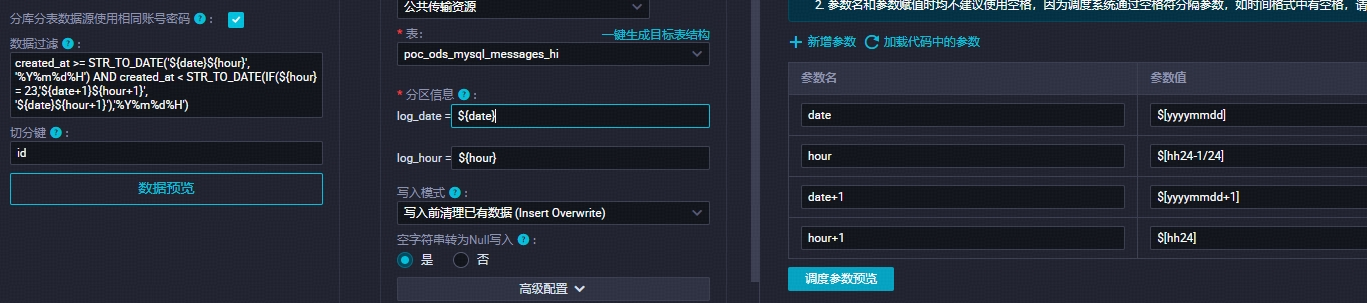
dataworks小时增量表日期小时二级分区,调度参数和过滤语句设置如下: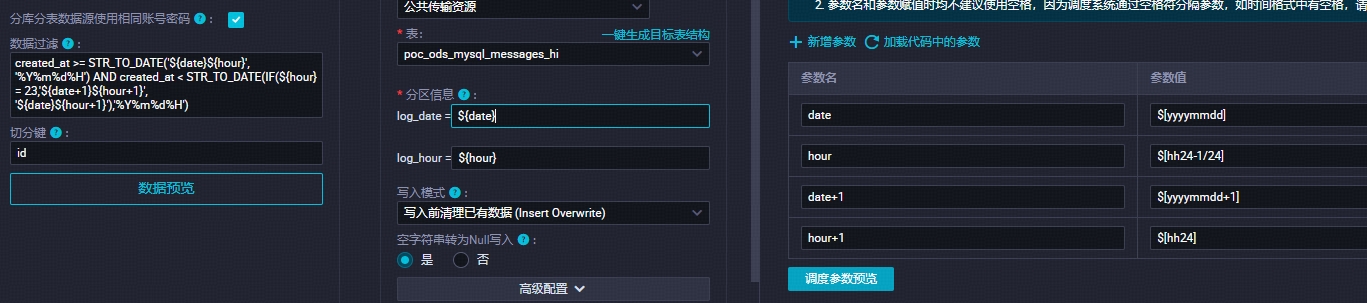
发现23点分区如下:
左为分区,右为执行时间

如何解决23点分区天多一天的问题呢
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要解决DataWorks中小时增量表日期小时二级分区调度导致23点分区日期多一天的问题,可以采用以下方法进行调整: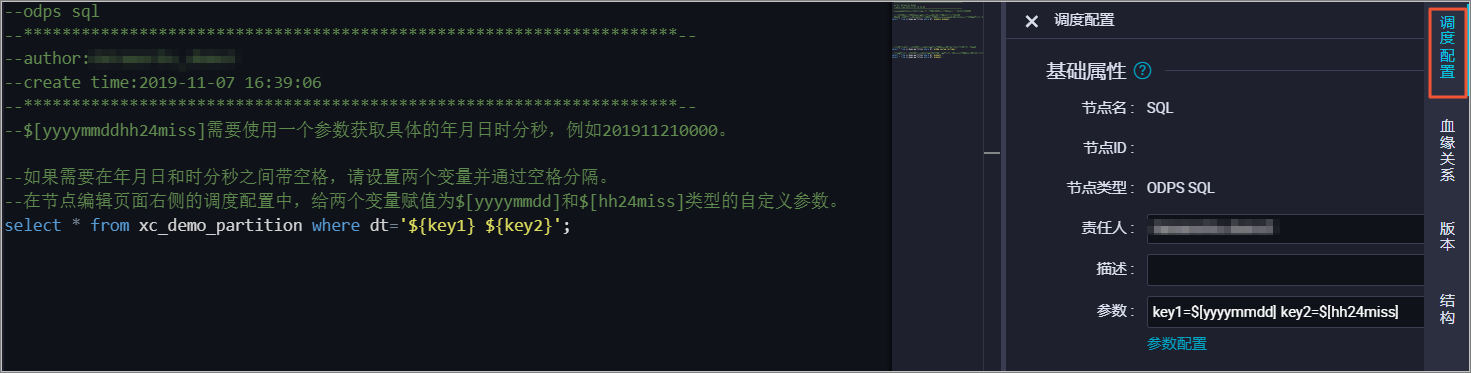
修改调度参数的计算逻辑:
当前您的调度参数可能直接使用了 $[hh24-1/24] 来获取上一小时的时间,这在每天的23点时会变为当天的22点,但在0点时会错误地变为前一天的23点。为了解决跨天问题,您可以调整小时参数的计算公式,特别是在日期转换上做特殊处理。根据参考资料建议,可以将日期参数(day)设置为 $[yyyymmdd-1/24],这样在每天的0点时,日期会回溯到前一天,而小时参数(hour)继续保持 $[hh24-1/24] 的计算方式。这样,即使在23点执行时,日期也会正确显示为当天,小时为22点;而在0点执行时,日期会正确显示为前一天,小时为23点。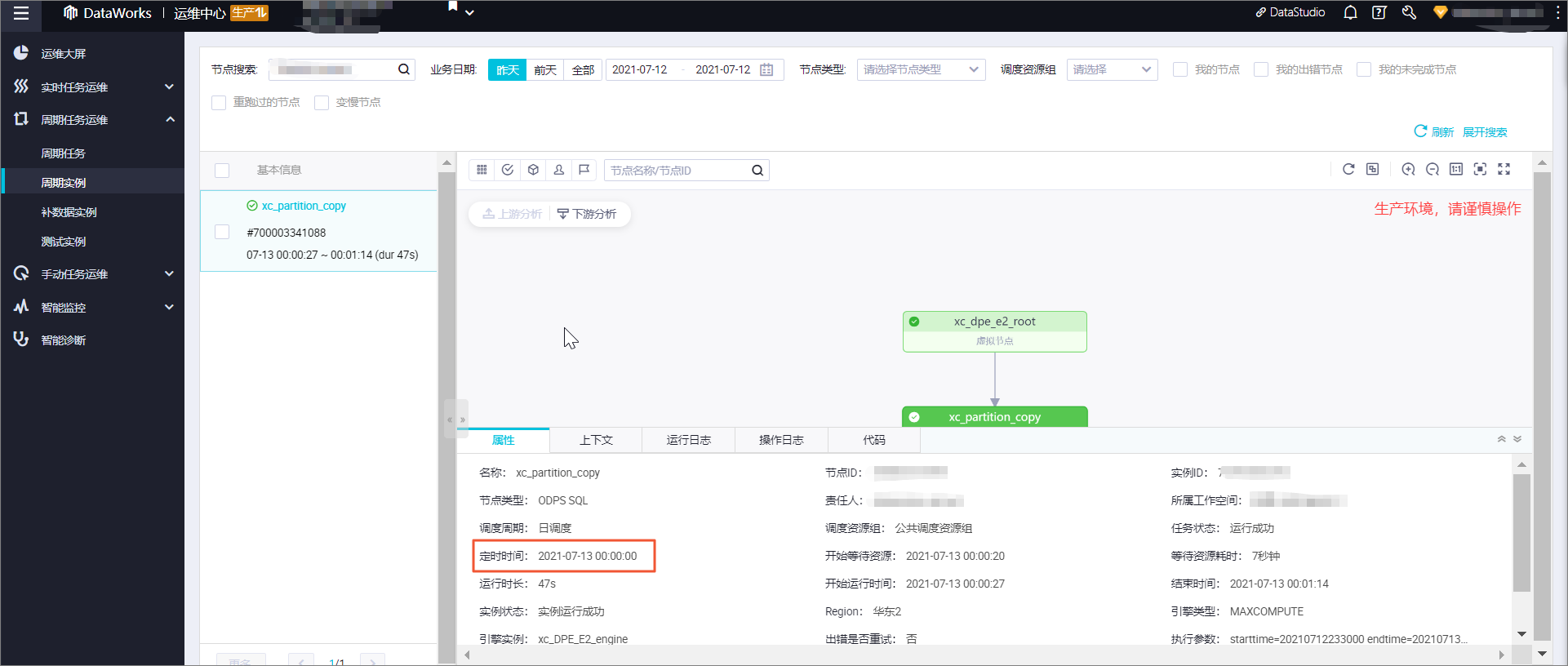
配置示例:
datetime=[yyyymmdd-1/24]:确保在每天的0点时,日期回溯到前一天。hour=[hh24-1/24]:获取上一个小时的小时数,正常处理每个小时的情况。PARTITION (day=${datetime}, hour=${hour})。通过上述调整,可以确保在每天的23点执行时,生成的分区日期不会提前跳转到下一天,而是保持为正确的当天日期。
