DataWorks中odps的库表设置了主键, 然后离线同步, 会出现数据重复的情况?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在数据同步到ODPS后,如果仍然发现存在重复数据,可以在ODPS中进行数据去重处理。这可以通过编写SQL语句或使用ODPS提供的数据去重功能来实现。例如,可以使用DISTINCT关键字来去除查询结果中的重复行,或者使用GROUP BY和聚合函数来合并重复数据。
在DataWorks中,如果ODPS(Open Data Processing Service,开放数据处理服务)的库表设置了主键,但在进行离线同步时出现数据重复的情况,可以通过以下几种方法来解决:
检查数据源
首先,需要确认数据源本身是否包含重复数据。如果数据源就存在重复数据,那么无论同步过程如何设置,都无法避免在ODPS表中出现重复。因此,检查并清理数据源中的重复数据是第一步。
使用唯一标识字段
在数据集成过程中,可以使用一个唯一标识字段(如用户ID、订单ID等)来避免数据重复。在增量同步时,只同步具有新唯一标识的记录,而不是所有记录。这样可以确保即使数据源中有更新,也不会因为更新操作而重复同步相同的数据。
增量同步策略
如果采用增量同步方式,需要确保增量同步的条件设置正确。例如,可以使用时间戳或版本号作为增量同步的条件。每次同步时,只同步最新的数据或版本号大于上次同步的记录,从而避免重复数据的出现。
数据去重处理
在数据同步到ODPS后,如果仍然发现存在重复数据,可以在ODPS中进行数据去重处理。这可以通过编写SQL语句或使用ODPS提供的数据去重功能来实现。例如,可以使用DISTINCT关键字来去除查询结果中的重复行,或者使用GROUP BY和聚合函数来合并重复数据。
检查同步配置
确认DataWorks中的同步配置是否正确。包括同步任务名称、同步任务描述、同步任务参数等是否设置得当。特别是表映射和字段映射部分,需要确保没有错误地将多个数据源中的相同数据映射到ODPS表的同一行或列中。
查看日志和监控
如果以上方法都无法解决问题,建议查看DataWorks的同步日志和监控信息。通过日志和监控信息,可以了解同步过程中的详细情况,包括哪些数据被同步了、同步过程中是否出现了错误等。这有助于定位问题所在,并采取相应的解决措施。
咨询技术支持
如果问题依然无法解决,建议联系阿里云的技术支持团队。他们可以提供更专业的帮助和解决方案,以确保DataWorks的离线同步过程能够正常运行并避免数据重复的问题。
综上所述,解决DataWorks中ODPS库表设置主键后离线同步出现数据重复的问题需要综合考虑多个方面,包括数据源检查、唯一标识字段使用、增量同步策略、数据去重处理、同步配置检查、日志和监控查看以及技术支持咨询等。
在DataWorks中,如果odps的库表设置了主键,离线同步时出现数据重复的情况,可以通过以下方法解决:
检查源数据是否有重复:首先需要确认源数据是否存在重复数据,如果有,需要在源数据层面进行处理,确保数据的唯一性。
使用odps SQL进行去重处理:在odps SQL中,可以使用DISTINCT关键字或者GROUP BY子句来去除重复的数据。例如:
sql
复制代码运行
SELECT DISTINCT column1, column2, ...
FROM your_table;
或者
sql
复制代码运行
SELECT column1, column2, ...
FROM your_table
GROUP BY column1, column2, ...;
使用分区表和分桶表:通过创建分区表或分桶表,可以将数据按照某个字段进行分区或分桶,从而减少数据重复的可能性。例如:
sql
复制代码运行
CREATE TABLE partitioned_table (
column1 STRING,
column2 STRING,
...
