Dataworks里 代码行过长(1700行) 提交报错?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,代码行过长可能会导致提交失败。为了解决这个问题,你可以尝试以下方法:
检查代码是否有不必要的重复或冗余部分,尝试优化代码结构,减少代码行数。
如果代码确实需要较长的行数,可以考虑将代码拆分成多个较小的文件,然后在DataWorks中将这些文件合并为一个项目。这样可以降低单个文件的行数,避免提交失败。
如果你使用的是Python或其他支持多行字符串的语言,可以将较长的代码行拆分成多行,以提高代码的可读性。例如,在Python中,可以使用三引号('''或""")来创建多行字符串。
如果以上方法都无法解决问题,建议联系阿里云技术支持寻求帮助。他们可以提供更详细的解决方案,并帮助你解决提交失败的问题。
在 Dataworks 中遇到代码行过长(1700 行)提交报错的情况,您可以考虑以下几种解决方法:
1. 分割代码:
将过长的代码块拆分成多个较小的函数或模块,以提高代码的可读性和可维护性。例如,如果是一个复杂的数据处理逻辑,可以将其拆分为多个步骤,每个步骤写成一个独立的函数。
2. 提取重复逻辑:
检查代码中是否存在重复的逻辑或代码片段,将其提取为单独的函数或方法,从而减少代码的行数。
3. 优化数据结构:
有时候,过长的代码可能是由于使用了不太合适的数据结构导致的。重新评估数据的存储和处理方式,选择更高效的数据结构,可能会使代码更加简洁。
4. 注释和文档:
为代码添加清晰的注释和文档,解释每个部分的功能和逻辑,这样即使代码行数较多,也能让其他人(包括未来的自己)更容易理解和维护。
5. 检查代码规范:
确保您的代码符合 Dataworks 的代码规范和最佳实践,可能存在某些规定限制了代码行的长度。
例如,假设您的 1700 行代码主要是在进行一系列的数据清洗和转换操作,可以将不同的数据清洗步骤提取为单独的函数,如 clean_data_column1() 、 transform_data_column2() 等。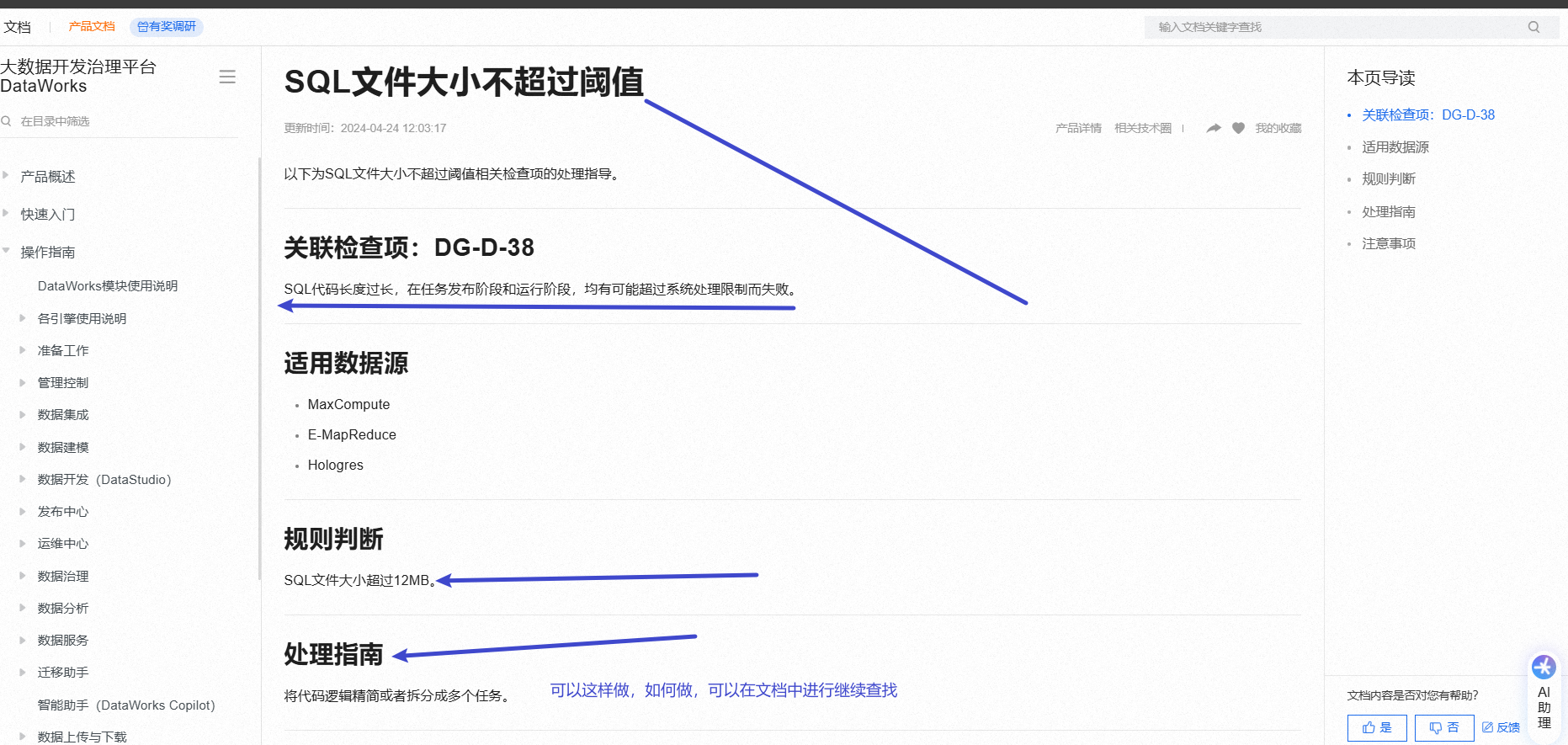
Dataworks是阿里云上的一款大数据开发工具,它支持多种编程语言和数据处理框架。如果你在提交代码时遇到“代码行过长”的错误,这可能是由于你的代码超过了Dataworks允许的最大行数限制(通常为1000行)。
为了解决这个问题,你可以尝试以下方法:
