
在Flink为什么报了连接错误 ,还能读取数据呢?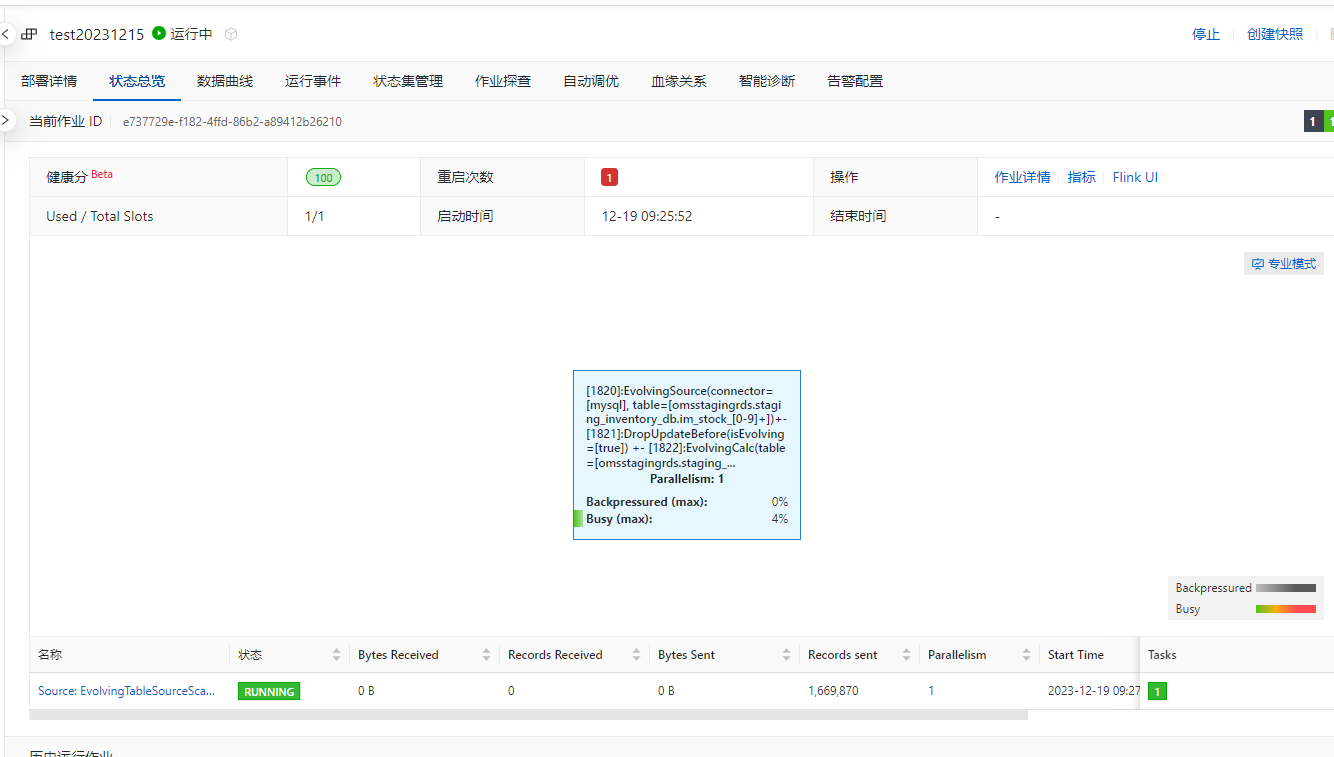

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Apache Flink 中,如果报了连接错误但依然能够读取数据,可能是因为故障恢复机制,如果 Flink 集群配置了 checkpoint 或 savepoint 机制,并且作业在发生连接错误后能自动或手动进行恢复,则即使原始连接断开,Flink 也可以从最近的检查点重新建立连接并继续处理数据。这是因为 checkpoint 包含了所有必要的状态信息和进度位置,使得作业可以从断开点重新开始。也可能是因为容错机制,在某些场景下,如使用 Kafka、HDFS 等作为数据源时,Flink 可能通过内部容错机制来处理暂时性的连接问题。例如,在从 Kafka 读取数据时,即便短暂地无法连接到某个分区,只要 Kafka 服务恢复可用,Flink 仍可以从上一次读取的位置继续读取。也可能是因为重试策略,Flink 的数据源连接通常会设置一定的重试策略,当遇到临时性连接错误时,它会尝试重新连接直到成功。在这个过程中,虽然报告了连接错误,但在后续的重试中可能已经成功建立了连接并开始读取数据。
在Flink中,报告连接错误并且仍然能够读取数据的情况可能是由于Flink的故障恢复机制所导致的。Flink在执行数据处理任务时,会自动进行故障恢复,以确保任务的可靠性和数据的完整性。