)
PARTITIONED BY (partition_column STRING);
使用增量同步:在进行离线同步时,可以选择只同步新增或更新的数据,而不是全量同步。这样可以避免重复数据的导入。具体实现方式取决于你使用的同步工具或框架。
使用唯一约束:在odps表中设置唯一约束,确保插入的数据不会违反唯一性约束。例如:
sql
复制代码运行
ALTER TABLE your_table
ADD CONSTRAINT unique_constraint_name UNIQUE (column1, column2, ...);
总之,解决数据重复的问题需要从源头、数据处理和同步策略等多方面进行考虑和处理。
在DataWorks中,如果您遇到ODPS库表已设置主键,但在进行离线数据同步时出现数据重复的情况,这可能是由于源端数据更新操作导致的。具体而言,如果源端(如MongoDB)进行了先删除后插入(delete followed by insert)的操作,而在目标端ODPS中对相应记录进行了主键约束,这将导致同步过程中出现主键冲突,进而看似数据重复
优化同步策略:
"concurrent": 1,这有助于按顺序处理数据,避免因并发导致的主键冲突问题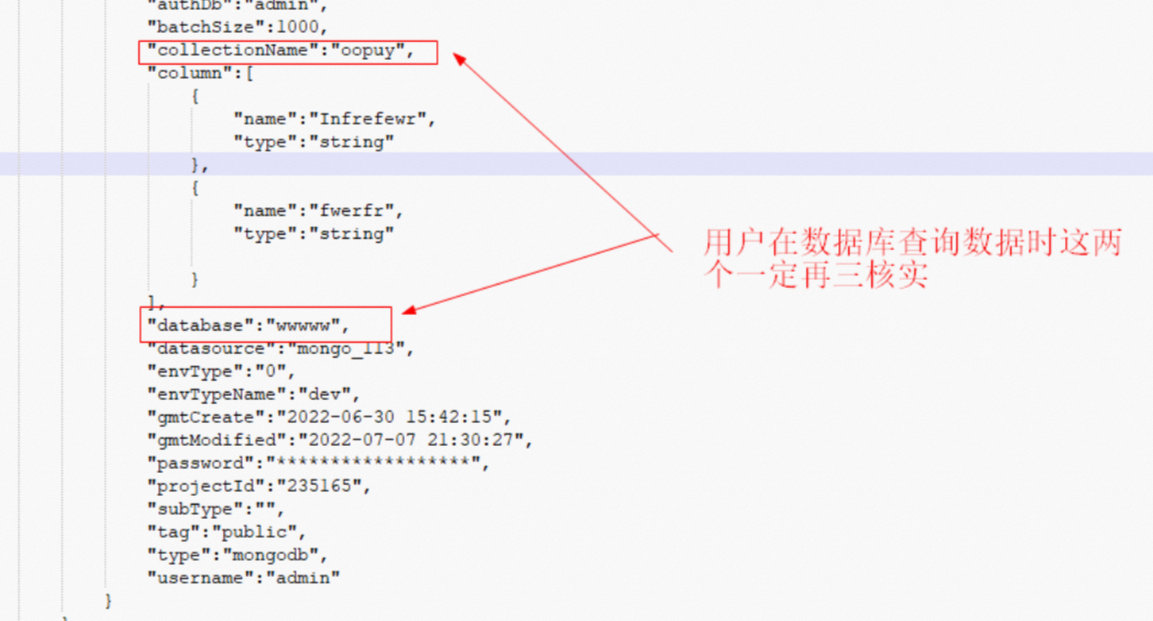
如果你在同步周期内,数据源被更新或插入了重复的主键数据,那就有可能会导致重复。你需要检查一下数据源在同步周期内没有插入重复的主键数据。并且看看在ODPS表的主键约束设置正确,并且在同步过程中被正确应用。
在 DataWorks 中使用 ODPS (MaxCompute) 时,如果库表设置了主键但仍然出现了数据重复的情况,这可能是由于多种原因造成的。下面是一些可能的原因及解决方案:
INSERT OVERWRITE 语句来替换整个表的内容,同时利用 GROUP BY 或 DISTINCT 来去重。MERGE INTO 语句,可以使用它来进行数据的更新或插入操作。配置去重策略:
如果使用 SQL 语句,可以使用如下示例代码:
-- 创建目标表
CREATE TABLE IF NOT EXISTS target_table (
id INT,
name STRING,
PRIMARY KEY (id) NOT ENFORCED
) LIFECYCLE 30;
-- 清空目标表
TRUNCATE TABLE target_table;
-- 使用 INSERT OVERWRITE 插入新数据
INSERT OVERWRITE TABLE target_table
SELECT DISTINCT id, name
FROM source_table;
监控同步任务:监控同步任务的日志和状态,确保数据正确导入并且没有重复。
有可能是由于源端数据的操作行为导致的,特别是当源数据库执行了UPDATE操作,其本质为先DELETE后INSERT的操作序列,这在ODPS中因主键约束而引发冲突,
你可以看看是否源数据库中进行了导致数据重复的UPDATE操作(即先删除后插入同一条记录)。如果是这种情况,您需要调整源端的数据处理逻辑,避免在同步前产生重复的主键记录。
一般情况下不会出现数据重复的情况,是不是数据源本身就包含重复的数据?
为确保任务运行无误,当您在DataStudio中完成任务开发,并发布至生产环境后,您可以进入运维中心管理离线同步任务、监控任务运行状态、修改同步资源组和查看任务运行日志等。本文列举离线同步任务的常见运维操作。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/maintenance-for-batch-synchronization-nodes?spm=a2c4g.11186623.0.i16
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。