相关链接 https://help.aliyun.com/zh/dataworks/support/scheduling-parameters
DataWorks小时增量表日期小时二级分区调度导致23点分区日期多一天的问题,可能是由于调度任务的时间设置不正确导致的。请检查以下几点:
确保调度任务的时间设置正确。例如,如果希望每小时执行一次任务,那么任务的触发时间应该设置为每小时的第0分钟。
检查分区策略是否正确。确保分区策略是根据日期和小时进行划分的。例如,可以使用dt='yyyy-MM-dd/HH'作为分区字段。
检查数据处理逻辑是否正确。确保在处理数据时,能够正确地识别并处理跨天的情况。例如,可以在数据处理过程中判断当前时间是否为23点,如果是,则将日期加1。
如果问题仍然存在,可以尝试调整调度任务的时间间隔,例如每半小时或每两小时执行一次任务,以减少跨天情况的发生。
DataWorks小时增量表在采用日期和小时作为二级分区时,如果出现23点分区日期多一天的问题,这通常与UTC时间和本地时间(如北京时间)之间的差异,以及分区策略的配置有关。以下是一些可能的原因和解决方案:
原因分析
时区差异:
MaxCompute(原名ODPS)中的分区是按照UTC时间进行划分的,而UTC时间与北京时间存在8小时的时差。因此,当本地时间(如北京时间)为23点时,UTC时间可能已经是次日的0点或接近0点,导致分区被错误地划分为次日。
分区策略配置不当:
在DataWorks中配置分区时,如果没有正确处理时区转换或分区计算逻辑,可能会导致分区日期不准确。
解决方案
调整分区计算逻辑:
修改分区计算逻辑,以确保它考虑到UTC时间和本地时间之间的差异。例如,在计算小时分区时,可以将本地时间转换为UTC时间,然后再进行分区计算。
使用DataWorks的内置函数或自定义函数来处理时区转换,确保分区值的准确性。
