
云数据仓库ADB如何优化?
【查询优化建议】
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
"MySQL控制台智能助手工具:
要优化ADB(AnalyticDB)MySQL数据库的查询性能,可以遵循以下建议:
添加索引列:确保在where子句中频繁使用的列上有索引,这能显著减少扫描行数,提升查询速度。
利用全列索引:ADB MySQL默认开启全列索引,它能自动覆盖查询中的所有列,无需额外创建单列索引。如果未自动开启,手动创建以优化查询。
检查数据类型匹配:确保查询条件的数据类型与表列类型相匹配,避免因类型不一致而导致的性能问题。
限制IN查询的元素数量:IN子句中的元素过多会影响性能,尽量减少元素数量或考虑其他查询策略,如JOIN或exists子句。
收集统计信息:ADB MySQL自动收集统计信息以辅助查询优化器,但新表可能需要手动收集一次。使用SELECT * FROM information_schema.column_statistics;检查统计信息状态,并按需手动收集。
调整Join Order:虽然ADB MySQL通常能自动选择最佳的Join顺序,但在特定情况下,手动调整Join顺序可能有益于性能。使用Hint /+ reorder_joins=true/false /来控制是否手动调整。
精简查询列:避免使用SELECT *,仅查询实际需要的列,因为返回列的数量直接影响性能。
合理使用索引和扫描策略:对于复杂的查询条件,识别哪些条件适合索引过滤,哪些适合扫描,并适当使用Hint控制执行策略,比如/+ no_index_columns=[] /。
避免索引失效的场景:注意函数转换、类型转换、后缀like查询等可能导致索引失效的操作,调整查询语句以维持索引的有效性。
去除冗余的is not null条件:确认列上已有合适的过滤条件时,移除不必要的is not null检查。
,此回答整理自钉群“云数据仓库ADB-开发者群”
这些策略结合使用,能有效提升ADB MySQL数据库的查询性能。"
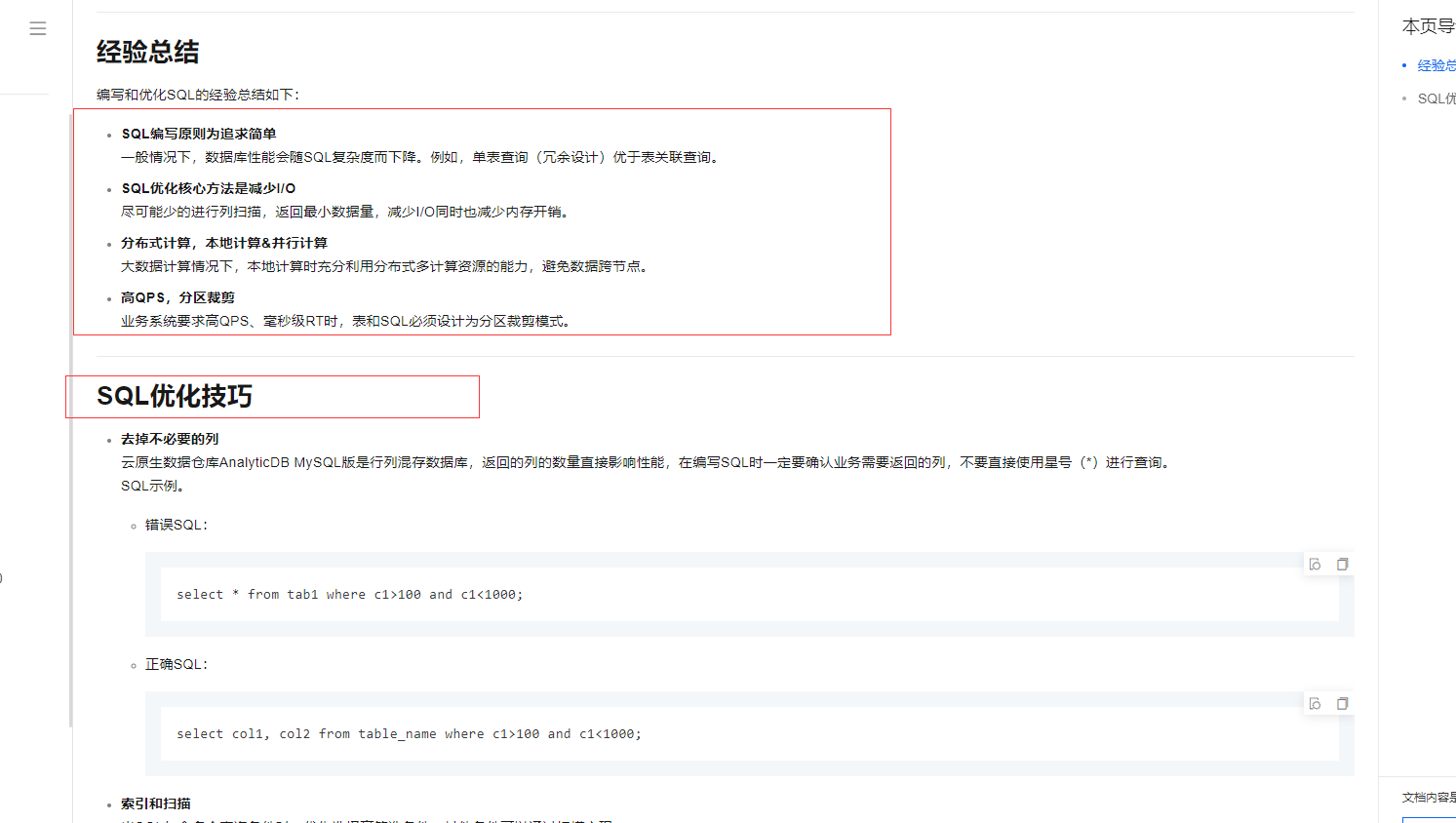
编写和优化SQL的经验总结如下:
SQL编写原则为追求简单
一般情况下,数据库性能会随SQL复杂度而下降。例如,单表查询(冗余设计)优于表关联查询。
SQL优化核心方法是减少I/O
尽可能少的进行列扫描,返回最小数据量,减少I/O同时也减少内存开销。
分布式计算,本地计算&并行计算
大数据计算情况下,本地计算时充分利用分布式多计算资源的能力,避免数据跨节点。
高QPS,分区裁剪
业务系统要求高QPS、毫秒级RT时,表和SQL必须设计为分区裁剪模式。
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。


