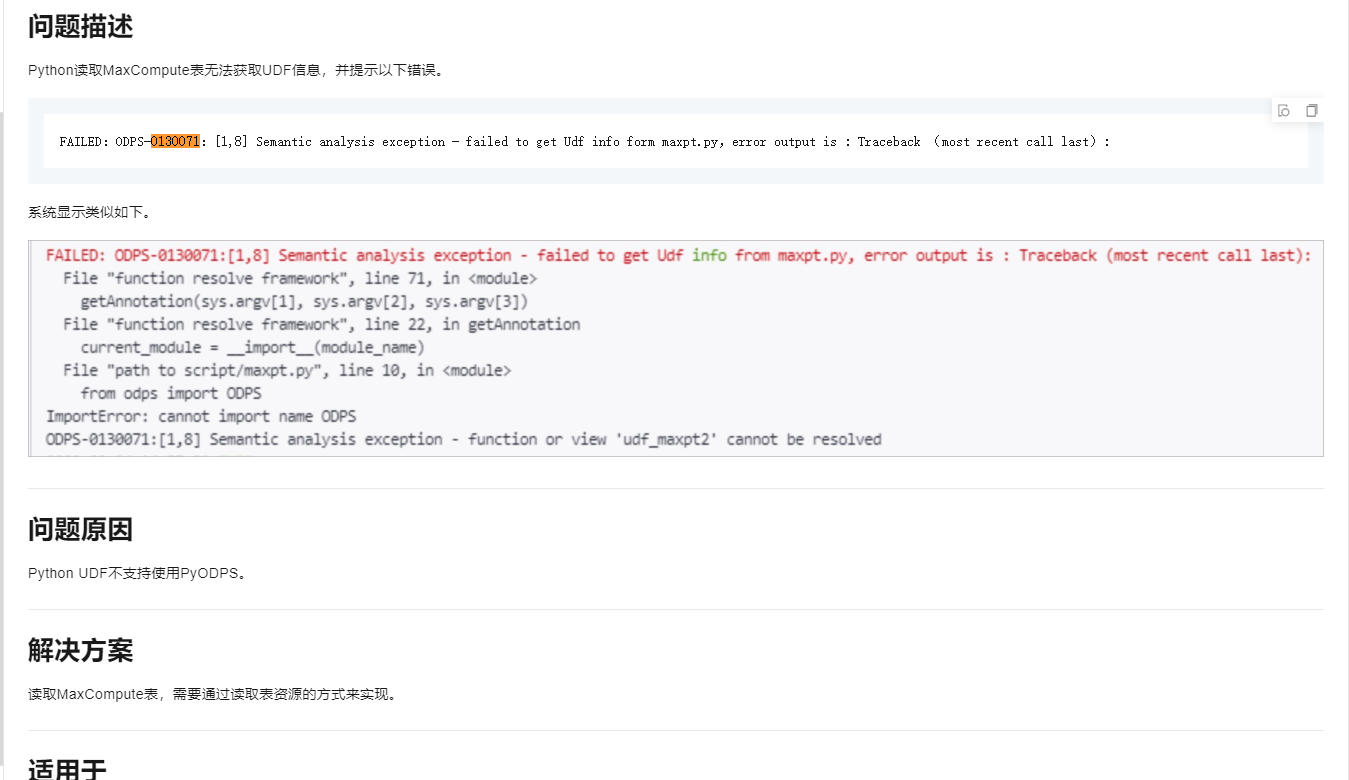
trade_unique_id 在表 od 中确实存在并且拼写正确。od 是正确的。如果 od 是一个表的别名,确保别名的使用是正确的。od 的结构:DESC od;
od 中的所有列名及其类型。确认 trade_unique_id 列是否存在。od 和列 trade_unique_id。od 是 orders_daily 表的别名,确保你正确地定义了别名并在SQL中引用了它:SELECT od.trade_unique_id FROM orders_daily od;
如果上述步骤都无法解决问题,建议进一步检查SQL语句的具体内容以及相关的表结构,并考虑咨询DataWorks的技术支持获取帮助。同时,你也可以在官方社区论坛中寻找类似问题的解决方案或提问寻求帮助。
通常是因为SQL查询中引用了不存在的列或字段
核对列名:检查SQL语句中引用的列名是否正确,包括大小写和是否有拼写错误。
检查表结构:确认表中确实存在该列,如果表结构有变更,需要更新SQL语句以匹配新的结构。
你检查一下列名吧
Python读取MaxCompute表无法获取UDF信息,并提示以下错误。
FAILED:ODPS-0130071:[1,8] Semantic analysis exception - failed to get Udf info form maxpt.py,error output is : Traceback (most recent call last):
系统显示类似如下。
0326_5.png
问题原因
Python UDF不支持使用PyODPS。
解决方案
读取MaxCompute表,需要通过读取表资源的方式来实现。
参考文档https://help.aliyun.com/zh/dataworks/resolve-the-issue-that-a-pyodps-node-fails-to-obtain-udf-information-when-it-reads-a-maxcompute-table?spm=a2c4g.11186623.0.i34
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。