Apache Flink 的完整性推理方案是如何设计的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
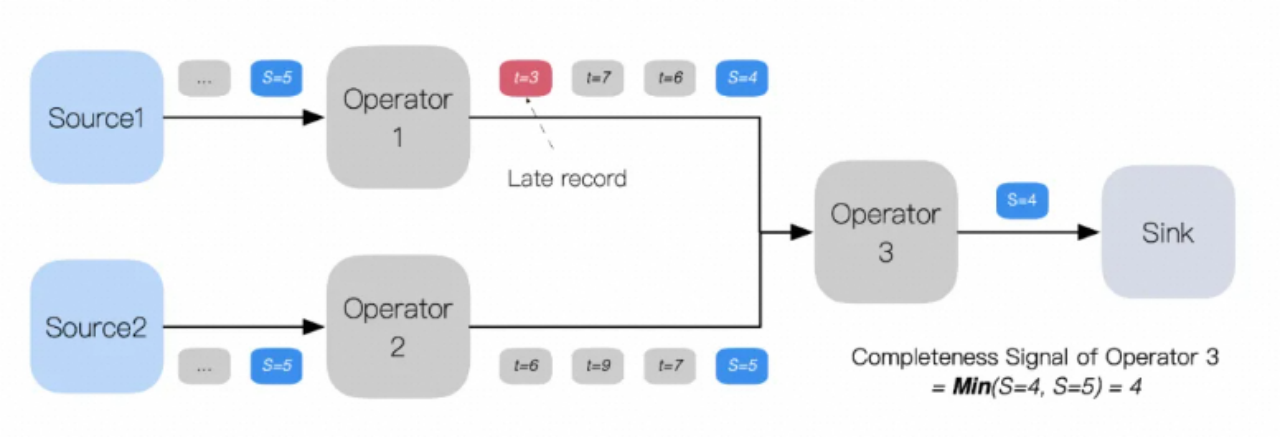
Apache Flink 的完整性推理方案设计思路源于 DataFlow 模型,核心围绕低水印设计。生产阶段,Flink 程序可以在源节点或专用水印生成节点中生成水印,基于进入引擎的流数据或其他数据源信息(如 Kafka 分区、偏移量或时间戳等)来计算水印。传播阶段,水印作为特殊元数据消息与常规流数据一起发送给下游节点,下游节点取所有输入水印的最小值作为当前节点的水印,并更新转发大于前一个水印的新水印以保持完整性信号的严格单调性。消费阶段,当水印抵达节点时,会触发一系列定时器,结果发送到下游,新的水印值广播到所有下游节点,实现分布式应用的状态同步。