DataWorks整库迁移报错,谁能给看下原因?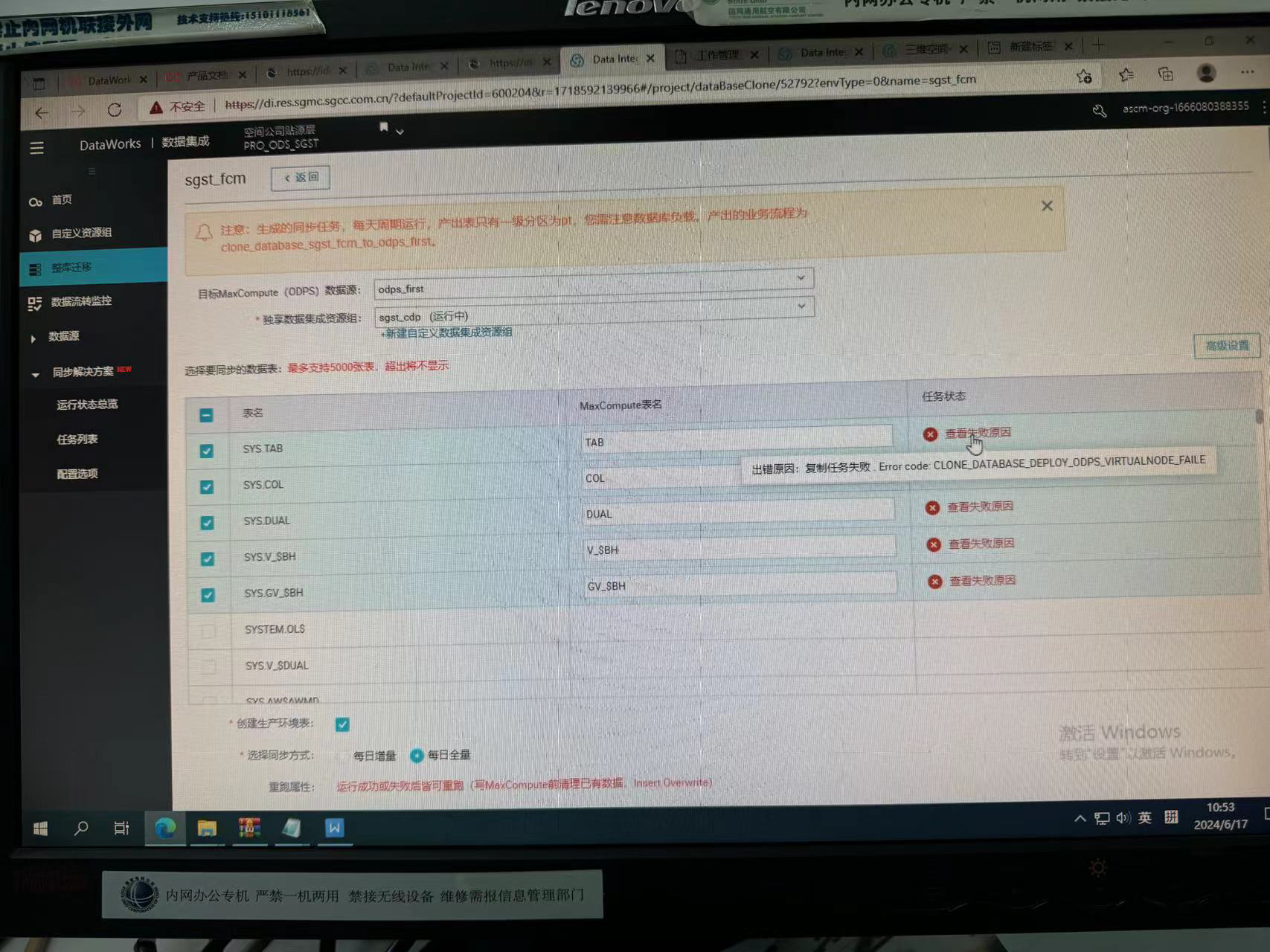
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
访问控制:检查数据库是否设置了访问白名单,确保DataWorks使用的IP地址或IP段已添加到数据库的访问控制列表中。
权限不足:确保所使用的账户拥有足够的权限去访问和操作数据库中的数据,尤其是当涉及到整库迁移时,需要的权限级别可能会更高。
在处理DataWorks整库迁移报错的问题时,用户可能遇到的情况是复杂和多样的。以下是对一些可能原因的详细分析:
数据库连接问题
库表未找到:可能是目标数据库中没有找到相应的表,或者表存在于错误的数据库中。需要确认表所在的库表是否正确,确保数据源配置正确,并且所迁移的表在指定的数据库中确实存在。
网络配置问题:如果数据库位于VPC内,需要确保DataWorks所在的工作空间与数据库实例之间的网络连通性。同时检查安全组规则是否允许从DataWorks工作空间IP地址段访问数据库。
数据源配置错误
配置参数不正确:检查数据源的配置信息,包括主机地址、端口、用户名、密码等是否正确。错误的配置信息会导致无法连接到数据源,从而引发迁移报错。
支持的数据源类型:确认所使用的数据源是否为DataWorks支持的类型。不同的数据源可能需要特定的配置或插件,确认这些依赖已经正确设置。
权限及白名单设置
访问控制:检查数据库是否设置了访问白名单,确保DataWorks使用的IP地址或IP段已添加到数据库的访问控制列表中。
权限不足:确保所使用的账户拥有足够的权限去访问和操作数据库中的数据,尤其是当涉及到整库迁移时,需要的权限级别可能会更高。
任务配置与依赖
上下游依赖错误:检查迁移任务的上下游依赖关系是否正确设置。错误的依赖配置可能导致任务无法正常执行,从而影响整个迁移过程的稳定性和正确性。
任务冻结与资源分配:确认任务未被冻结,且项目下有足够的调度资源供任务运行。任务如果被冻结或资源不足,也会导致迁移任务无法正常启动或执行。
数据兼容性与格式
数据格式不一致:检查原始数据库中的数据格式是否与目标数据库兼容。不兼容的数据格式可能在迁移过程中导致失败或数据丢失。
字符编码问题:确保数据的字符编码在迁移过程中得到正确处理。不正确的编码转换可能导致数据损坏或乱码。