手动设置分区值:
如果自动计算分区值存在困难,可以考虑在创建分区时手动设置分区值。例如,对于北京时间23点的数据,可以手动将其设置为UTC时间的相应小时(可能是前一天的某个小时,取决于具体的时间点)。
优化调度配置:
检查DataWorks的调度配置,确保调度时间与分区策略相匹配。如果调度时间设置不当,也可能导致分区日期错误。
考虑在调度任务时加入时区转换的逻辑,以确保任务在正确的时间点执行。
使用动态分区:
如果DataWorks支持动态分区,并且你的应用场景适合使用动态分区,那么可以考虑使用动态分区来自动处理分区值的计算和划分。
动态分区可以根据数据的实际生成时间来自动计算分区值,从而避免手动设置分区值可能带来的错误。
查看日志和文档:
查看DataWorks的调度日志和分区日志,以了解分区划分和调度执行的具体情况。
查阅DataWorks的官方文档和社区支持,以获取更多关于分区策略和时区处理的建议和最佳实践。
注意事项
在调整分区策略和调度配置时,请务必谨慎操作,以避免对现有数据造成不必要的影响。
如果你的应用场景对时间精度要求较高,建议在进行任何调整之前先进行测试和验证。
考虑到时区差异和DataWorks的更新迭代,建议定期检查和更新你的分区策略和调度配置。
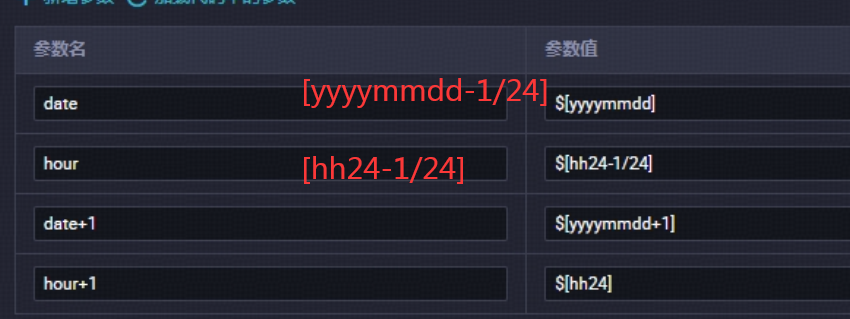
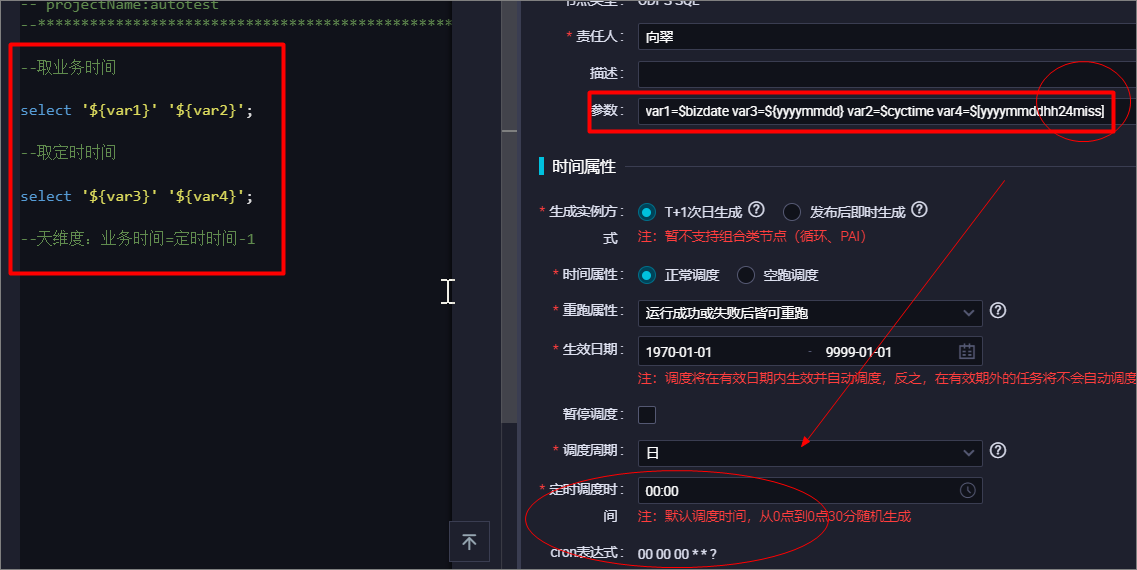
你可以修改参数的计算公式,将datetime设置为$[yyyymmdd-1/24],hour的计算公式仍然是$[hh24-1/24]
代码中设置day=datetime, hour={hour},
节点配置参数赋值datetime=[yyyymmdd-1/24],hour=[hh24-1/24]