当Flink在读取数据时遇到连接错误,通常会进行自动的重试和故障恢复。Flink会尝试重新建立连接并继续读取数据,直到达到指定的重试次数或达到失败次数的上限。这样做的目的是为了尽量避免因连接问题导致的数据丢失或任务失败。Flink可能能够通过重试和故障恢复机制读取部分数据。
Flink 读取数据时可能使用了缓存机制。当 Flink 遇到连接错误时,它可能会从缓存中读取数据,因此用户仍然可以获取到数据。
Flink 配置了容错机制。即使连接出现错误,Flink 也能够从其他可用的源或备用节点中读取数据,确保数据的完整性和可用性。
Flink报连接错误可能有以下原因:
网络问题:Flink任务无法连接到目标系统或服务,可能是由于网络故障、防火墙设置、IP地址或端口配置错误等原因。
资源不足:如果Flink集群资源不足,例如内存或CPU资源不足,可能会导致任务失败。
版本不兼容:Flink与所使用的库或依赖项版本不兼容,也可能导致连接问题。
配置错误:Flink任务的配置参数可能设置错误或不完整,导致无法正确连接到目标系统或服务。
依赖问题:Flink任务可能依赖于某些外部系统或服务,而这些服务可能不可用或者有访问限制。
代码错误:Flink任务的代码中可能存在错误,导致无法正确处理输入数据或与外部系统进行通信。
Flink 报了连接错误但仍然可以读取数据,可能有以下原因:
错误信息可能只是关于连接问题,而不是关于数据读取问题。也就是说,连接错误可能是由于网络问题、端口问题或其他相关问题导致的,但并不影响数据读取。
