
flink-cdc的数据校验和订正怎么做?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC Connectors 进行数据同步时,数据校验和订正是一个重要的环节,以确保数据的准确性和一致性。以下是一些常见的数据校验和订正的方法:
数据一致性检查:
确保 Flink CDC Connector 配置的源表和目标表具有相同的数据结构。
检查数据类型和格式是否匹配,包括主键和外键约束。
数据完整性校验:
使用 Flink SQL 或 DataStream API 进行数据转换时,确保所有必要的字段都被正确处理。
检查是否有数据丢失或格式错误的情况发生。
使用 Flink 的端到端(E2E)精确一次处理:
Flink 支持端到端的精确一次处理,确保即使在发生故障的情况下,数据也不会丢失或重复。
使用 Flink 的 Checkpoint 和 Savepoint:
利用 Flink 的 Checkpoint 机制来保存应用程序的状态,以便在发生故障时可以从最近的 Checkpoint 恢复。
使用 Savepoint 进行版本控制和升级。
数据对比:
定期在源表和目标表之间进行数据对比,检查是否有不一致的情况。
使用 Flink 的 Metrics:
Flink 提供了丰富的 Metrics 系统来监控数据流的各种指标,包括记录数、处理时间等。
错误处理:
配置 Flink CDC Connector 的错误处理逻辑,比如重试机制、死信队列等。
使用 Flink 的 Watermark:
如果数据流中包含时间戳,使用 Watermark 来处理乱序数据和确保时间相关的准确性。
数据清洗:
在数据写入目标表之前,进行数据清洗,去除无效或错误的数据。
使用 Flink 的 Schema Registry:
如果使用 Avro 或 Protobuf 等格式,可以使用 Schema Registry 来管理数据的 Schema 版本。
日志记录:
记录数据同步过程中的关键步骤和任何异常情况,以便事后分析。
监控和警报:
设置监控和警报机制,当数据同步出现问题时能够及时通知相关人员。
使用 Flink CDC Connector 的特定校验功能:
某些 Flink CDC Connector 可能提供了特定的数据校验功能,比如 MySQL Connector 的 validate_txn_boundary 配置项。
Flink CDC (Change Data Capture) 是一种用于捕获数据库变更事件并将其流式传输到 Apache Flink 的工具。在使用 Flink CDC 时,确保数据的准确性和一致性是非常重要的。数据校验和订正是确保从源系统到目标系统的数据传输过程中数据质量的关键步骤。
下面是一些常见的数据校验和订正的方法:
校验点(Checkpoints):
水印(Watermarks):
键控状态(Keyed State):
校验和(Checksums):
数据质量监控:
对比查询:
重试机制:
数据修复服务:
人工审核:
数据血缘追踪:
版本控制:
审计日志:
实现这些方法的具体步骤将取决于你的具体应用场景和技术栈。在实际应用中,你可能需要结合多种技术来确保数据的质量和一致性。
Flink CDC的数据校验和订正,通常是在数据迁移或同步过程中,通过比较源系统和目标系统的数据来确保一致性。以下是一般步骤:
数据双跑对比:新旧两个系统(源Flink CDC和目标实时计算Flink版作业)并行运行,处理相同的数据源。
全量或抽样对比:对于中小数据规模,可进行全量数据对比;大数据规模时,可随机抽样对比部分记录。
数据一致性检查:对比每个关键字段、窗口聚合结果,确保结果一致。
异常处理:发现数据不一致时,分析原因,如数据延迟、错误处理逻辑等,并进行相应调整。
业务验证:确保新系统的稳定性,观察处理延迟、Failover和Checkpoint情况。
业务切换:验证无误后,切换业务流量到新系统,停止旧系统。
数据校验
源端校验:在数据被Flink CDC读取之前,可以在数据库层面实施触发器或利用数据库的日志功能进行校验,确保变更数据的完整性与准确性。
数据流校验:在Flink作业中集成数据校验逻辑,比如使用Filter操作过滤掉不符合预期的数据,或者使用ProcessFunction进行复杂的校验逻辑处理。可以对比数据的主键、时间戳等字段来检查数据的一致性。
目标端校验:数据写入目标系统(如数据仓库、消息队列等)后,可以通过目标系统的校验机制或自定义脚本进行校验,确保写入数据的正确性
数据订正
补偿机制:如果发现数据错误,可以通过设计补偿逻辑重新拉取或修正错误数据。Flink的Savepoint机制可以帮助在出错时恢复到某个一致状态,然后从该点开始重新处理数据。
幂等写入:确保数据写入操作是幂等的,即多次执行同一操作对系统的影响是相同的。这样即使数据重复处理也不会导致数据不一致。
事务管理:利用Flink的两阶段提交(Two-Phase Commit, 2PC)或其他事务协议,确保数据写入操作的原子性和一致性。
import com.ververica.cdc.connectors.oracle.OracleSource;
import com.ververica.cdc.connectors.oracle.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class FlinkCdcDataValidation {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 定义 Oracle CDC 数据源
OracleSource<String> oracleSource = OracleSource.<String>builder()
.hostname("yourHostname")
.port(1521)
.database("yourDatabase")
.schemaName("yourSchema")
.tableList("yourSchema.yourTable")
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
// 创建数据流
SourceFunction<String> sourceFunction = oracleSource.getSourceFunction();
// 添加数据源到执行环境并打印数据
env.addSource(sourceFunction).print();
// 执行作业