在 DataWorks 中使用小时增量表时,如果日期小时二级分区的调度导致 23 点的分区日期多了一天,这通常是由于分区生成逻辑或调度配置不正确所导致的。下面是一些排查和解决此问题的步骤:
date_format(current_timestamp, 'yyyy-MM-dd') 和 date_format(current_timestamp, 'HH')。'yyyy-MM-dd' 和 'HH' 格式来分别生成日期和小时部分。STRING 类型。以下是一个示例 SQL 语句,用于创建一个带有日期和小时分区的表:
CREATE TABLE IF NOT EXISTS my_hourly_table (
id INT,
data STRING,
-- 其他列...
)
PARTITIONED BY (dt STRING, hr STRING);
-- 添加分区
ALTER TABLE my_hourly_table ADD PARTITION (dt='2023-08-13', hr='23');
在这个例子中,dt 和 hr 分别代表日期和小时。确保 SQL 语句中的日期生成逻辑正确处理 23 点的情况。
这种情况通常发生在按小时分区的数据表中,特别是在日期变更的边界时段。
解决方案是调整时间参数的设置,确保在0点执行的任务能够正确选取当天0点的数据而非前一天23点的数据。例如,可以探索使用其他形式的时间参数或自定义时间格式来满足需求。
您可使用两个自定义变量进行赋值,具体如下:
年月日:参数datetime=$[yyyy-mm-dd]
时分秒:参数hour=$[hh24:mi:ss]
分别获取日期和时间后,在代码中使用空格拼接为pt=${datetime} ${hour}。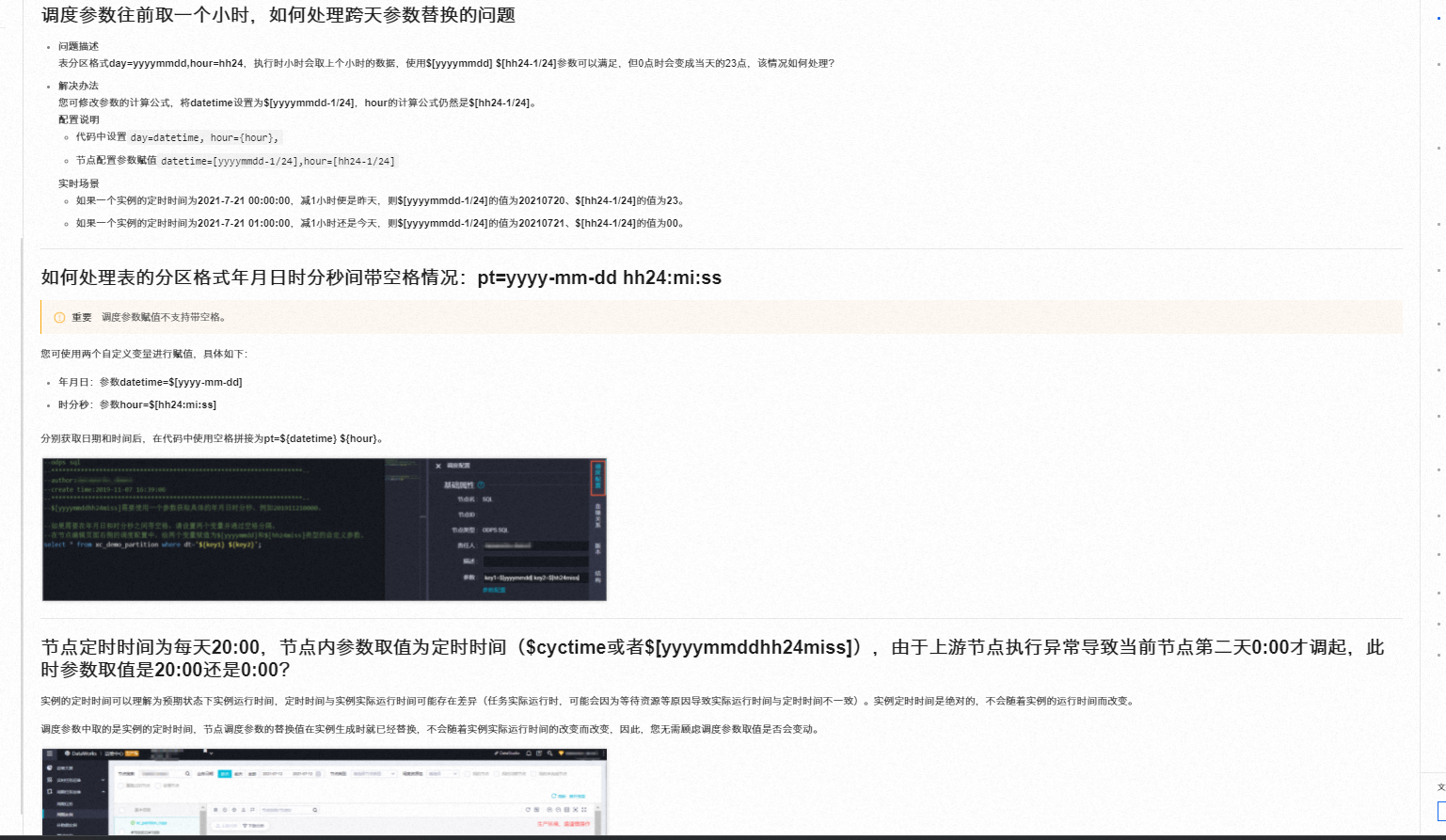
