
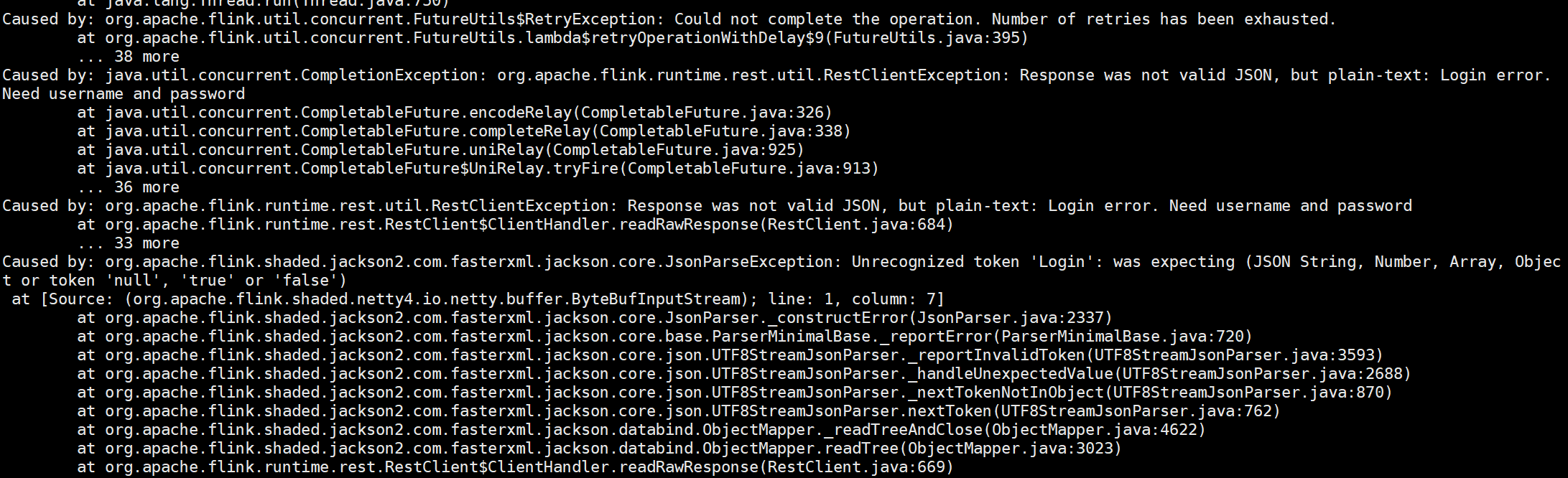
flink读取hive表数据(catalog形式)。怎么转换为会报错?启动命令是yarn-per-job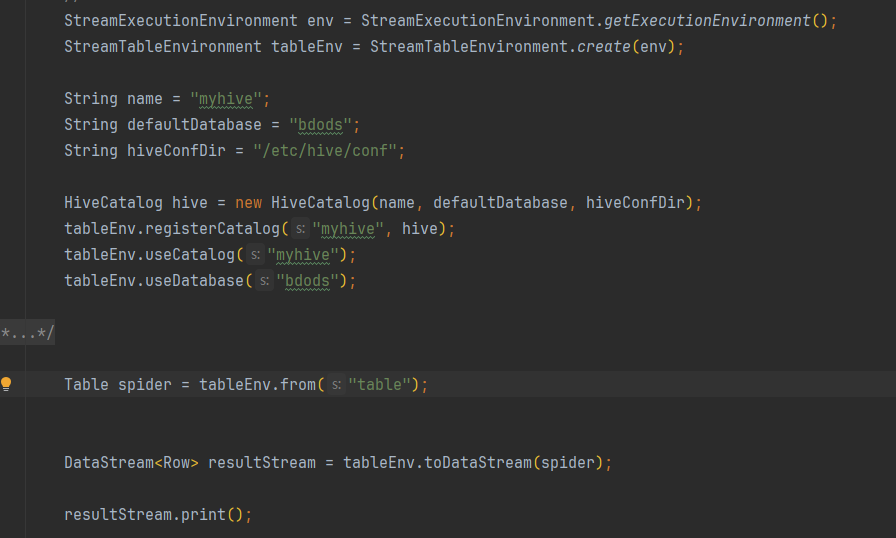
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink 1.11 中,使用 yarn-per-job 模式运行读取 Hive 表数据的任务时可能会遇到一些问题。主要原因是 yarn-per-job 模式的执行方式与 Flink on YARN(cluster 模式)不同,YARN per job 模式实际上是一个独立的进程,无法像 Flink cluster 模式那样直接连接到 Hadoop 集群上的 Hive Metastore。
解决方法如下:
尝试将 Flink 的模式更改为 standalone 或者 cluster 模式。在这种模式下,Flink 可以直接连接到 Hive Metastore 并获取表结构信息。
如果必须要使用 yarn-per-job 模式,则需要单独启动 Hive Metastore 服务,并将其配置到 Flink 作业中。具体步骤如下:
a. 在 YARN 集群上启动 Hive Metastore 服务。
b. 在 Flink conf 中添加 hive.metastore.uris 参数,指向启动的 Hive Metastore 服务地址。
c. 在代码中使用 catalog 方式读取 Hive 表。
请参考以下示例:
// 获取 Hive Catalog 实例
HiveCatalog hiveCatalog = new HiveCatalog(hiveMetastoreURI, "default");
// 创建 TableEnvironment 并注册 Hive Catalog
TableEnvironment tableEnv = ...;
tableEnv.registerCatalog("my_hive_catalog", hiveCatalog);
tableEnv.useCatalog("my_hive_catalog");
// 使用已注册的 Hive 表名
Table hiveTable = tableEnv.from("my_hive_table");
这里假设 Hive Metastore 地址为 $hiveMetastoreURI$,默认数据库名为 default。
Flink读取Hive表数据(catalog形式)时,如果遇到错误,可以尝试以下方法解决:
hive --service metastore
flink-conf.yaml中,添加以下配置:env.java.opts: "-Dlog4j.configuration=file:/path/to/your/log4j.properties"
将/path/to/your/log4j.properties替换为实际的log4j配置文件路径。
flink-conf.yaml中,添加以下配置:table.execution.arrow.enabled: false
table.execution.arrow.max-records-per-batch: 1000
table.execution.arrow.max-memory-consumed-per-batch: 100M
这些配置用于控制Arrow格式的数据读写性能。
yarn-session模式运行Flink作业,而不是yarn-per-job模式。在启动Flink作业时,使用以下命令:./bin/flink run -m yarn-session /path/to/your/flink-job.jar
将/path/to/your/flink-job.jar替换为实际的Flink作业JAR文件路径。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


