请教一下,emr-flink 的flinkSQL如何只针对source表单独设置并行度呢?比如kafka source表。
kafka source表如果使用全局并行度的话灵活度会很差,全局并行度比较多的话kafka-topic也没那么多分区?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要在EMR-Flink的Flink SQL中针对source表单独设置并行度,尤其是对于Kafka source表,您可以遵循以下步骤操作:
开启多SSG模式:
配置Source算子的并行度:
应用并确认设置:
通过以上步骤,您可以为Kafka source表单独设置并行度,不必受限于全局并行度设置,从而更好地适配不同topic分区数的场景,避免资源过度分配或不足的问题。
相关链接
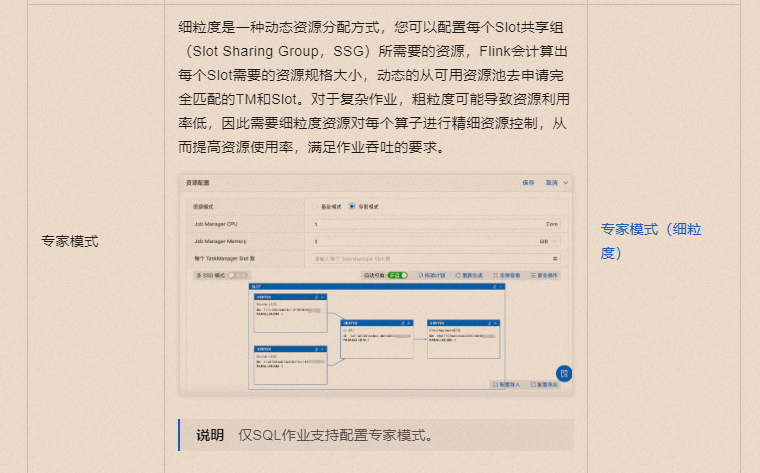
配置作业资源 专家模式(细粒度) https://help.aliyun.com/zh/flink/user-guide/configure-deployment-resources
这通常是通过使用 Flink SQL 的动态分区(Dynamic Partitioning)功能来实现的,该功能允许您根据特定的条件动态地分配分区。
以下是设置 Kafka 源的并行度的步骤:
创建 Kafka 表:首先,您需要创建一个 Kafka 表来指定 Kafka 源的详细信息。在创建 Kafka 表时,您可以通过设置并行度参数来指定每个分区的并行度。
使用动态分区:在您的 Flink SQL 查询中,您可以使用动态分区功能来根据您的业务逻辑来分配分区。动态分区允许您在查询中指定分区键,并根据这个键来分配分区。
指定并行度:在创建 Kafka 表时,您可以指定每个分区的并行度。这通常是通过设置表属性来实现的,例如:
在这里,'parallelism' = 'your_parallelism' 指定了每个分区的并行度。您需要根据您的 Kafka 主题的分区数来调整这个值。
您可以在Flink SQL中针对特定的源表设置并行度。对于Kafka Source,您可以使用WITH语句来配置源表的并行度。例如:
在这里,your_desired_parallelism替换为您想要的并行度值。这样即使全局并行度很高,Kafka Source表也可以按照您指定的并行度运行,提高系统的灵活性。请确保设置的并行度不超过Kafka主题的分区数,以避免并行度过大导致数据不完整。
基于 Flink Streaming api,要给 Kafka Source 指定并行度,只需要在 env.addSource() 后面调用 setParallelism() 方法指定并行度就可以,如下:
val kafkaSource = new FlinkKafkaConsumer[ObjectNode](topic, new JsonNodeDeserializationSchema(), Common.getProp)
val stream = env.addSource(kafkaSource)
.setParallelism(12)
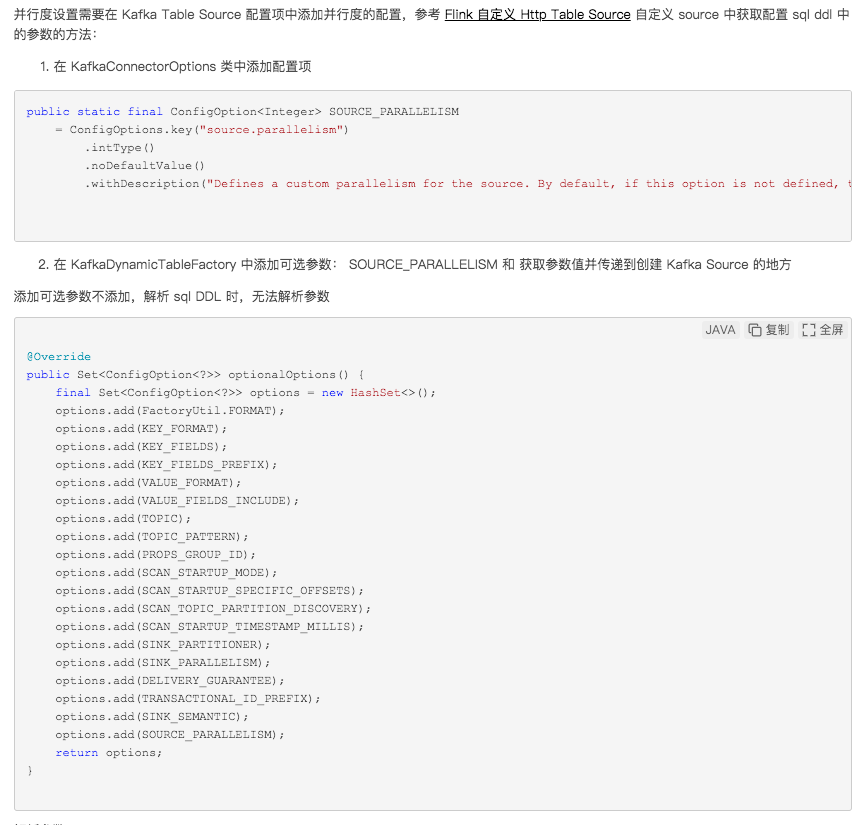
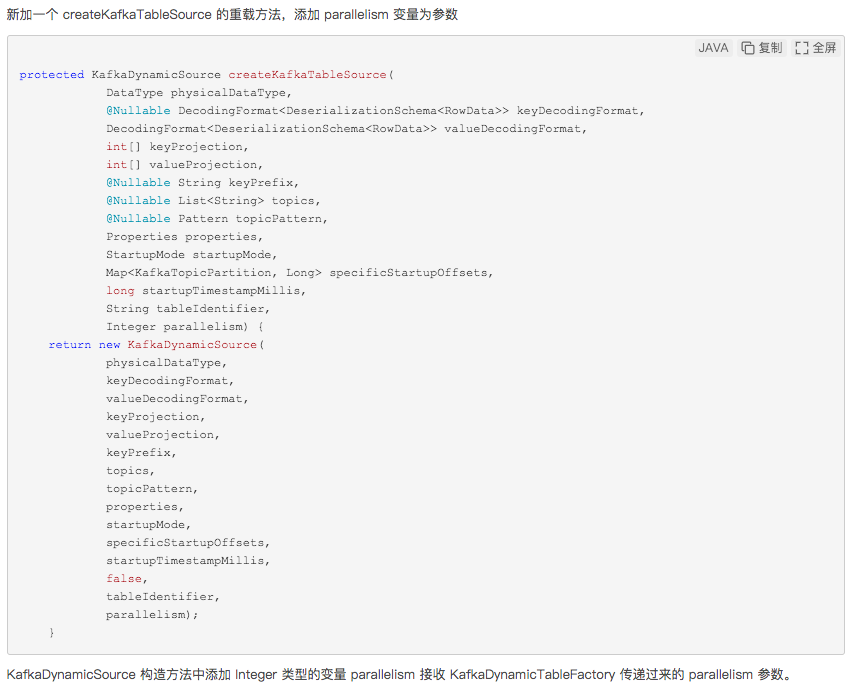
——参考链接。
在EMR-Flink或任何Flink环境中,你不能直接在Flink SQL中单独为source表设置并行度。Flink SQL的并行度通常受到作业的整体并行度和数据源连接器的并行度属性的影响。然而,你可以通过以下几种方式间接控制source的并行度:
修改整体并行度:
你可以通过修改Flink集群的默认并行度或在提交作业时通过参数指定并行度,从而间接影响source的并行度。例如,使用--parallelism参数提交Flink作业。
在DDL语句中指定并行度:
虽然在Flink SQL中直接设置source的并行度不被直接支持,但你可以在创建source的DDL语句中尝试使用WITH ('parallelism' = 'N')语法来指定并行度。然而,这种设置可能会被Flink的优化器覆盖,因为它会根据整个作业的拓扑结构和资源分配来决定最佳的并行度。
使用Table API或DataStream API:
如果你使用Flink的Table API或DataStream API,可以在注册source表或创建source时显式地设置并行度。例如: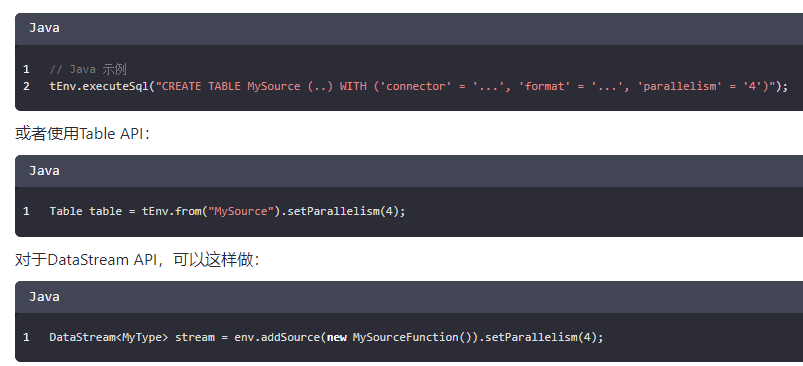