https://help.aliyun.com/zh/dataworks/support/scheduling-parameters?spm=a2c6h.13066369.question.12.5cdc53ccIDITaI
可以修改一个计算方式
对于日期(day)的参数,原使用 $[yyyymmdd] 会导致在0点时取到的是当天的日期,从而23点分区会标记为第二天。为解决此问题,应将日期参数的计算公式调整为 $[yyyymmdd-1/24]。这样,在每天的0点执行时,会取到前一天的日
调度参数往前取一个小时,如何处理跨天参数替换的问题
问题描述
表分区格式day=yyyymmdd,hour=hh24,执行时小时会取上个小时的数据,使用$[yyyymmdd] $[hh24-1/24]参数可以满足,但0点时会变成当天的23点,该情况如何处理?
解决办法
您可修改参数的计算公式,将datetime设置为$[yyyymmdd-1/24],hour的计算公式仍然是$[hh24-1/24]。
配置说明
代码中设置day=datetime, hour={hour},
节点配置参数赋值datetime=[yyyymmdd-1/24],hour=[hh24-1/24]
实时场景
如果一个实例的定时时间为2021-7-21 00:00:00,减1小时便是昨天,则$[yyyymmdd-1/24]的值为20210720、$[hh24-1/24]的值为23。
如果一个实例的定时时间为2021-7-21 01:00:00,减1小时还是今天,则$[yyyymmdd-1/24]的值为20210721、$[hh24-1/24]的值为00。
参考文档https://help.aliyun.com/zh/dataworks/support/scheduling-parameters?spm=a2c4g.11186623.0.i149
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。