Flink 读取数据时可能使用了缓存机制。当 Flink 遇到连接错误时,它可能会从缓存中读取数据,因此用户仍然可以获取到数据。
Flink 配置了容错机制。即使连接出现错误,Flink 也能够从其他可用的源或备用节点中读取数据,确保数据的完整性和可用性。
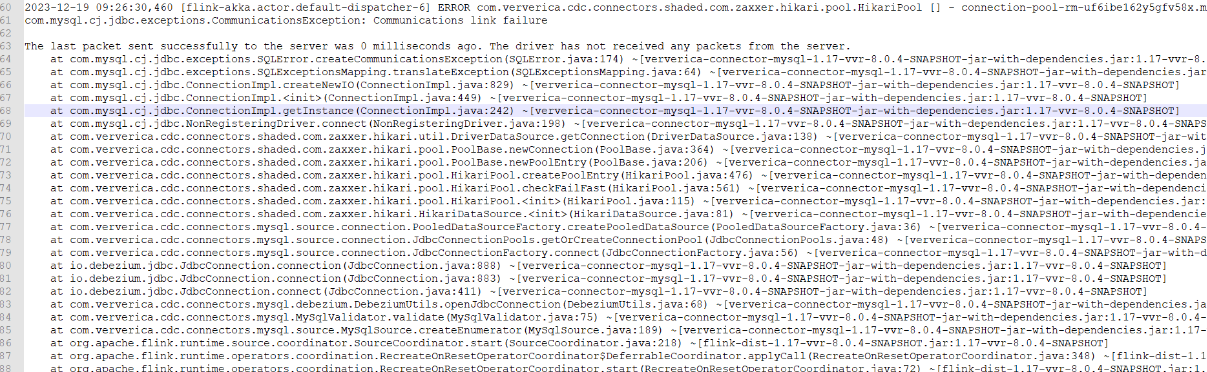
楼主你好,看了你的报错信息,这是一个关于阿里云Flink和MySQL连接的错误,错误提示中提到最后一个数据包成功发送到服务器,但驱动程序没有从服务器接收到任何数据包。
虽然出现连接错误,但你仍然能够读取数据的原因可能是,在错误发生之前,已经成功建立了数据库连接并读取了一部分数据,但是,由于连接错误,后续的数据读取操作可能会失败。要修复这个问题,你可以检查数据库的连接配置是否正确,确保你提供的数据库连接字符串、用户名和密码是正确的。
还有就是检查数据库服务器是否正常运行,确认MySQL服务器正在运行,并且可以从其他客户端成功连接和读取数据。
检查上游存储和Flink全托管之间网络是否连通,查看源表Taskmanager.log日志中是否有异常信息,在当前页面查找最后一个Caused by信息,即第一个Failover中的Cause by信息,往往是导致作业异常的根因,根据该根因的提示信息,可以快速定位作业异常的原因。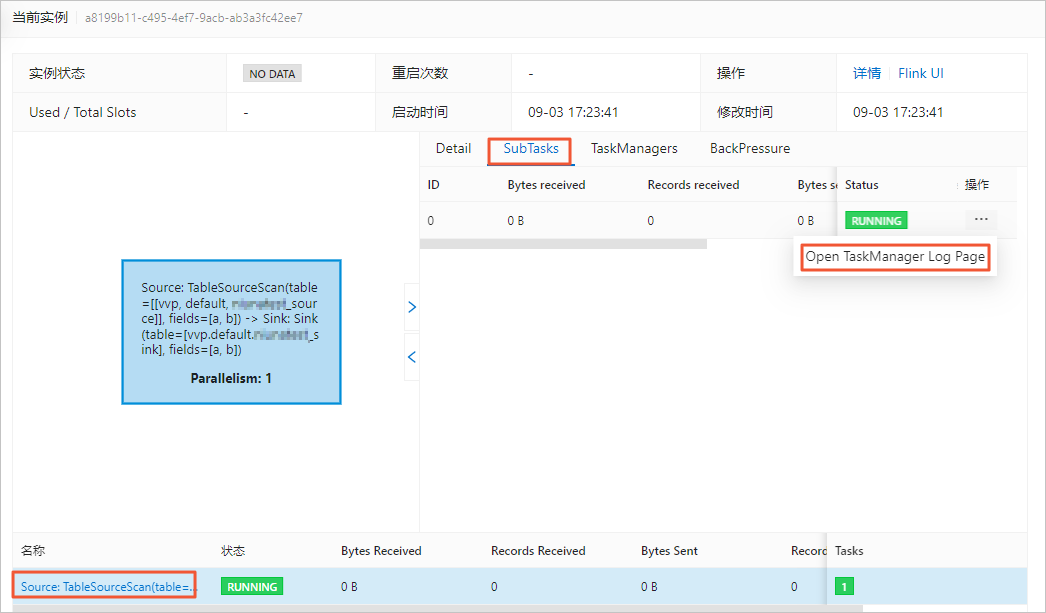
