文字识别OCR的PDF格式是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
PDF格式是一种用于存储和传输电子文档的文件格式。对于文字识别OCR(Optical Character Recognition),与PDF文件相关的常见格式是可搜索的PDF(Searchable PDF)。
在可搜索的PDF中,除了原始的图像内容外,还包括了通过OCR技术提取出来的文本信息。这样可以实现在PDF文件中进行文本搜索、复制和编辑等操作。
当应用OCR技术对PDF进行文字识别时,会将PDF文件转换为可搜索的PDF格式,以便更好地处理和利用其中的文本信息。通过识别PDF中的图像元素,并将其转换为可编辑的文本,OCR可以使得PDF文件具备更高的可读性和可搜索性。
OCR(Optical Character Recognition)技术用于将图像中的文字转换为可编辑的文本。OCR可以应用于多种图像格式,包括PDF。
PDF(Portable Document Format)是一种通用的电子文档格式,它可以包含文本、图像和其他类型的内容。与其他图像格式(如JPEG、PNG等)相比,PDF是一种更复杂的格式,可以保留文档的布局、格式和元数据。
当涉及到OCR的PDF时,通常指的是对PDF文档中的文字进行识别,以提取文本内容并使其可编辑和搜索。OCR技术可以解析PDF中的页面,并将页面上的文字转换为机器可读的文本。这样,你可以在PDF中选择、复制和修改文字,而不仅仅是查看图像。
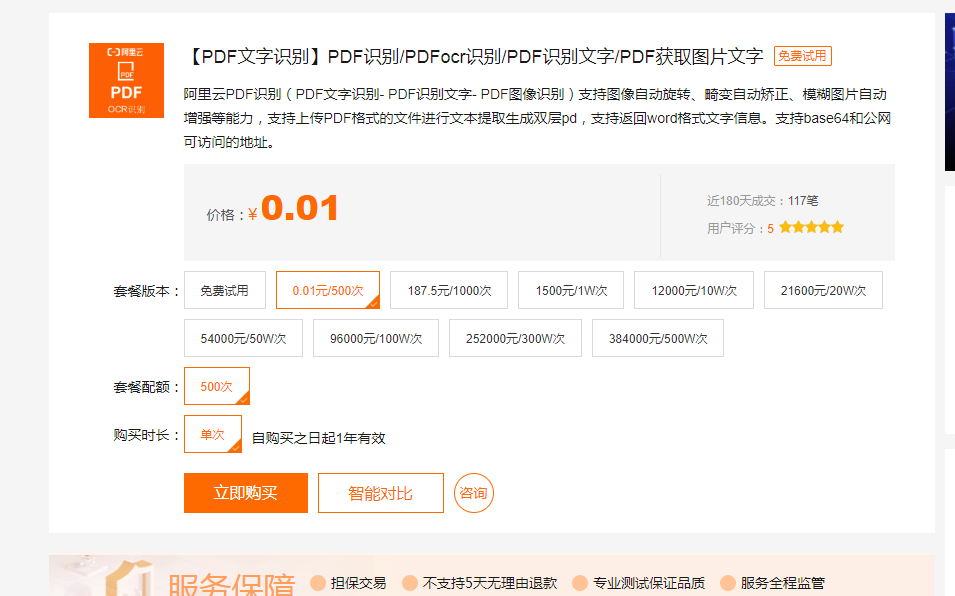
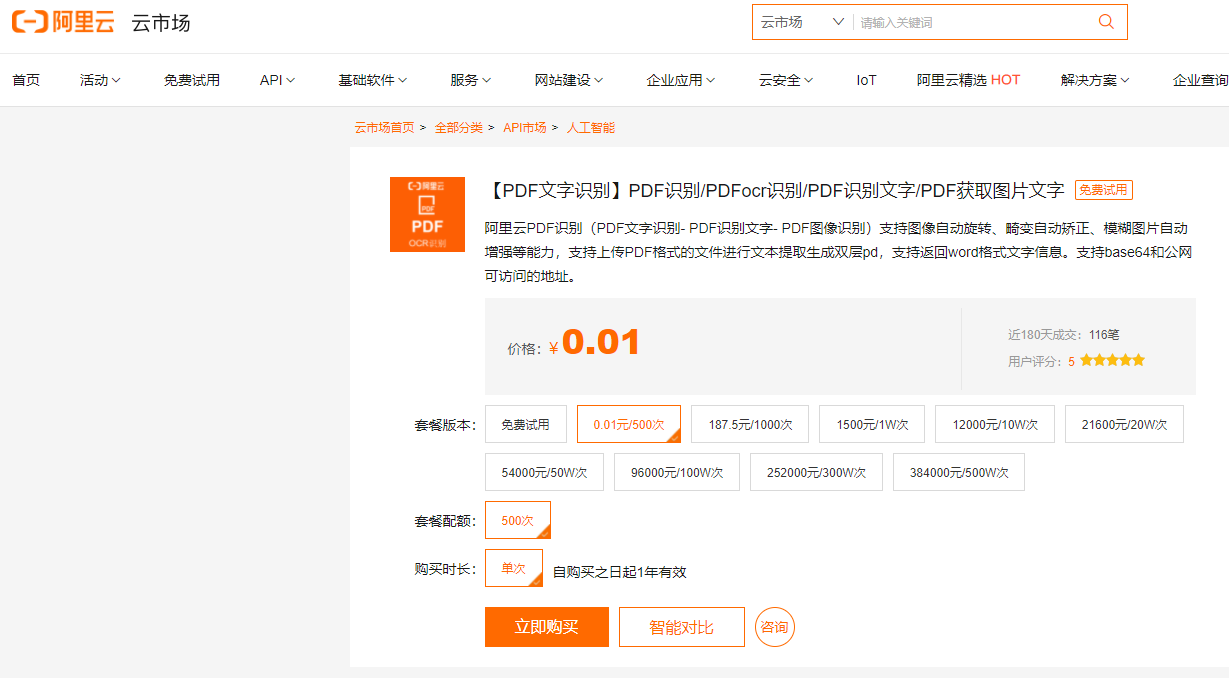
阿里云PDF识别(PDF文字识别- PDF识别文字- PDF图像识别)支持图像自动旋转
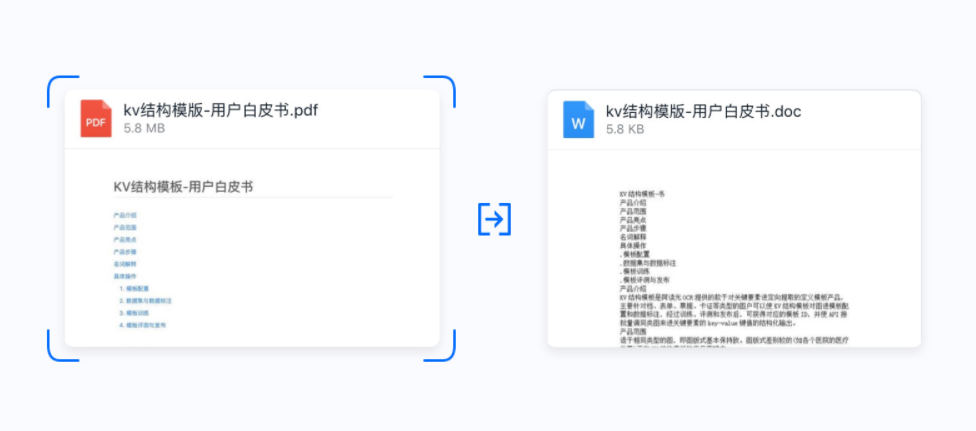
适应模糊、光照不均、透视畸变、任意背景等实际应用中存在的各种情况,并可实现自动裁边、修正倾斜等。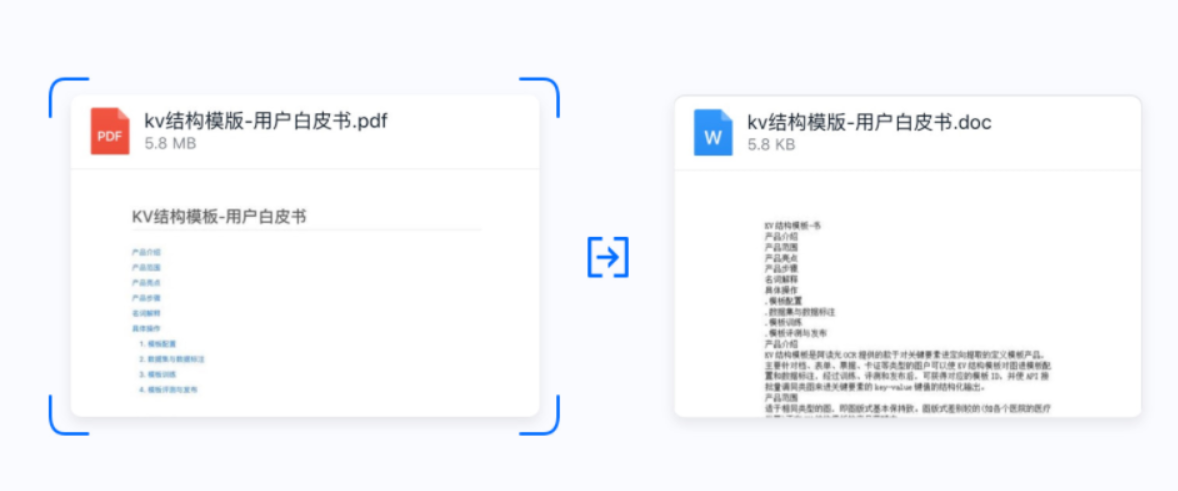
