
flink 消费kafka,之前任务正常的,突然有个分区没法消费了,重启下任务久正常了?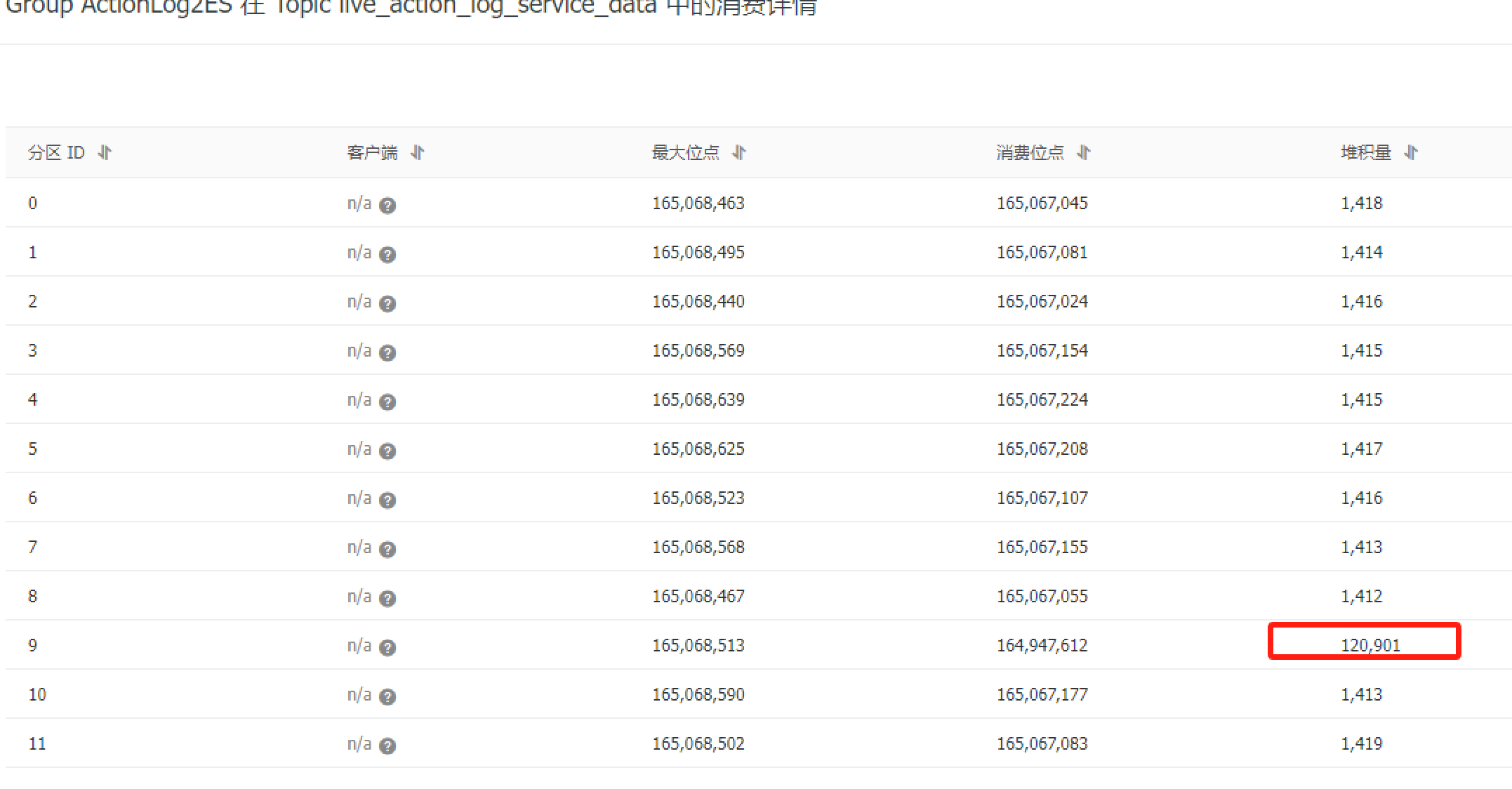
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Apache Flink 中消费 Kafka 的数据流时,如果任务之前运行正常,但突然有一个分区停止了消费,重启任务后又恢复正常,这可能是由于网络中断或不稳定可能导致与 Kafka 集群的连接暂时断开,进而影响到 Flink 从特定分区读取数据。短暂重启 Flink 任务可能会重新建立网络连接。如果 Flink 任务作为 Kafka 消费者组的一部分,在与 Group Coordinator 的通信中出现异常,比如 Coordinator 节点故障、心跳超时等,可能造成消费者无法正确地获取分区分配或者提交 offset。重启任务有助于重新参与组协调和分区分配过程。在 Flink 的内部状态管理中,如 Checkpoint 或 Offset State 存储出现问题,导致某个分区的状态无法正确更新或恢复。重启任务后,Flink 会基于最新的 Checkpoint 或 Kafka 中的当前偏移量重新开始消费。遇到此类问题时,建议楼主查看 Flink 和 Kafka 的日志以获取更详细的错误信息,并结合配置检查和监控数据来定位具体的问题根源。
当Flink任务消费Kafka时,如果出现某个分区突然无法消费的问题,而重启任务后恢复正常,这可能是因为Kafka的消费者位移管理中可能存在不一致。在某些情况下,Flink内部维护的分区offset可能由于某种原因没有正确更新或持久化到checkpoint中,导致consumer从错误的位置开始读取数据。重启任务时,Flink会重新拉取最新的checkpoint或者从Kafka自动重置偏移量,从而恢复正常的消费。也可能是网络连接故障可能导致与Kafka broker的通信中断,使得Flink任务暂时无法访问某个分区的数据。一旦网络恢复正常或重启任务重新建立连接,该分区的数据就可以继续被消费。
也有可能是因为 Kafka partition的leader发生变更时,Flink consumer如果没有及时感知并切换到新的leader上,也可能造成消费停滞。重启Flink任务时,它会重新发现分区的leader并建立连接。要彻底排查这个问题,可以查看Flink的日志以获取具体的错误信息,并结合Kafka集群的监控指标来定位问题所在。
楼主你好,在阿里云Flink中消费Kafka时,如果突然有一个分区无法消费,但其他分区正常消费的情况下,重新启动任务可能会解决问题。
个人觉得是Kafka分区负载不均衡,可能是由于某个分区的消费者处理速度较慢,导致该分区堆积了过多的未消费消息,使得消费者无法正常消费,你可以尝试为该分区增加更多的消费者实例,以提高处理速度。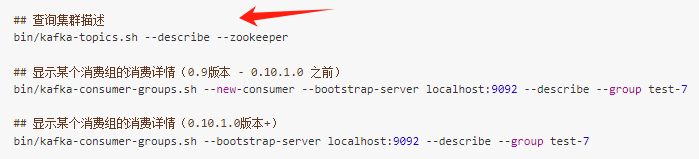
还有就是Kafka分区发生了变化,可能是由于Kafka集群发生了分区的重新分配或者扩容操作,导致某些分区的元数据信息发生了变化,消费者无法正确地获取最新的分区信息。
检查一下kafka broker的状态,以及任务配置是否正确,不使用代理或端口映射等转发机制,直接打通Flink与Kafka之间的网络,使Flink能够直接连通Kafka元信息中显示的Endpoint。联系Kafka运维人员,将转发地址作为Kafka Broker端的advertised.listeners,以使Kafka客户端拉取的Kafka服务端元信息包含转发地址。
