Flink sql读取postgre josnb类型异常?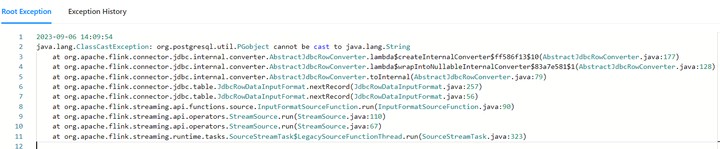
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink SQL在读取PostgreSQL中的JSONB类型时,会将其解析为Flink中的MAP类型或STRING类型,具体取决于你的表和列的定义。需要注意的是,PostgreSQL的JSONB类型不是Flink原生支持的类型,因此在读取时可能会遇到一些异常。
如果你遇到了异常,可以考虑以下几点来解决问题:
使用CAST转换类型:在Flink SQL中,你可以使用CAST函数将JSONB类型转换为Flink中支持的类型,比如将其转换为字符串类型,然后再进行处理。示例:SELECT CAST(json_column AS STRING) FROM table_name。
自定义函数:如果需要更复杂的解析和处理JSONB类型的数据,你可以使用自定义函数来处理。在Flink中,你可以通过自定义ScalarFunction或TableFunction来处理JSONB数据,将其解析为Flink支持的数据类型。具体可以参考Flink的官方文档中关于自定义函数的部分。
使用扩展库:Flink提供了许多扩展库,可以用于处理复杂的数据类型,比如json-schema-validator,可以用于校验和解析JSON数据。你可以尝试在你的Flink项目中引入这些库,以便更方便地处理JSONB类型数据。
综上所述,读取PostgreSQL中的JSONB类型时,你可以尝试使用CAST函数转换类型,自定义函数处理,或使用扩展库来解决异常。具体选择哪种方法取决于你的具体需求和业务逻辑。
如果Flink SQL连接器对jsonb类型不支持,可以先在PostgreSQL中将jsonb字段转换为文本类型(如text),然后再通过Flink SQL进行读取。
在 Flink SQL 中使用 JDBC 连接读取 PostgreSQL 的 JSONB 类型数据可能会遇到异常。这是因为 Flink 默认情况下不支持直接解析 PostgreSQL 的 JSONB 类型。
要解决这个问题,可以尝试以下两种方法:
方法一:使用 Flink 自定义函数(UDF)
创建一个自定义函数来处理 PostgreSQL 的 JSONB 类型数据。可以使用 flink-json 依赖库中提供的 JsonNode 类来处理 JSON 数据。
将 PostgreSQL 的 JSONB 数据类型列映射到 Flink 的 VARCHAR 类型列。
在 SQL 查询中使用自定义函数来解析 VARCHAR 类型的 JSON 字符串。
例如,假设有一个 my_table 表包含名为 json_data 的 JSONB 类型列,可以使用以下步骤来读取该表:
创建自定义函数:
java
import org.apache.flink.table.functions.ScalarFunction;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
public class ParseJson extends ScalarFunction {
private ObjectMapper objectMapper = new ObjectMapper();
public JsonNode eval(String json) {
try {
return objectMapper.readTree(json);
} catch (Exception e) {
// 处理异常情况
return null;
}
}
}
注册自定义函数:
java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.registerFunction("parseJson", new ParseJson());
使用自定义函数解析 JSON 字符串:
sql
SELECT parseJson(CAST(json_data AS VARCHAR)) FROM my_table;
方法二:使用 Flink JSON 表达式
如果只需要读取 JSONB 列中的某些字段,可以使用 Flink 的 JSON 表达式来提取数据。
例如,假设有一个 my_table 表包含名为 json_data 的 JSONB 类型列,可以使用以下步骤来读取该表:
sql
SELECT json_data->'field1' AS field1, json_data->'field2' AS field2 FROM my_table;
上述语句会提取 json_data 列中的 field1 和 field2 字段,并将其作为新的列返回。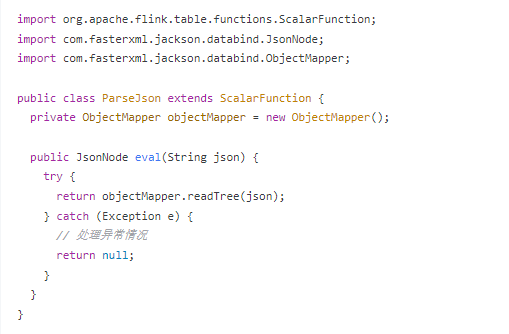
请注意,这两种方法都是通过将 JSONB 数据转换为字符串进行处理。因此,在处理大量数据时,请确保内存和性能足够支持。此外,这些解决方案都依赖于 Flink 版本和底层库的兼容性,请确保使用兼容的版本。
这段代码报错提示说无法将org.postgresql.util.PGObject转换成String。这是因为PostgreSQL返回的对象类型是PGObject,而Flask默认期望接收到的结果是一个字符串数组。
要修复这个问题,首先需要确定PostgreSQL查询的确返回了 PGObjects 。如果是这样的话,你需要更新 SQL 查询语句,使其能够直接返回 String 类型而不是 PGObject 类型。一种方法是在 PostgreSQL 查询后面加上 CAST() 函数,强制转换为 String 类型。
假设你的原始SQL查询是这样的:
SELECT column_name FROM table WHERE condition;
你应该把它改为:
SELECT cast(column_name as text) FROM table WHERE condition;
请替换 'column_name' 为你真正关心的那个列的名字。这将会使 Postgres 返回一个包含所需字段名称的文本列表。
另一种选择是从数据库端更改表结构,使得所选字段可以直接转化为 String 类型。但这种方法可能涉及到更复杂的变更管理过程,因此只有在必要的情况下才应采用。
一旦进行了适当的更改,记得测试新的 SQL 查询以验证其功能性和准确性。
根据报错信息来看,问题是出现在试图将PostgreSQL的pgobject类型转化为字符串(toString())时出错了。这是因为pgobject不是一个标准的Java类型,所以在将其转化为字符串时会抛出异常。
Apache Flink JDBC connector for PostgreSQL (https://github.com/apache/flink/tree/master/flink-jdbc-postgresql) 提供了一种映射PostgreSQL的pgobject类型的方法,但它似乎并未涵盖所有可能的情形。在某些情况下,尤其是当你尝试将pgobject类型与其他非PostgreSQL相关的SQL方言一起使用时,可能会引发此类异常。
为了解决这个问题,你需要找出为什么pgobject会被当作字符串来对待。一种可能的办法是检查你的查询语句,看是否存在不恰当的操作,例如尝试将pgobject列当作普通字符串来比较。另一个办法是更新你的Flink SQL查询,使之只适用于PostgreSQL的pgobject类型。