分割代码文件 :将代码拆分成多个较小的文件,每个文件的行数不超过1000行。这样可以避免单个文件超过限制的问题。
优化代码结构 :检查代码中是否有重复或不必要的部分,尝试重构代码以减少行数。例如,可以将一些功能封装成函数或类,以便在不同的文件中调用。
使用注释 :如果某些代码段非常复杂且难以简化,可以考虑添加注释来解释这些代码的功能。虽然注释本身不计入行数限制,但它们可以帮助其他人理解和维护代码。
联系技术支持 :如果以上方法都无法解决问题,你可以联系阿里云的技术支持团队寻求帮助。他们可能会为你提供更具体的解决方案,或者调整Dataworks的限制设置。
请注意,不同的项目和团队可能有不同的代码规范和限制。确保遵循团队内部的代码风格和最佳实践,以提高代码质量和可维护性。
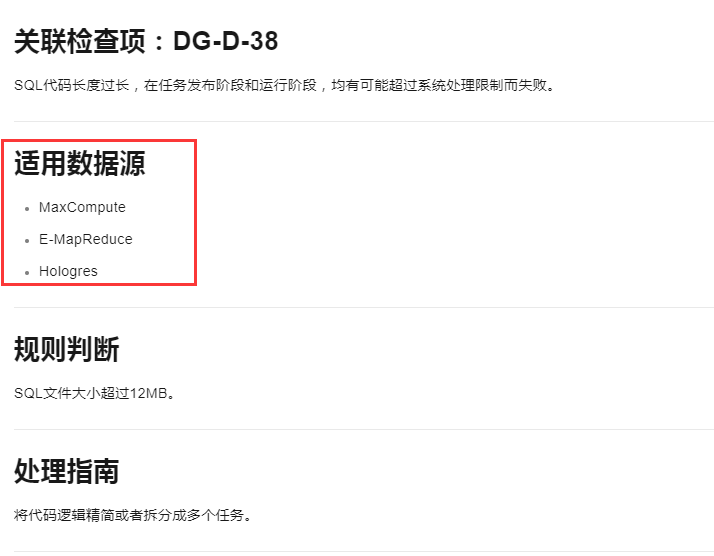
DataWorks中SQL代码长度过长可能会导致任务失败。如果您的代码有1700行,这可能超出了系统的处理限制。建议您将代码逻辑精简或拆分成多个任务来解决。具体处理指南可参考大数据开发治理平台DataWorks的文档中的DG-D-38检查项。记得在调整代码时注意不要超过12MB的文件大小限制。
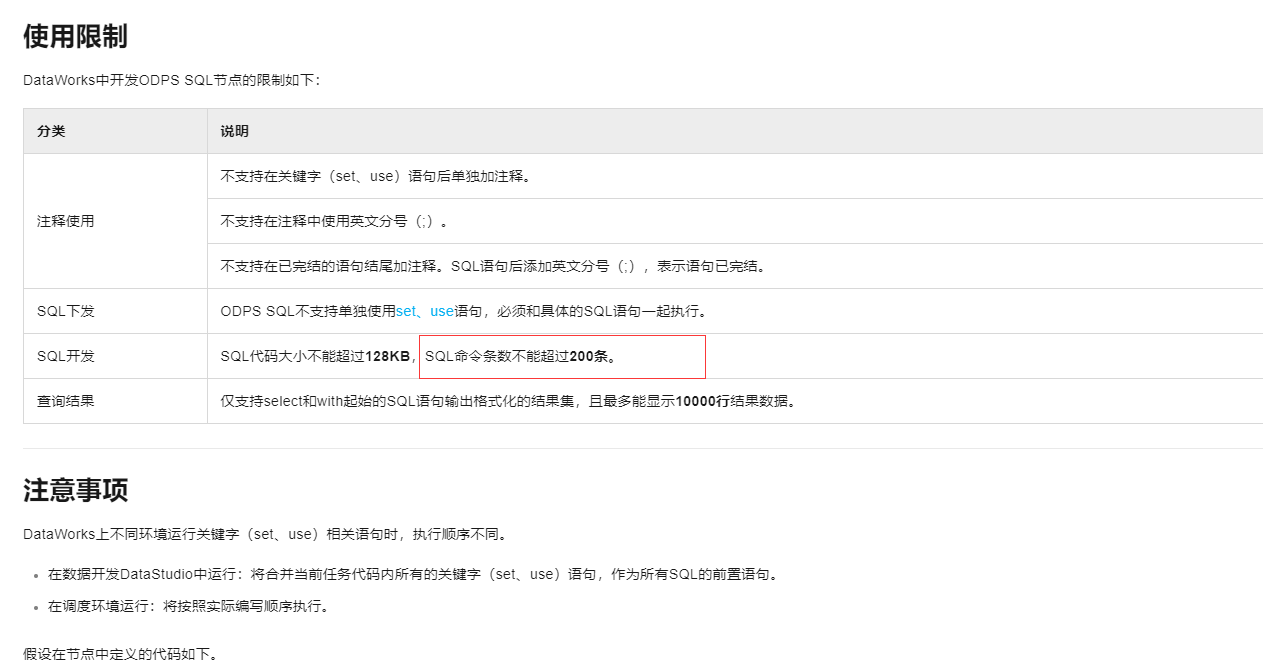