阿里云PDF识别(PDF文字识别- PDF识别文字- PDF图像识别)支持图像自动旋转、畸变自动矫正、模糊图片自动增强等能力,支持上传PDF格式的文件进行文本提取生成双层pd,支持返回word格式文字信息。支持base64和公网可访问的地址。
1)、导入PDF格式的文件进行文本提取生成双层pdf,并可支持将识别结果转成word格式
2)、适应模糊、光照不均、透视畸变、任意背景等实际应用中存在的各种情况,并可实现自动裁边、修正倾斜等。
3)、PDF识别整体识别准确率高。
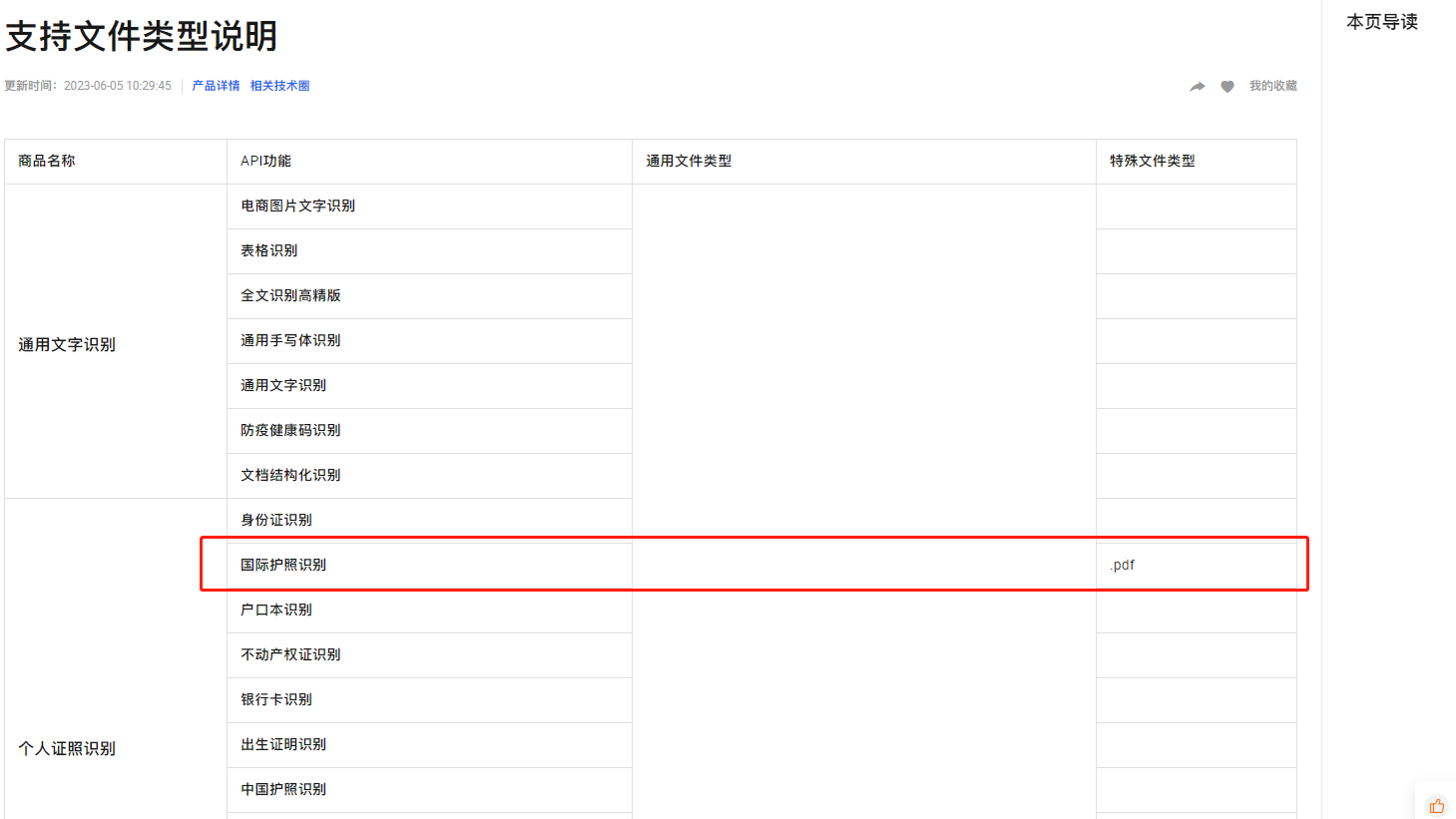
楼主你好,阿里云文字识别OCR支持的PDF格式是可搜索的PDF(Searchable PDF)和可编辑的PDF(Editable PDF)。
其中,可搜索的PDF是通过OCR技术将PDF中的图片转换为可搜索的文本而生成的,可编辑的PDF则是在可搜索的PDF的基础上进行了进一步的处理,使其能够进行文本编辑。具体的接口:
具体链接如下所示:
https://market.aliyun.com/products/57124001/cmapi027758.html
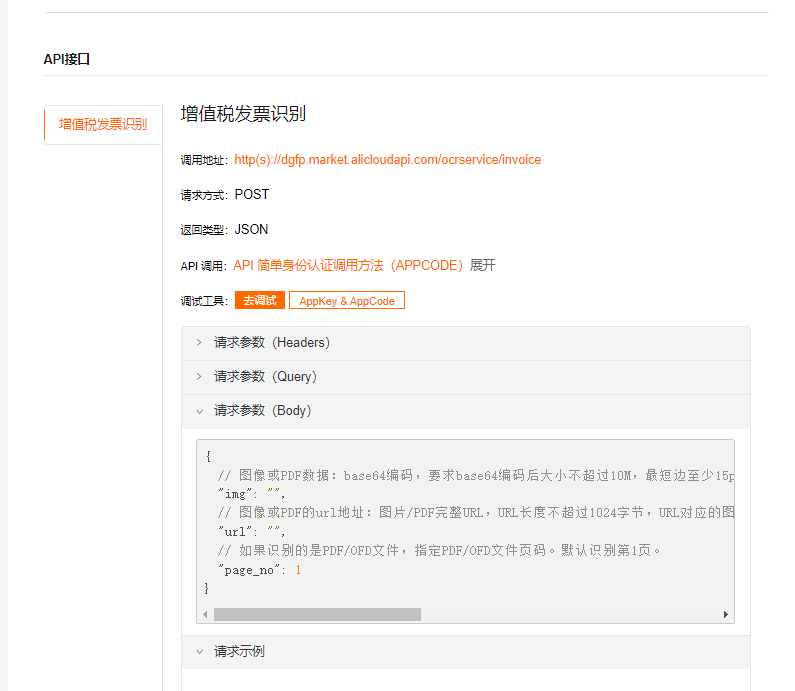
文字识别(ocr)类目下的PDF识别RecognizePdf的语法及示例。
PDF识别能力可以对PDF上的文字进行结构化识别。
输入限制
文件格式:PDF。
文件大小:不超过10 MB。
文档篇幅:PDF不超过5页。
URL地址中不能包含中文字符。
阿里云视觉AI文字识别类目下的PDF识别能力推荐使用SDK调用,支持多种编程语言,调用时请选择AI类目为文字识别(ocr)的SDK包,文件参数通过SDK调用可支持本地文件及任意URL,具体可参见SDK总览。

特色优势
精准识别:智能算法升级,精准识别文件内容,保留原始排版。
多语种识别:可识别中、英、中英混合等多语种内容。
读光PDF识别可支持导入PDF格式的文件进行文本提取生成双层pdf,并可支持将识别结果转成word格式。该接口是一个异步调用接口。