Flink在报告连接错误的情况下仍能读取数据,可能是由于各种原因。首先,可能的是Flink任务的并行度设置不正确,可能会导致重复读取数据。其次,可能是CDC Offset配置错误,Flink CDC使用offset来追踪读取的变更数据,如果offset配置不正确,可能会导致重复读取数据。另外,数据源配置错误也可能导致无法正确读取数据,从而导致重复读取或无法读取数据。此外,检查数据源和数据目标的配置是否正确也是排查问题的重要步骤。
请确保你的 offset 配置准确,并行度设置合理,并且数据源以及数据目标(例如数据库、消息队列等)的配置正确,并且可以正常访问和读写数据。同时,查看Flink程序的日志文件,包括TaskManager和JobManager的日志,以查找任何相关的错误或警告信息。日志中可能会提供有关连接器、网络通信或其他潜在问题的线索。
在Flink中,即使报了连接错误,仍然能够读取数据,这是因为Flink具备一定的容错和异常处理能力。当出现连接错误时,Flink会尝试重新连接或自动故障转移,从而确保数据处理不受影响。以下是一些可能的原因和解决方案:
连接错误可能是由网络问题、服务器宕机或配置错误导致的。在这种情况下,Flink会尝试重新连接或自动故障转移至其他可用的数据源。
如果连接错误是由于网络问题导致的,可以检查网络连接并确保数据源的服务器地址和端口正确。同时,检查Flink作业的资源限制,确保分配了足够的内存和CPU资源。
确保Flink作业的配置正确,例如,对于Kafka连接,需要正确设置bootstrap.servers、key.deserializer、value.deserializer等参数。
