文字识别OCR教育类场景我要自己开发的话,应该怎么做呢?
https://help.aliyun.com/document_detail/603346.html?spm=a2c4g.603352.0.0.6dcf7ff5kJDzGz
这个文档是做这个事的吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是的,您提供的文档是阿里云OCR文字识别服务的官方文档,它详细介绍了如何使用阿里云OCR文字识别服务进行开发和使用。
如果您想自己开发OCR文字识别功能,可以按照以下步骤进行:
请注意,OCR文字识别技术目前还存在一些限制和挑战,例如对图片质量、字体、语言等的要求较高,且识别结果可能存在一定的误差。因此,在使用OCR文字识别技术时,您需要根据自己的需求和应用场景进行选择和优化。
楼主你好,是的,这个文档提供了阿里云OCR文字识别API在教育类场景下的调用方法。如果您要自己开发基于阿里云OCR文字识别API的教育类应用,可以参考该文档提供的接口说明和开发实践篇章,按照文档中的步骤进行调用API即可。需要注意的是,在使用API时需要购买相应的产品套餐。
您好,文字识别OCR提供了文档自学习场景,支持用户完成模板配置、数据处理&标注、模型构建&训练、部署发布等操作的一站式工具平台。您可以通过数据训练、标注来提高您在特定场景下的识别准确率,具体的操作步骤,比如自定义KV模板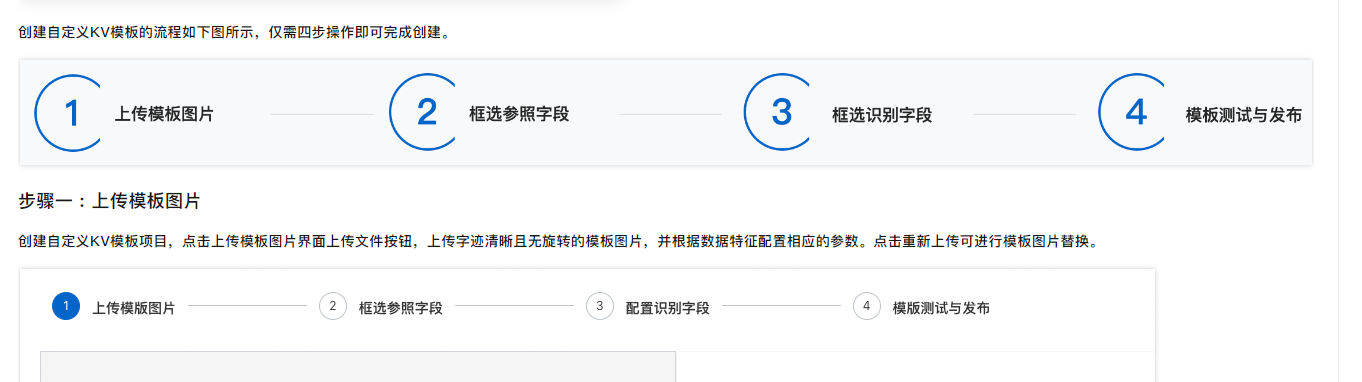
