
Flink经过测试发现使用 事务传播机制 无论是那种事务传播机制 都不行,如果都成功还好,有一个失败后面的都会失败
REQUIRES_NEW 新建事物,如果当前已经存在事物,则挂起当前事物
NESTED 如果当前存在事物,则在嵌套事物内执行;如果当前没有事物,则与PROPAGATION_REQUIRED传播特性相同?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink 是一个分布式流处理框架,它提供了高性能、低延迟的流处理能力。在 Flink 中,事务传播机制用于确保数据的一致性和可靠性。但是,如果在测试中发现使用事务传播机制会导致失败,可能有以下几个原因:
数据源问题:事务传播机制需要与数据源进行协调,如果数据源存在问题,可能会导致事务失败。检查数据源的可用性和可靠性,确保它们能够正确地支持事务传播机制。
网络问题:Flink 的分布式特性需要节点之间的通信,如果网络存在问题,可能会导致数据不一致或事务失败。检查网络连接的稳定性和可靠性,确保节点之间的通信畅通。
并发问题:Flink 是一个高并发的系统,如果并发量过高,可能会导致资源竞争和死锁等问题,进而导致事务失败。调整 Flink 的并行度和并发度,以适应实际工作负载的需求。
事务冲突:如果多个事务同时对同一数据进行操作,可能会导致事务冲突,进而导致事务失败。在这种情况下,需要设计适当的事务协调机制来避免冲突。
总之,要解决 Flink 中使用事务传播机制导致失败的问题,需要仔细检查数据源、网络、并发和事务冲突等方面的问题。根据实际情况选择合适的事务传播机制和配置参数,并参考 Flink 社区的文档和资源来解决问题。
Flink 中的事务传播机制遵循了传统的关系型数据库事务传播语义。根据您的描述,Flink 使用事务传播机制时遇到了问题,特别是在其中一个事务失败后导致后续操作都失败的情况。
对于您提到的事务传播特性,我会对每一种特性进行一些说明:
PROPAGATION_REQUIRES_NEW(新建事务):该特性会创建一个新的事务,如果当前存在事务,则会将当前事务挂起。这样,即使其中一个事务失败,也不会影响其他事务的执行。这是一种独立的事务执行方式。
PROPAGATION_NESTED(嵌套事务):根据您描述的行为,Flink 中的嵌套事务行为与 PROPAGATION_REQUIRED(必须有事务)特性相似。这意味着如果当前环境下已经存在事务,则在嵌套事务内执行;如果当前没有事务,则会创建一个新的事务执行。当嵌套事务失败时,它会回滚嵌套事务内的所有操作,但不会回滚外层事务。这种行为可以确保嵌套事务的一致性,但仍然可能会影响其他操作。
需要注意,Flink 中的事务并非完全等同于传统的关系型数据库事务。在 Flink 的流处理场景中,事务是通过状态和检查点来实现的。当事务失败或触发回滚时,Flink 会回滚到最近的检查点,并且可能会触发 Flink 的重启机制,重新执行失败的操作。如果事务在失败前已经提交,则无法回滚。
您遇到的情况可能取决于具体的代码逻辑和使用的 Flink 版本。如果您能提供更多的信息,例如:具体的代码示例、Flink 版本和日志信息,那将有助于更好地理解和解决您遇到的问题。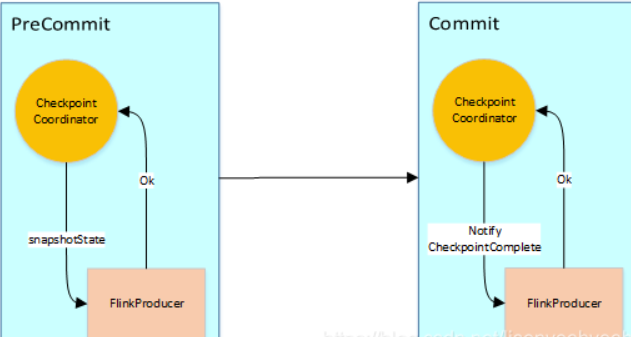
Flink Sink事物过程执行两阶段提交,其流程图大致如下: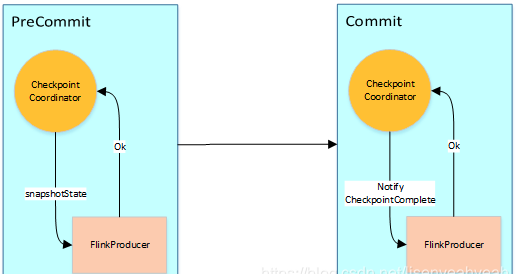
1、JobManager向Source发送Barrier,开始进入pre-Commit阶段,当只有内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些已定义的状态变量即可。当chckpoint成功时Flink负责提交这些写入,否则就终止取消掉它们。
2、当Source收到Barrier后,将自身的状态进行保存,后端可以根据配置进行选择,这里的状态是指消费的每个分区对应的offset。然后将Barrier发送给下一个Operator。