env.execute("Flink CDC Data Validation");
}
}
在同步前后分别对源数据库和目标数据库进行快照,然后对比两个快照的差异。这是一种常用的数据校验方法,可以确保数据在迁移过程中的一致性。
使用 checksum 或 hash:为源数据库和目标数据库的数据计算 checksum 或 hash 值,比较这些值是否相同。这种方法可以快速发现数据不一致的问题
在迁移期间,让源系统和目标系统并行处理相同的数据。这种方法可以通过对比两个系统处理后的结果来发现数据不一致的问题
订正
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkCdcDataCorrection {
public static void main(String[] args) throws Exception {
// 创建执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建 Table 环境
final StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 定义 MySQL CDC 数据源
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(3306)
.username("yourUsername")
.password("yourPassword")
.databaseList("yourDatabase")
.tableList("yourDatabase.users") // 监听数据库中 users 表的变更
.deserializer(new JsonDebeziumDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
// 创建数据流
SourceFunction<RowData> sourceFunction = mySqlSource.getSourceFunction();
DataStream<RowData> cdcStream = env.addSource(sourceFunction);
// 将 CDC 流转换为 Table API 可以使用的表
tEnv.createTemporaryView("users_cdc", cdcStream, RowDataTypeInfo.of(new String[] {"id", "name", "age"}, new TypeInformation[]{Types.INT(), Types.STRING(), Types.INT()}));
// 校验并订正数据的 SQL 查询
// 假设我们需要根据某些条件来订正数据
String correctionSql = "SELECT * FROM (" +
" SELECT *, " +
" IF (your_condition, your_correct_value, CAST(your_field AS your_correct_type)) AS corrected_field " +
" FROM users_cdc " +
") WHERE your_condition";
// 执行订正操作
Table correctionTable = tEnv.sqlQuery(correctionSql);
// 将订正后的数据写回到目标数据库或目标表
tEnv.executeSql("CREATE TABLE corrected_users (" +
" id INT, " +
" name STRING, " +
" age INT" +
") WITH (" +
" 'connector' = 'jdbc'," +
" 'url' = 'your-jdbc-url'," +
" 'table-name' = 'users'" +
")");
tEnv.executeSql("INSERT INTO corrected_users " +
"SELECT * FROM (" +
" SELECT id, name, age FROM users_cdc " +
") WHERE your_condition");
// 执行作业
env.execute("Flink CDC Data Correction");
}
}
Flink-CDC在快照读取操作前、后执行 SHOW MASTER STATUS 查询binlog文件的当前偏移量,在快照读取完毕后,查询区间内的binlog数据并对读取的快照记录进行修正。
快照读取+Binlog数据读取时的数据组织结构。
BinlogEvents 修正 SnapshotEvents 规则。
修正后的数据组织结构:
——参考链接。
在Flink CDC中,数据校验和订正通常涉及到以下几个步骤:
对比源和目标的数据快照:在同步前后分别对源数据库和目标数据库进行快照,然后对比两个快照的差异。
使用 checksum 或 hash:为源数据库和目标数据库的数据计算 checksum 或 hash 值,比较这些值是否相同。
行级校验:逐行对比源数据库和目标数据库中的数据,确保每行数据都完全一致。
重新同步:如果问题不严重,可以重新同步数据,覆盖目标数据库中的不一致数据。
增量订正:只同步不一致的数据行,而不是整个表。
编写订正逻辑:在Flink作业中编写订正逻辑,例如使用Flink的SQL或DataStream API来更新目标数据库中的数据
Flink CDC的数据校验和订正,一般是在数据迁移过程中,通过对比源系统和目标系统的数据来确保数据一致性。以下是一个简单的步骤:
数据双写:在迁移期间,让源系统和目标系统(如阿里云实时计算Flink版)并行处理相同的数据。
数据对比:利用数据抽样或全量对比,检查源和目标系统处理后的结果。对于小规模数据,可以进行全量对比;大规模数据则可能需要抽样对比。
异常处理:如果发现数据不一致,分析原因,可能涉及数据延迟、处理错误等。根据错误情况,调整Flink作业配置或修正数据。
数据订正:如果发现错误,可以设计一个补偿逻辑,通过重新处理或插入/更新目标系统的数据来纠正错误。
监控与验证:确保新系统稳定运行一段时间,监控数据质量和处理延迟,确认达到预期的业务稳定性。
参考数据正确性验证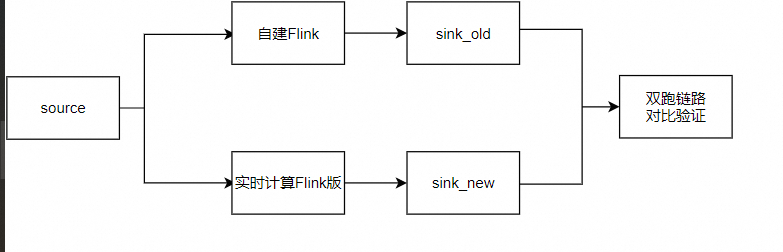
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。




{kind=link}