文字识别OCR文档自学习控制台操作步骤如下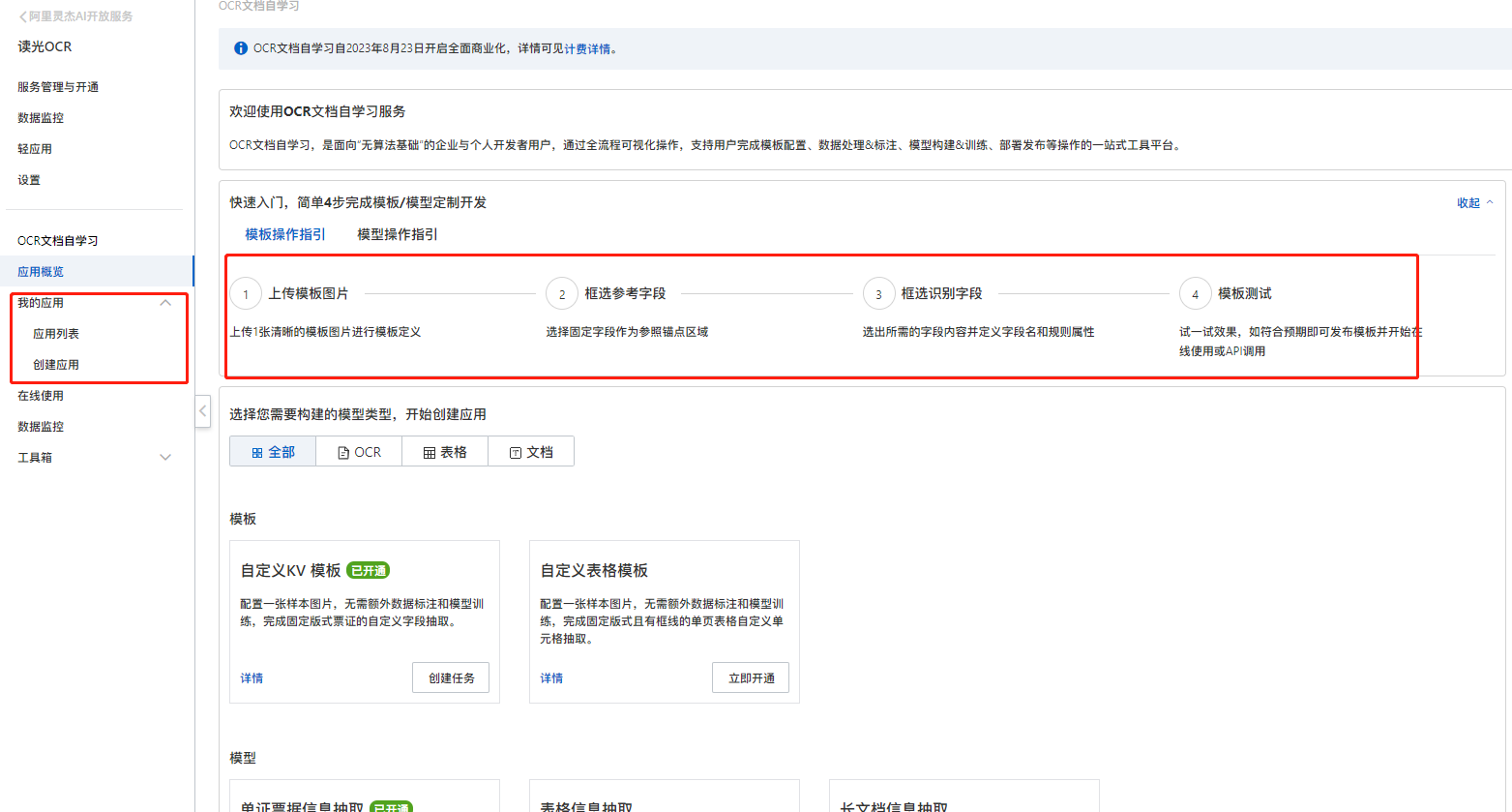
如果您想在教育类场景中自行开发文字识别OCR应用,可以考虑以下步骤:

数据收集:收集适合教育类场景的训练数据。这些数据可以包括学生试卷、教科书、教师讲义等与教育相关的文本图像。确保数据集中包含各种字体、样式和布局的文本图像,以使模型能够适应不同的情况。
标注数据:为收集到的图像数据手动标注正确的文本内容。这将为模型提供训练所需的准确标签。对于教育场景,还可以考虑标注答案和解析等附加信息。
模型训练:使用标注好的数据集进行模型的训练。您可以选择使用现有的OCR模型框架(如Tesseract、OpenCV等)或使用深度学习框架(如TensorFlow、PyTorch等)来构建和训练自定义的OCR模型。训练过程可能需要迭代多次,调整模型参数直至达到满意的性能。
模型评估:使用一部分未参与训练的测试数据评估训练得到的模型性能。这有助于衡量模型的准确度、召回率和其他性能指标。根据评估结果,可以对模型进行调整和优化。
部署应用:将训练好的模型部署到生产环境中,以供教育场景中的文字识别使用。您可以将模型嵌入到自己开发的应用程序中,或者使用OCR服务提供商的API来实现文字识别功能。