然后,你可以将DataStream转换为Table,并使用Flink SQL进行查询。
使用Flink SQL的资源提示:
你可以在Flink SQL查询中使用/+ OPTIONS('parallelism'='N') /这样的资源提示来尝试控制并行度。但是,这种提示同样可能被优化器忽略,取决于查询计划的全局最优性。
然而,最推荐的做法是在使用Table API或DataStream API时显式地设置并行度,这是因为这种方式更加直接并且可以更精确地控制source的并行度。
请注意,设置并行度时需要考虑集群资源的限制和数据源的特性,以确保最佳的性能和资源利用率。如果数据源本身支持并行读取,则较高的并行度可能带来更好的吞吐量;但如果数据源不支持并行读取,或者数据集较小,那么过高的并行度可能会导致资源浪费和调度开销增加。
在 Apache Flink 中,可以通过 parallelism 属性来为特定的 Source 设置并行度。在 Flink SQL 中,你可以使用 SET 语句来局部地调整并行度。但是在 Flink SQL 环境中,更常用的方式是在定义 Source 或 Sink 时直接通过 WITH 子句指定并行度。对于 Kafka Source,你可以在创建表的时候直接设置并行度,如下所示: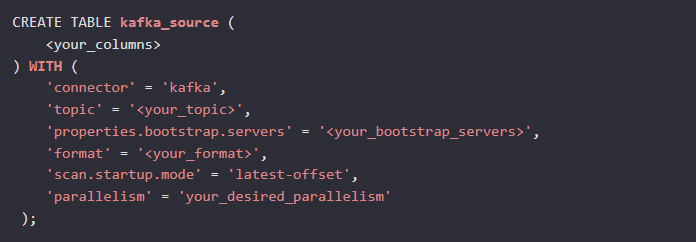
这里的 'parallelism' = 'your_desired_parallelism' 就是用于设置 Kafka Source 的并行度。需要注意的是,Kafka Source 的并行度最好能够与你的 Kafka Topic 的分区数相匹配或为分区数的倍数,以充分利用并行处理能力。如果在创建表时不希望指定并行度,也可以在提交作业前使用 setParallelism 方法来动态调整 Source 的并行度:
此方法需要在 TableEnvironment 或 StreamExecutionEnvironment 的配置级别上进行,并非直接针对某个 Source 表。因此如果你有多个 Source,这可能会影响所有 Source 的并行度
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。