如果是由于Flink内部的offset管理出现问题,比如offset未能正确提交或更新,那么重启任务会从上次提交的offset开始重新消费,这可能导致之前未被处理的数据得以正常消费。
1、查看下kafka集群是否有异常日志。
2、用以下命令查看下对应的状态。
## 查询集群描述
bin/kafka-topics.sh --describe --zookeeper
## 显示某个消费组的消费详情(0.9版本 - 0.10.1.0 之前)
bin/kafka-consumer-groups.sh --new-consumer --bootstrap-server localhost:9092 --describe --group test-7
## 显示某个消费组的消费详情(0.10.1.0版本+)
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test-7
——参考链接。
Flink消费Kafka分区无法消费的问题可能有多种原因。首先,您需要确保Flink任务的消费者组设置没有重复,因为Kafka每个分区只允许同一个消费组内的一个消费者消费。其次,检查主机host是否已配置,以及Kafka消费组的状态。为了查看消费组的状态,您可以使用如下运维命令:./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group dw_test_kafka_consumer_000 --describe。
如果上述方法都无法解决问题,您可以考虑重启Flink任务。在某些情况下,任务可能会出现数据积压的现象,每日在积压告警后重启,重启之后消费能力恢复正常,问题得到缓解。但这种方法只是临时解决方案,长期来看,还需要进一步排查和解决问题的根本原因。
根据您提供的日志和截图来看,问题可能是由于Kafka主题中的某些分区出现了延迟或者不可达的情况,从而导致Flink无法从这些分区获取消息来完成其作业的任务分配。 当出现这种情况的时候,通常有两种应对策略:
等待: 当遇到分区不可达或延迟的问题时,可以选择等待一段时间再试一次。如果只是短暂的故障恢复后即可恢复正常,则选择等待是最直接且有效的办法之一。但是需要注意的是,如果长时间存在此类问题则可能导致整体性能下降甚至影响业务稳定性。
手动干预: 可能通过增加消费者组成员数、调整消费者的配置等方式提高容忍度,比如设置更长的心跳间隔等。另外也可以考虑切换至其他可用的主题分区继续执行作业。但请注意,任何操作都应谨慎对待以免造成不必要的损失。
对于您的情况来说,可以先检查一下是否有网络异常或其他外部因素干扰了Kafka服务的稳定性和可靠性;其次查看是否有可能是生产者端有大量积压的消息而导致的暂时阻塞现象。如果是后者的话,可以根据实际情况适当优化生产者的吞吐量与频率,避免产生过多堆积。
根据您提供的日志截图来看,您的 Flink 任务似乎无法正常消费某个特定分区内的一些记录。当一个分区长时间未能被消费时,确实会出现您提到的现象——重启任务后恢复正常的行为。以下是几点建议帮助您解决问题:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