检查数据源的兼容性。例如,对于Kafka数据源,确保Flink版本与Kafka客户端版本兼容。此外,确保Flink作业使用的Kafka版本与数据源使用的Kafka版本兼容。
检查Flink作业的启动模式。确保作业以正确的启动模式运行,例如,对于增量快照读取,可以使用“start-instance”模式。
检查数据类型映射。确保Flink作业中的数据类型与数据源中的数据类型匹配。
总之,Flink在出现连接错误时仍然可以读取数据,但建议检查上述原因以确保作业的正常运行。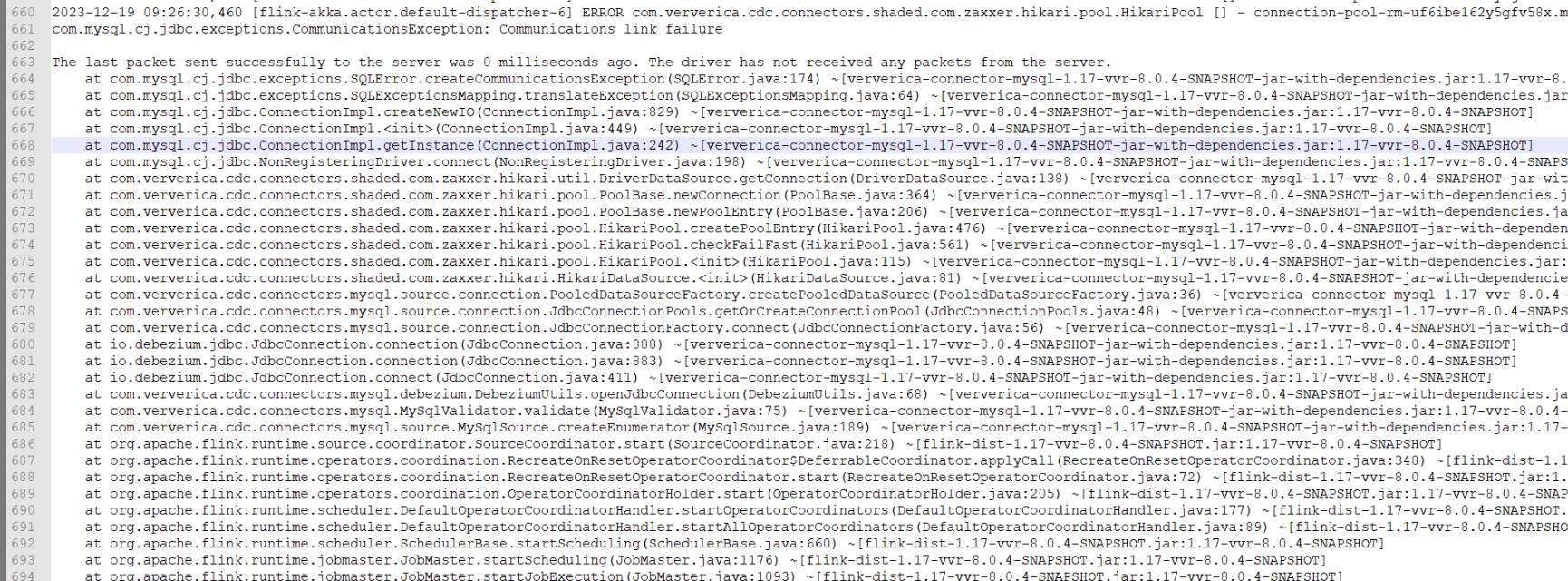
Flink报连接错误,但仍然可以读取数据,可能有以下原因: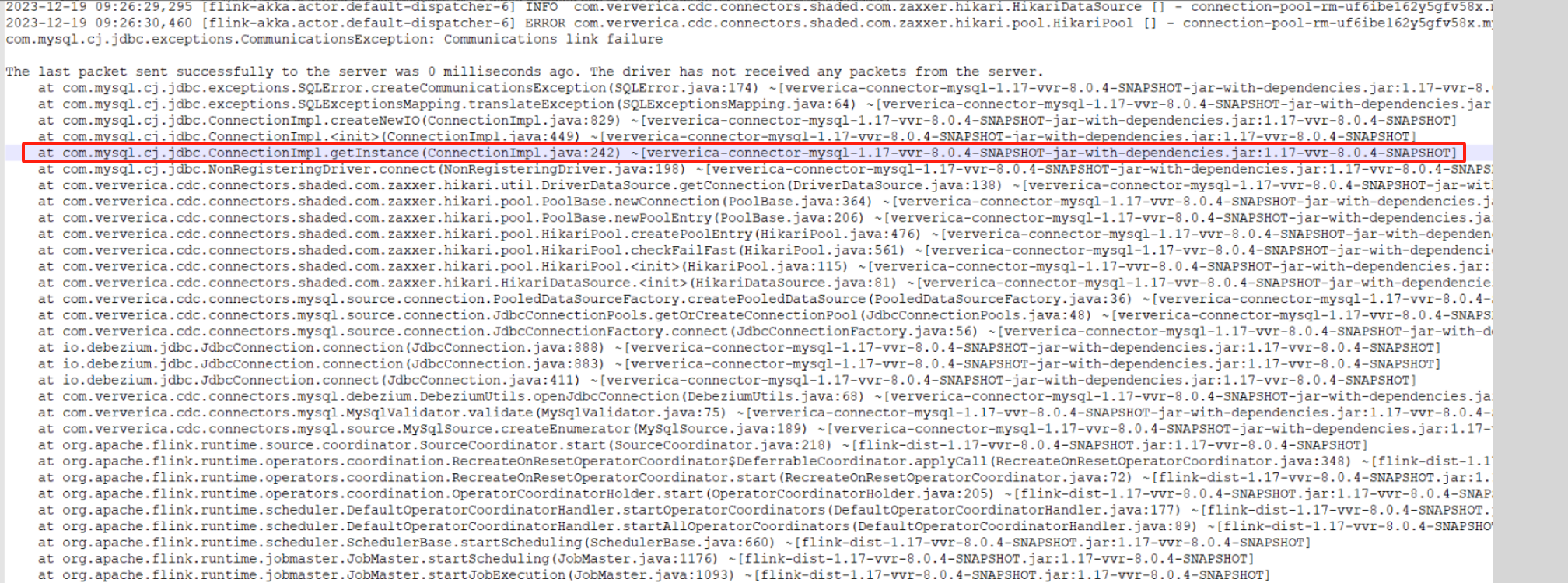
根据你提供的图示,更多是可能因为数据库通信链接失败导致的错误,需要检查连通性。而Flink本身在连接错误下,是可以继续读取数据的,所以这是正常的。另外,如果经常遇到以下常见问题,可对应解决下,比如:
1.异常处理:Flink在处理数据流时,会将数据划分为多个小的分区,并在不同的任务并行处理这些分区。当某个任务出现连接错误时,Flink可以自动将该任务重新分配给其他可用的任务,从而继续处理数据。
2.数据缓存:Flink在处理数据时会缓存一部分数据,因此即使某个连接出现错误,Flink仍然可以从缓存中读取数据。
3.数据容错:Flink具有数据容错机制,即使某个节点或连接出现故障,Flink也可以通过复制数据到其他节点或使用备用连接来保证数据的可靠性和一致性。!