最后,如果你不确定如何修复这个问题,最好的做法是向Apache Flink项目报告这一问题,附带详细的步骤重现和必要的堆栈跟踪信息。他们的开发者们将会很乐于帮你调试和修正这个问题。
这个报错信息表示在Flink SQL中读取PostgreSQL的josnb类型时出现了异常。具体来说,org.codehaus.janino.CompilerFactory 无法转换为 org.codehaus.commons.compiler.ICompilerFactory。
要解决这个问题,你可以尝试以下方法:
确保你的项目中包含了正确版本的依赖库。检查你的项目中是否包含了正确的Flink和PostgreSQL相关依赖库。如果缺少某个依赖库,请添加相应的依赖。
检查你的代码中是否存在类型转换错误。根据报错信息,org.codehaus.janino.CompilerFactory 无法转换为 org.codehaus.commons.compiler.ICompilerFactory。请检查你的代码中是否存在类型转换错误,例如将一个对象强制转换为不兼容的类型。
如果问题仍然存在,尝试升级或降级相关的依赖库版本。有时候,不同版本的依赖库之间可能存在兼容性问题。尝试升级或降级依赖库版本,看看是否能解决问题。
问题出在 Flink SQL 读取 PostgreSQL 数据时,类型转换异常。具体来说,Flink 尝试将一个 Java 对象(crt.postgresgl.util.pgobect)转换为字符串(java.lang.String),导致了 ClassCastException。
要解决这个问题,您需要检查 Flink 应用程序中的数据类型和映射配置。这里有一些建议:
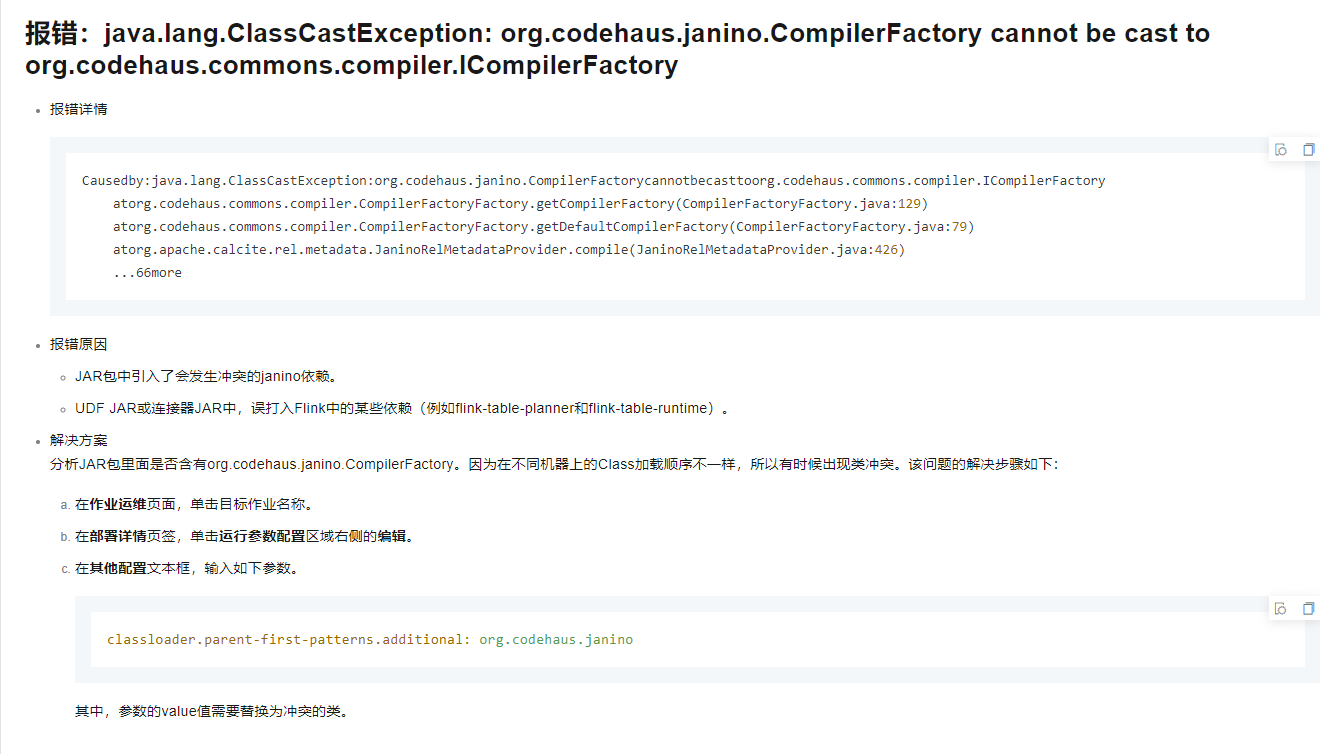
报错:java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory
报错详情
Causedby:java.lang.ClassCastException:org.codehaus.janino.CompilerFactorycannotbecasttoorg.codehaus.commons.compiler.ICompilerFactory
atorg.codehaus.commons.compiler.CompilerFactoryFactory.getCompilerFactory(CompilerFactoryFactory.java:129)
atorg.codehaus.commons.compiler.CompilerFactoryFactory.getDefaultCompilerFactory(CompilerFactoryFactory.java:79)
atorg.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:426)
...66more
报错原因
JAR包中引入了会发生冲突的janino依赖。
UDF JAR或连接器JAR中,误打入Flink中的某些依赖(例如flink-table-planner和flink-table-runtime)。
解决方案
分析JAR包里面是否含有org.codehaus.janino.CompilerFactory。因为在不同机器上的Class加载顺序不一样,所以有时候出现类冲突。该问题的解决步骤如下:
在作业运维页面,单击目标作业名称。
在部署详情页签,单击运行参数配置区域右侧的编辑。
在其他配置文本框,输入如下参数。
classloader.parent-first-patterns.additional: org.codehaus.janino
其中,参数的value值需要替换为冲突的类。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。