迁移工具与策略
迁移方案选择:选择合适的迁移方案,如整库离线同步,确保所选方案适合当前的迁移需求和支持的数据源类型。
迁移工具使用:利用DataWorks提供的迁移助手工具,它能够简化迁移过程,并提供灵活的迁移选项。通过迁移助手,可以选择性地迁移数据源中的特定数据或任务。
总的来说,DataWorks整库迁移报错可能是由多种因素引起的,从数据库连接问题到数据兼容性问题,再到迁移工具的使用和任务配置问题。解决这些问题需要综合考虑多个方面,仔细检查每一步的配置和设置。通过适当的策略和工具,可以有效地解决迁移中的报错问题,确保数据迁移的顺利进行。
DataWorks整库迁移报错可能由多种原因引起,以下是一些常见的原因及相应的解决方案:
一、常见报错原因
权限问题:
迁移过程中可能没有足够的权限来访问源数据库或目标数据库。
解决方案:确保迁移用户具有足够的权限,包括读取源数据库和写入目标数据库的权限。
网络问题:
网络连接不稳定或网络配置错误可能导致迁移失败。
解决方案:检查网络连接,确保网络稳定且配置正确。如果使用了代理或VPN,请检查相关设置是否影响迁移过程。
数据源配置错误:
数据源地址、端口、用户名、密码等配置信息错误可能导致迁移失败。
解决方案:仔细检查数据源配置信息,确保所有信息都准确无误。
版本兼容性问题:
源数据库和目标数据库的版本不兼容可能导致迁移失败。
解决方案:确认源数据库和目标数据库的版本是否兼容,如果不兼容,可能需要考虑升级或降级其中一个数据库。
数据一致性问题:
在迁移过程中,如果源数据库的数据发生变化,可能会导致数据不一致。
解决方案:在迁移过程中保持源数据库的稳定,避免在迁移过程中修改数据。如果必须修改数据,请确保在迁移前做好相应的数据备份和恢复计划。
迁移工具或脚本问题:
使用的迁移工具或脚本可能存在bug或配置错误。
解决方案:检查迁移工具或脚本的官方文档,查看是否有已知的bug或配置要求。尝试更新到最新版本或使用其他可靠的迁移工具。
数据格式或类型不匹配:
源数据库和目标数据库之间的数据格式或类型不匹配可能导致迁移失败。
解决方案:在迁移前对数据进行格式和类型的检查,确保它们在目标数据库中能够正确存储和表示。
二、具体解决步骤
查看错误信息:
在迁移过程中,仔细查看错误信息,了解具体的报错原因。
检查配置:
根据错误信息,检查相关的配置信息,如数据源配置、网络配置等。
