
"PolarDB-X中 我的K8S集群中有一台机器因为断电重启了 重启后看到该节点上所有组件都异常无法正常工作,这种应该怎么去排障恢复呢?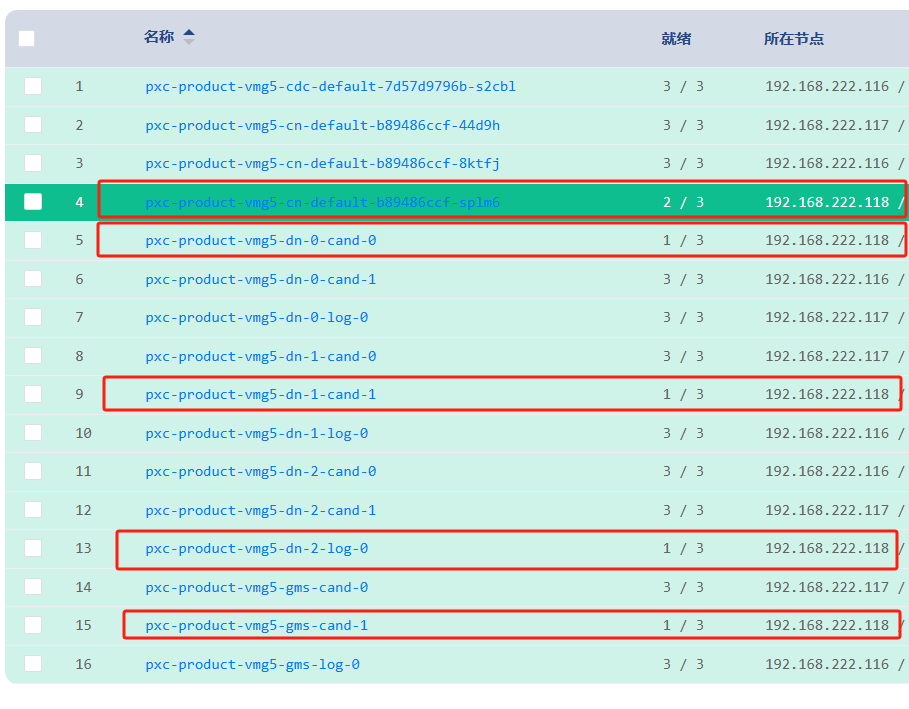
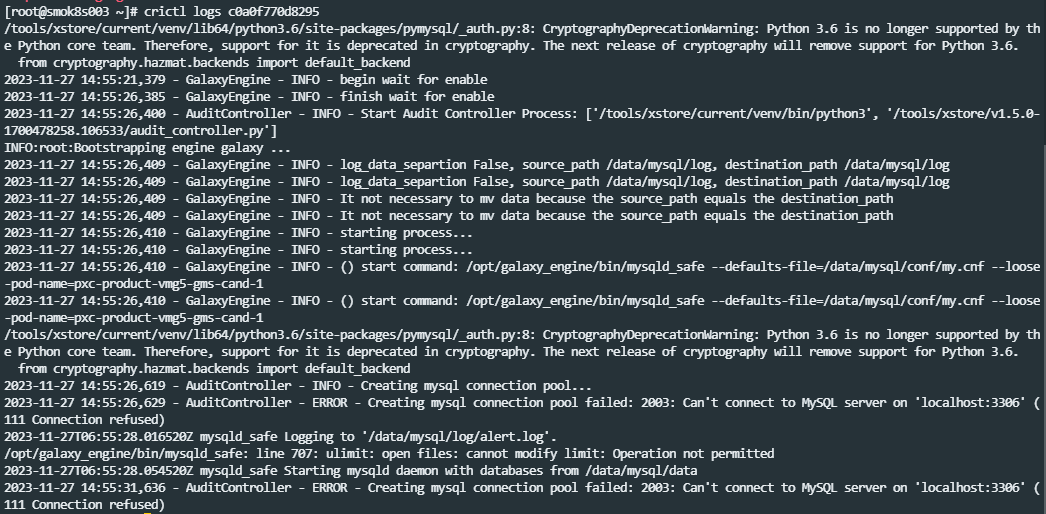
大多都是这种可用性的告警,集群也是无法工作的。 "
"
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果K8S集群中的一台机器因为断电重启后,发现该节点上所有组件都异常无法正常工作,可以尝试以下步骤进行排障恢复:
当您的Kubernetes集群中的某台机器因为断电重启后,发现该节点上的所有组件都无法正常工作时,可以按照以下步骤进行排障和恢复:
检查节点状态:使用命令 kubectl get nodes 确认节点是否处于Ready状态。如果节点状态为NotReady,可能是由于网络或其他问题导致。
检查Pod状态:使用命令 kubectl get pods --all-namespaces 检查集群中所有Namespace的Pod状态。关注那些被调度到问题节点上且状态异常的Pod。
查看节点日志:使用命令 kubectl describe node <节点名称> 获取节点的详细信息,检查是否有任何错误或异常提示。
重启故障容器:如果仅部分组件无法正常工作,您可以尝试通过删除相关Pod来触发它们的重新调度。例如,使用命令 kubectl delete pod <Pod名称> -n <Namespace> 删除异常的Pod。
调查服务配置:检查您在该节点上运行的服务的配置是否正确,并确保依赖的资源(如存储卷、网络等)可用。
检查网络连接:确保该节点与其他节点和外部网络通信正常。检查防火墙设置、网络配置、DNS解析等。
检查节点资源:确认该节点上的CPU、内存、磁盘等资源是否足够支持运行的组件。如果资源不足,可能导致组件无法正常启动。
检查依赖服务:如果组件依赖其他外部服务(例如数据库、消息队列等),确保这些服务也已经恢复并可用。
考虑节点重建:如果以上排障步骤无法解决问题,您可以考虑将该节点从集群中删除,并重新添加一个新的节点。
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