3、当Window这个Operator收到Barrier之后,对自己的状态进行保存,这里的状态是指聚合的结果(sum或count的结果),然后将Barrier发送给Sink。Sink收到后也对自己的状态进行保存,之后会进行一次预提交。
4、预提交成功后,JobManager通知每个Operator,这一轮检查点已经完成,这个时候,Kafka Sink会向Kafka进行真正的事务Commit。
——参考链接。
Flink自身提供了自己的状态一致性保证和容错机制,特别是对于有界或无界数据流处理任务,它使用了checkpoint机制来确保故障恢复时的一致性。
Apache Flink 并不直接支持传统的数据库事务传播机制,例如 Spring Framework 中定义的 REQUIRED、REQUIRES_NEW、NESTED 等。这是因为 Flink 是一种用于处理无界和有界数据流的分布式流处理系统,它的设计目标在于保证 Exactly-Once 处理语义,而不是像传统数据库那样实现 ACID 事务。
在 Flink 中,为了保证状态一致性以及端到端的 Exactly-Once 语义,它提供了自己的容错机制,包括 Checkpointing 和 Two-Phase Commit (2PC) for sinks。对于涉及多个算子的状态更新或者写入外部系统的操作,Flink 使用这些机制来协调一致性和恢复。
当谈到外部系统的事务性交互,例如与数据库交互时,你需要结合 Flink 自身的事务管理与外部系统的事务管理机制来设计解决方案。例如,如果你在 Flink 作业中使用了 JDBC sink 连接数据库,并且希望实现类似 ACID 事务的功能,那么你可能需要利用数据库自身的事务控制,而不能依赖于 Flink 提供的事务传播机制。
对于 Flink 内部的任务,如果需要保证独立任务的原子性,你可以考虑使用 Flink 的 ProcessFunction 或者 KeyedProcessFunction 来手动控制状态更新和异常处理逻辑,结合 Checkpointing 实现一定程度上的“事务”效果。不过,这种“事务”的边界是由 Flink 的 checkpoint 机制来界定的,而非类似于 RDBMS 中的事务传播机制。
Requieas New
当使用 REQUIRES NEW 传播特性的事务管理器时,如果当前上下文不存在有效的事务,将会新建一个事务。如果当前上下文已经有有效事务,那么就会挂起当前事务,进入新的事务中执行。这种方式通常用于那些需要独立事务的新操作,以便防止脏数据的影响。
Nested
NESTED 传播特性意味着在嵌套事务中执行。如果当前上下文中已有事务,那么就在那个事务里执行;如果没有,就像 PROPAGATION_REQUIRED 一样,新开一个事务。这种传播特性主要用于维护外层事务的一致性,特别是当子事务依赖于父事务的存在时。
Propagation Required
PROPIGATION REQUIRED (PR) 表明如果当前上下文中有活动事务,那么就利用现有的事务。如果没有活动事务,那就自己建立一个新的事务。 PR 传播特性是最常用的一种传播特性,因为它允许在大多数情况下都能获得最佳性能。
这三个传播特性在不同的场合有不同的适用性。选择哪个传播特性取决于你的具体需求和设计决策。例如,如果你的应用程序是一个分布式系统的一部分,你可能需要使用 NESTED 特性来保护外部事务不受内部事务失败的影响。另一方面,如果你只需要控制自己的事务而不受外部事务的影响,那么 PROPIGATION REQUIRED 可能更适合你。
Flink 的事务传播机制在某些情况下可能会遇到问题。根据您提供的信息,似乎在某些情况下事务传播失败,导致后续操作失败。让我们分析一下您提到的事务传播机制:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