联系技术支持:
如果自己无法解决问题,可以联系DataWorks的技术支持团队,寻求专业的帮助。
查看官方文档和社区:
访问阿里云官方文档和开发者社区,查找是否有类似的问题和解决方案。
进行小范围测试:
在进行整库迁移之前,可以先进行小范围的数据迁移测试,以验证迁移过程的正确性和稳定性。
备份和恢复计划:
在迁移过程中,确保有完善的备份和恢复计划,以防万一迁移失败或数据丢失。
综上所述,DataWorks整库迁移报错可能由多种原因引起,需要根据具体的错误信息来诊断问题并采取相应的解决方案。在迁移过程中,务必保持谨慎和耐心,确保数据的完整性和一致性。
参考4条信息源
DataWorks通过空间预设角色或空间自定义角色与开发环境引擎Role映射,来让被授予空间角色的RAM用户,拥有该空间角色映射的开发引擎Role所拥有的MaxCompute引擎权限,但默认无生产权限
DataWorks预置了空间预设角色,同时提供了自定义空间角色的功能,来控制用户是否可以使用DataWorks空间级模块、是否有开发引擎项目权限。但无论预设角色还是自定义角色,都可以通过预设或手动授权的方式使角色拥有开发引擎项目的相关权限。
在 DataWorks 中进行整库迁移时遇到错误 CLONE_DATABASE_DEPLOY_ODPS_VIRTUALNODE_FAIL,这通常表示在尝试复制数据库的过程中遇到了问题,特别是与 MaxCompute (ODPS) 相关的虚拟节点部署失败。这可能是由多种原因引起的,下面是一些排查和解决此问题的步骤:
貌似是使用DataWorks进行整库迁移时,克隆数据库到MaxCompute过程中部署虚拟节点失败。检查目标MaxCompute项目是否有足够的资源(如VPC、安全组配置、虚拟节点等)来支持迁移操作,特别是虚拟节点的配置与状态,这是报错的关键点
复制任务失败的原因是:部署ODPS虚拟节点失败
一个业务流程存在多个分支结果时,您需要新建一个虚拟节点(例如,业务流程end虚拟节点),业务流程end虚拟节点依赖上游多个分支结果,当业务流程end虚拟节点执行成功,则表示该业务流程执行完成。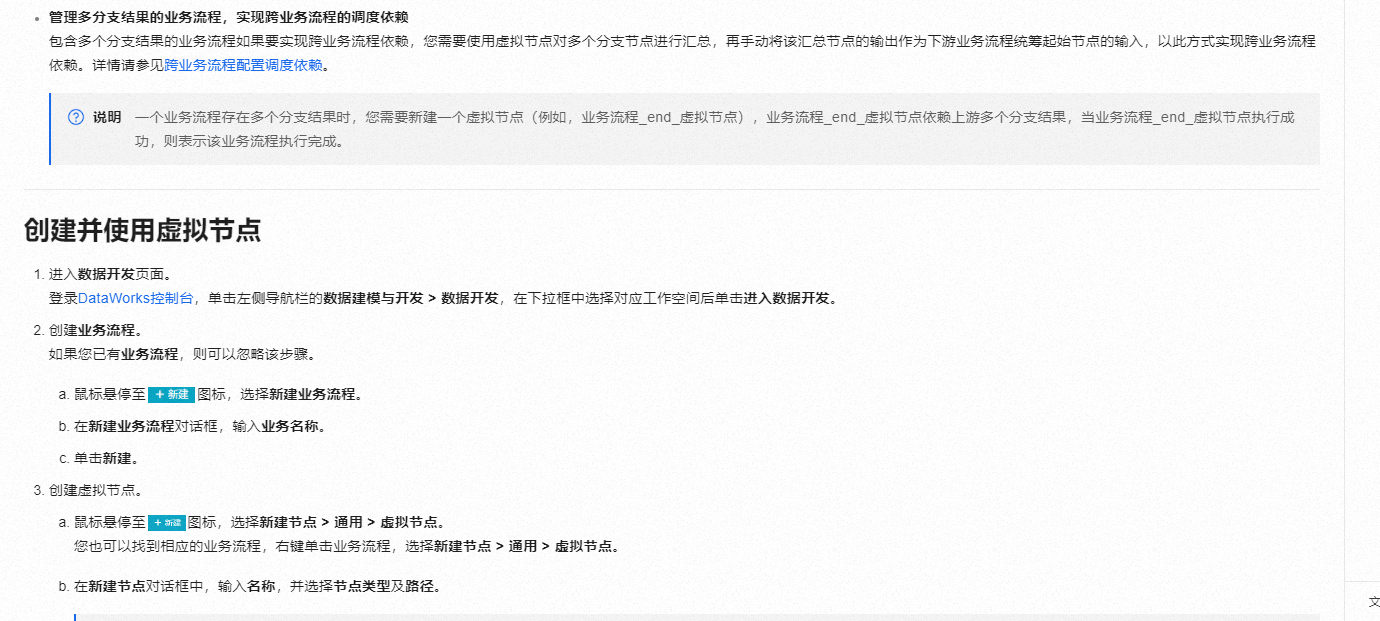
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。