单个节点中的SQL命令条数不超过200条吧,
并且你可以将过长的SQL语句进行合理拆分,将其分为多个较小的、独立可执行的SQL片段。这样每个部分都不会超过大小限制,从而避免提交时的报错。
当您在DataWorks中提交代码时遇到因代码行过长而报错的情况,这通常是因为DataWorks对单个脚本文件的大小有一定的限制。虽然DataWorks没有明确的代码行数限制,但是文件过大可能导致上传失败或执行异常。以下是一些解决这类问题的方法:
将大型脚本拆分为多个较小的脚本或函数,并使用DataWorks的工作流功能将它们串联起来。这样可以确保每个脚本都在合理的大小范围内。
如果您正在使用SQL或类似的查询语言,并且代码中有大量的UDF定义,可以考虑将这些UDF定义为独立的函数,并在需要的地方引用它们。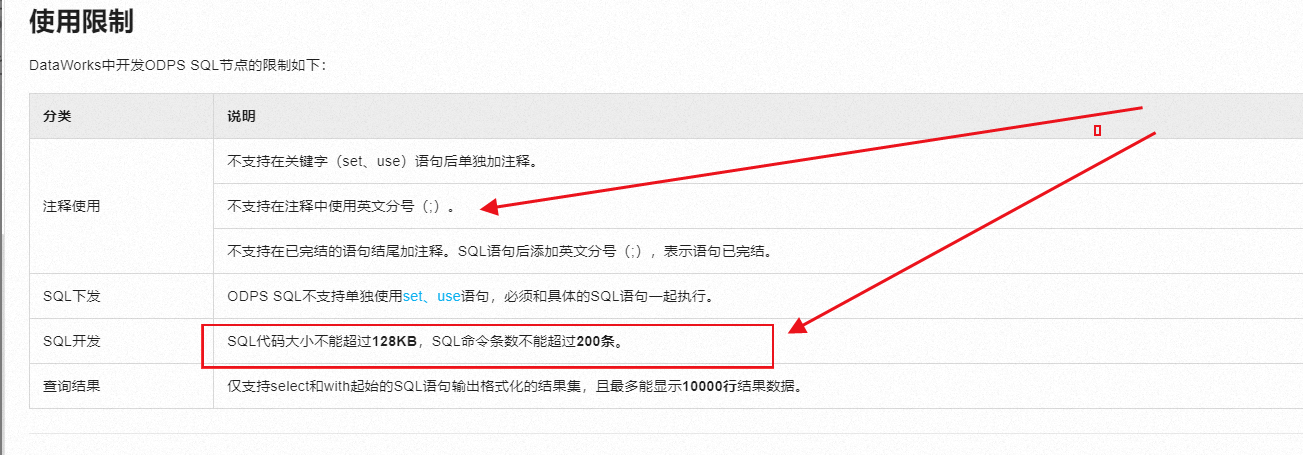
如果您的代码主要由SQL查询组成,并且包含了大量的JOIN或子查询,您可以尝试调整Spark的配置以优化性能。例如,增加shuffle partition的数量,调整内存分配等。
如果您正在使用Python或Scala编写复杂的逻辑,可以考虑使用PySpark或MapReduce来处理大规模数据,这些框架更适合处理大型数据集和复杂逻辑。
