
在Flink CDC中如果基于SPECIFIC_OFFSETS消费数据,在gtid之后发生了表的ddl,将会报错,如何解决?Data row is smaller than a column index, internal schema representation is probably out of sync with real database schema
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC中基于SPECIFIC_OFFSETS并使用gtid后遇到表结构变更,可能会导致错误。解决这个问题的关键是确保作业从一个不会遇到结构不匹配的位点开始。您可以:
恢复到DDL发生前的位点:找到DDL发生前的最后一个安全位点,重新配置scan.startup.specific-offset.gtid-set来从那个位点开始。
重启并全量同步:如果无法找到安全位点,可能需要重启作业并进行全量同步,确保作业从一个已知与当前表结构匹配的点开始。
升级或配置无主键源表:如果支持,可以考虑使用Flink的无主键表支持,但请注意这只能保证At least once语义,可能需要结合下游幂等处理确保数据正确性。参考文档
先同步数据库表结构:
确保您的Flink作业使用的MySQL CDC connector能够自动适应或手动更新以反映数据库表结构的变化。如果您的作业版本低于Ververica Platform 6.0.2,考虑将其升级至6.0.2或更高版本
。新版本的MySQL CDC connector能更好地处理分库分表场景,并能自动使用最宽的Schema,减少因表结构变动导致的不一致问题
再同步数据库表结构:
确保您的Flink作业使用的MySQL CDC connector能够自动适应或手动更新以反映数据库表结构的变化。如果您的作业版本低于Ververica Platform 6.0.2,考虑将其升级至6.0.2或更高版本
。新版本的MySQL CDC connector能更好地处理分库分表场景,并能自动使用最宽的Schema,减少因表结构变动导致的不一致问题
确保 Flink CDC 与数据库 schema 同步:当数据库 schema 发生变化时,Flink CDC 需要能够识别这些变化并更新其内部 schema 表示。可以通过设置 Debezium 连接器的 debezium.schema.refresh.mode 参数为 latest-offset 或 continuous 来实现 schema 的自动更新 。
使用正确的 Debezium 版本:如果你使用的是 Debezium 1.5+ 版本,请注意其接口和配置选项可能已经发生了变化。确保使用与 Flink CDC 版本兼容的 Debezium 版本,并根据需要调整配置。