持续改进:根据实际应用中的反馈和需求,不断优化和改进您的OCR应用。这可能包括更新训练数据、重新训练模型以适应新的情况,或者引入更高级的技术和算法来提升性能。
教育场景识别

https://help.aliyun.com/document_detail/295343.html?spm=a2c4g.603346.0.0.201037f3rDElso
读光试题作业OCR识别产品能力,主要针对教育应用场景中对试题题目、数学公式、速算题目等信息的智能化识别需求,通过对通用OCR高精度识别能力的教育场景迭代优化,为用户提供数学试题图片中题目文本及数学公式的识别、速算题目文字的检测和识别等服务,并返回题目框位置与内容,为智慧教学场景下的拍照搜题、板书识别、自动阅卷等应用提供关键基石技术能力。可大程度辅助教师的教务工作,并协助教育进行数字化转型。
说明
功能体验地址:https://duguang.aliyun.com/experience?type=edu
开通享免费额度:https://ocr.console.aliyun.com/overview
购买地址:https://common-buy.aliyun.com/?commodityCode=ocr_education_dp_cn#/buy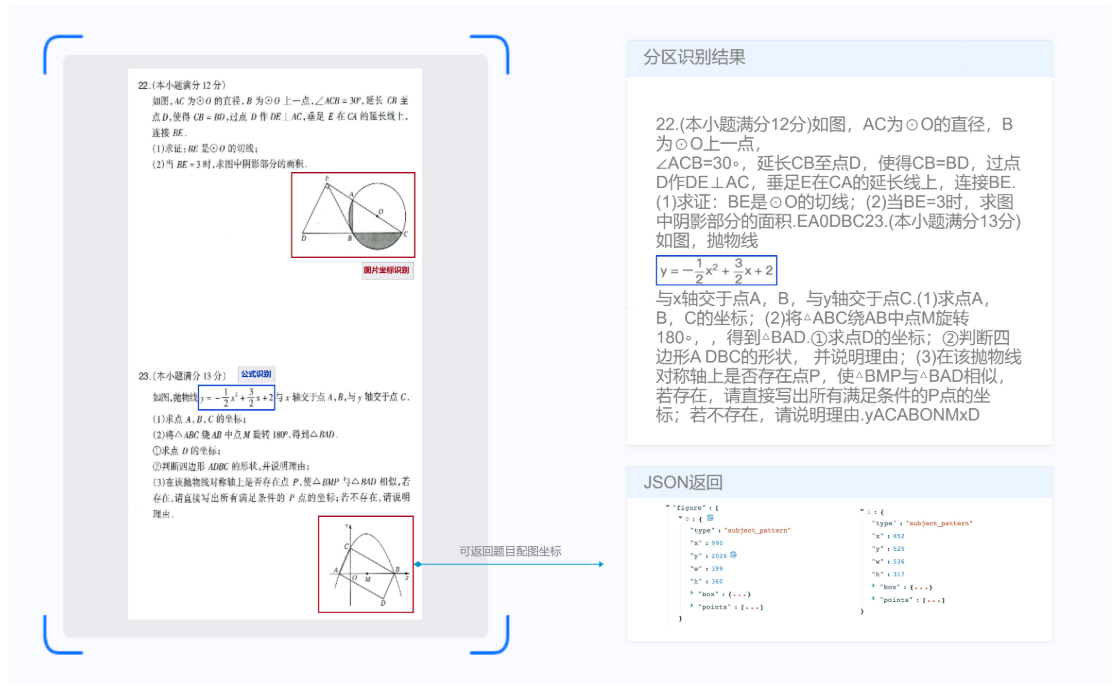
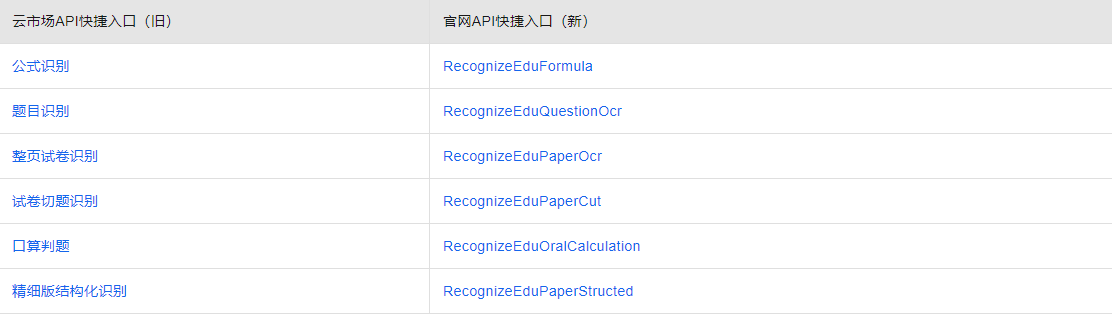
API快捷入口