建议你拆分一下代码运行
将过长的脚本拆分为多个逻辑上独立的代码片段或函数。这样不仅可以减少单个文件的大小,还能提高代码的可读性和可维护性。确保每个部分负责单一职责,遵循编程中的“高内聚,低耦合”原则
SQL开发:
SQL代码大小不能超过128KB,SQL命令条数不能超过200条。
查询结果:
仅支持select和with起始的SQL语句输出格式化的结果集,且最多能显示10000行结果数据。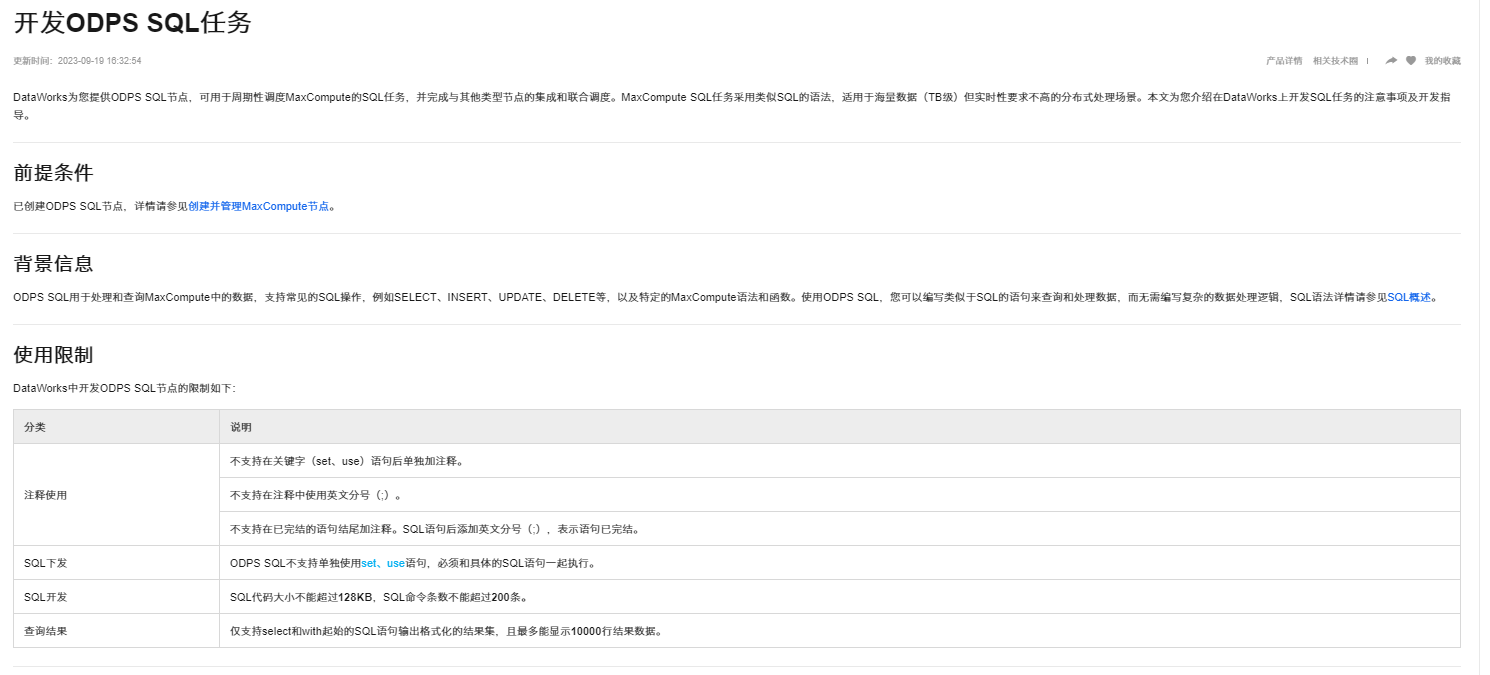
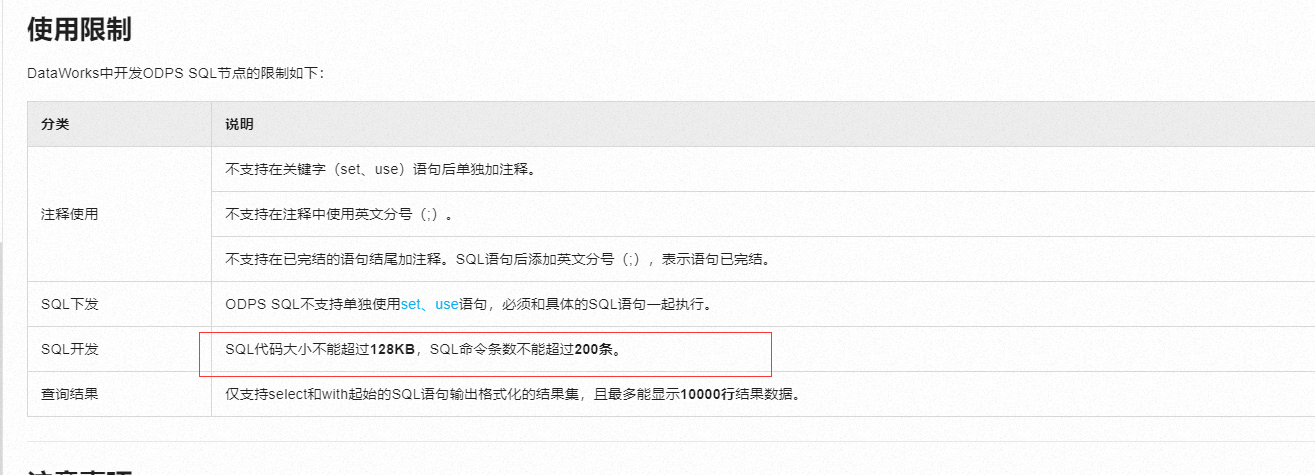
SQL开发
SQL代码大小不能超过128KB,SQL命令条数不能超过200条。
SQL代码大小不能超过128KB,SQL命令条数不能超过200条。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/create-an-odps-sql-node?spm=a2c4g.11186623.0.i318
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。