处理 Snapshot 和 Binlog 读取:如果使用 snapshot.mode = never,Debezium 可能不会读取 table schema,导致无法解析 log event。考虑使用其他 snapshot 模式,如 WHEN_NEEDED 或 INITIAL,以确保在需要时可以进行快照读取
schema与实际数据库schema不一致,从而引发数据行大小小于列索引的错误。这种情况通常是因为DDL操作修改了表结构,而Flink CDC连接器没有及时更新其内部schema。
为了解决这个问题,您可以尝试以下几种方法:
在Flink CDC使用过程中,若遇到因表的DDL变更导致的错误,如“Data row is smaller than a column index, internal schema representation is probably out of sync with real database schema”,这通常意味着Flink CDC的内部schema与实际数据库schema不同步。特别是在基于GTID偏移量(SPECIFIC_OFFSETS)消费数据时,如果在GTID之后有DDL操作,可能会引发该问题。解决此问题可遵循以下步骤:
识别问题原因:该错误表明Flink CDC在处理binlog事件时,发现数据行的结构与预期的schema不匹配,通常是由于数据库表结构发生变更(如新增、删除列)而Flink CDC的schema未及时更新所致[1]。
刷新或重建schema历史:为了使Flink CDC的connector与数据库的实际schema保持同步,需要采取措施刷新或重建schema历史。一种方法是执行一次新的快照,以确保所有表的最新schema被正确捕获和应用[1]。
检查并更新配置:确认Flink CDC任务的配置,确保启用了自动处理schema变更的功能。对于Debezium这样的connector,通常有配置项控制如何处理schema变更,比如database.history相关的设置,确保其配置为支持并记录schema变更的历史存储服务,如Kafka或文件系统[1]。
监控与手动干预:在生产环境中,应持续监控数据库的DDL变更,并在DDL操作后检查和验证Flink CDC任务的状态。如果自动处理机制未能成功同步schema,可能需要手动停止Flink作业,根据最新的数据库schema更新配置,然后重启作业。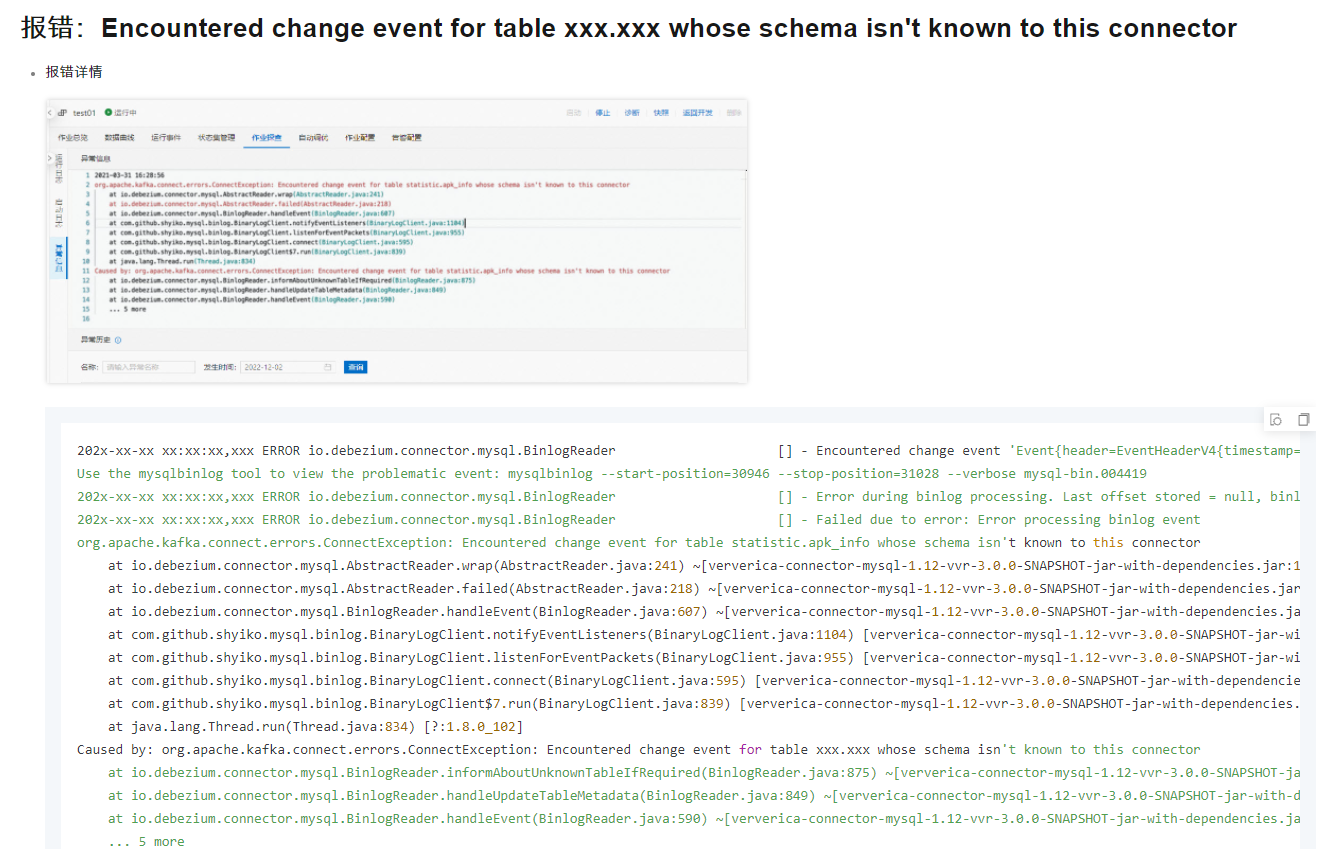
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