我常用的处理方法
1.异常捕获和处理:用Try-Catch块来捕获和处理异常,并选择记录异常信息、发送警报。
2.任务重启机制:如果任务出现异常,Flink具有自动重启机制,可以自动重新启动任务。重启策略可以选择固定时间间隔重启或失败率重启等。通过增加重启策略,可以在程序遇到错误时在不被kill的状况下重新启动。
3.数据容错:可以通过数据复制或使用备用连接来保证数据的可靠性和一致性。即使某个节点或连接出现故障,也可以从其他节点或备用连接中获取数据,保证程序的正常运行。
总的来说,Flink的异常处理机制包括异常捕获和处理、任务重启机制和数据容错等,这些机制可以保证程序的稳定性和可靠性,提高程序的性能和可用性左一是
根据提供的信息,Flink在连接MySQL数据库时出现了通信链接失败的错误。这可能是由于网络问题、防火墙设置或数据库配置等原因导致的。尽管Flink报告了连接错误,但它仍然可以读取数据,这意味着Flink在内部处理了连接失败的情况。
要解决这个问题,你可以尝试以下方法:
检查网络连接:确保你的应用程序和数据库服务器之间的网络连接正常。你可以使用ping命令测试网络连通性。
检查防火墙设置:确保防火墙允许应用程序与数据库服务器之间的通信。你可以查看防火墙规则并添加相应的端口开放规则。
检查数据库配置:确保数据库服务器的配置正确,并且允许来自应用程序的连接。你可以检查数据库的监听地址、端口号和其他相关设置。
检查数据库驱动程序版本:确保你使用的Flink连接器(如ververica-connector-mysql)与你的数据库版本兼容。如果需要,你可以升级或降级驱动程序版本以解决兼容性问题。
检查日志文件:查看Flink和数据库服务器的日志文件,以获取更多关于连接失败原因的详细信息。这可以帮助你诊断问题并找到解决方案。
虽然出现了Communications link failure的异常,但根据日志信息可以看出,在这个时间点之前(2023-12-19 09:26:25),Flink已经成功地从数据库中获取了一些数据。可能是因为当出现通信链接失败时,某些操作仍然可以继续执行,所以后续还是会有数据。
一般来说当出现通信链接失败时以下操作还可以继续进行:
数据查询:如果你正在运行一个SQL查询或类似的数据访问任务,那么即使与数据库之间的直接通信中断,你也可以尝试使用缓存或其他本地存储机制来检索所需的信息。
状态管理:对于流式计算框架如Apache Flink中回答已停止生成的状态管理系统来说,它们通常会将一些中间结果保存到磁盘或者其他持久化存储设备中。因此,即使在网络不稳定或者断开的情况下,这些已保存的结果依然可用。
异步调用:有些异步请求并不会立即返回响应,而是会在稍后的时间内完成。在这种情况下,即使当前无法建立有效的通信链路,后续的操作也有可能正常进行。
定期同步:许多分布式系统都依赖于定期同步进程来保持一致性。例如,主备复制中的备份节点可能会接收到关于更改的通知并在适当的时候应用这些更改。
如遇到“Communication link failure”这类严重的通信问题,应尽快排查其根本原因并采取相应的措施修复。建议检查网络配置、数据库服务器状态以及应用程序代码以确定原因。
如果报了连接错误,仍然可以读取数据,可能有以下原因:
在Flink中,当连接错误发生时,仍然可以读取数据的原因可能有以下几种:
容错机制:Flink具有强大的容错机制,即使在连接错误的情况下,它也可以从上一个检查点或保存点恢复数据流,从而继续读取数据。这意味着即使某个节点与集群失去了连接,Flink也可以从其他节点继续处理数据。
重新建立连接:Flink会自动尝试重新建立与丢失连接的节点的连接。在连接重新建立之前,Flink会继续从其他节点读取数据。
数据备份:如果Flink读取数据时遇到连接错误,它可以从备份数据源中读取数据。备份数据源可以是另一个Kafka集群、HDFS或其他存储系统。
动态调整并行度:Flink可以根据需要动态调整并行度,以确保数据能够从不同的节点读取并处理。
需要注意的是,虽然Flink能够在连接错误时继续读取数据,但长期或频繁的连接错误可能会影响Flink作业的性能和稳定性。因此,对于持续出现的连接错误,需要进行深入排查并解决根本问题。
虽然出现了数据库连接失败的异常,但是程序仍然能够继续运行并尝试从其他可用的数据源中获取数据。这可能是因为 Flink 的任务调度和容错机制允许它在遇到某些故障时自动恢复,并且重新执行丢失的任务。
在这种情况下,即使发生了通信链接失效(Communications link failure)这样的严重问题,Flink 可能会切换到备用的数据库连接或者使用缓存中的数据来完成计算。然而,在这种模式下,性能可能会受到影响,因为需要额外的时间来处理这些替代方案或重试操作。
尽管出现了一些连接错误,但 Flink 程序仍有可能成功地读取所需的数据,这是因为它的设计使其能够在面对各种挑战时保持弹性。如果此类问题频繁发生,则应检查配置、网络设置或其他相关因素以确保系统的稳定性和可靠性。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



