
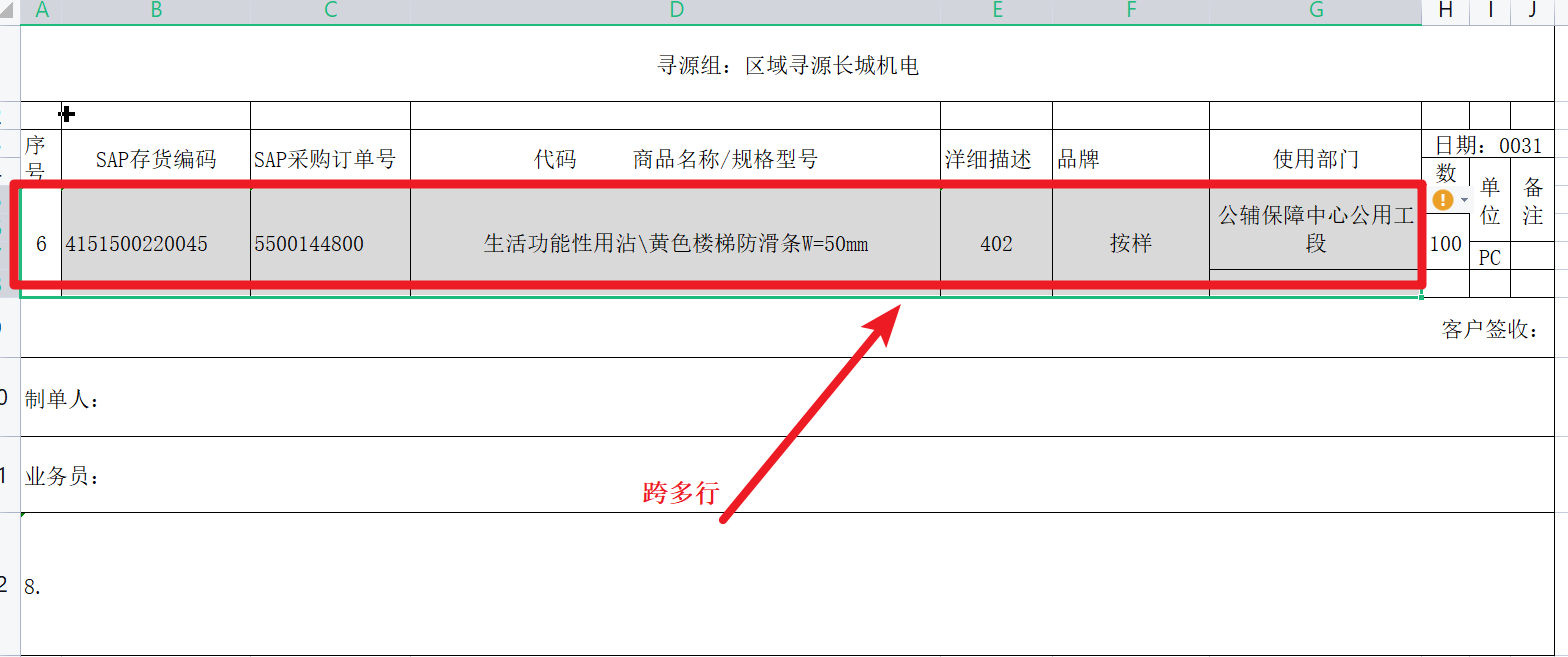
文字识别OCR 图片转Excel的方式,这种有边线的情况下,转移出来的Excel 出现跨行了,该如何解决?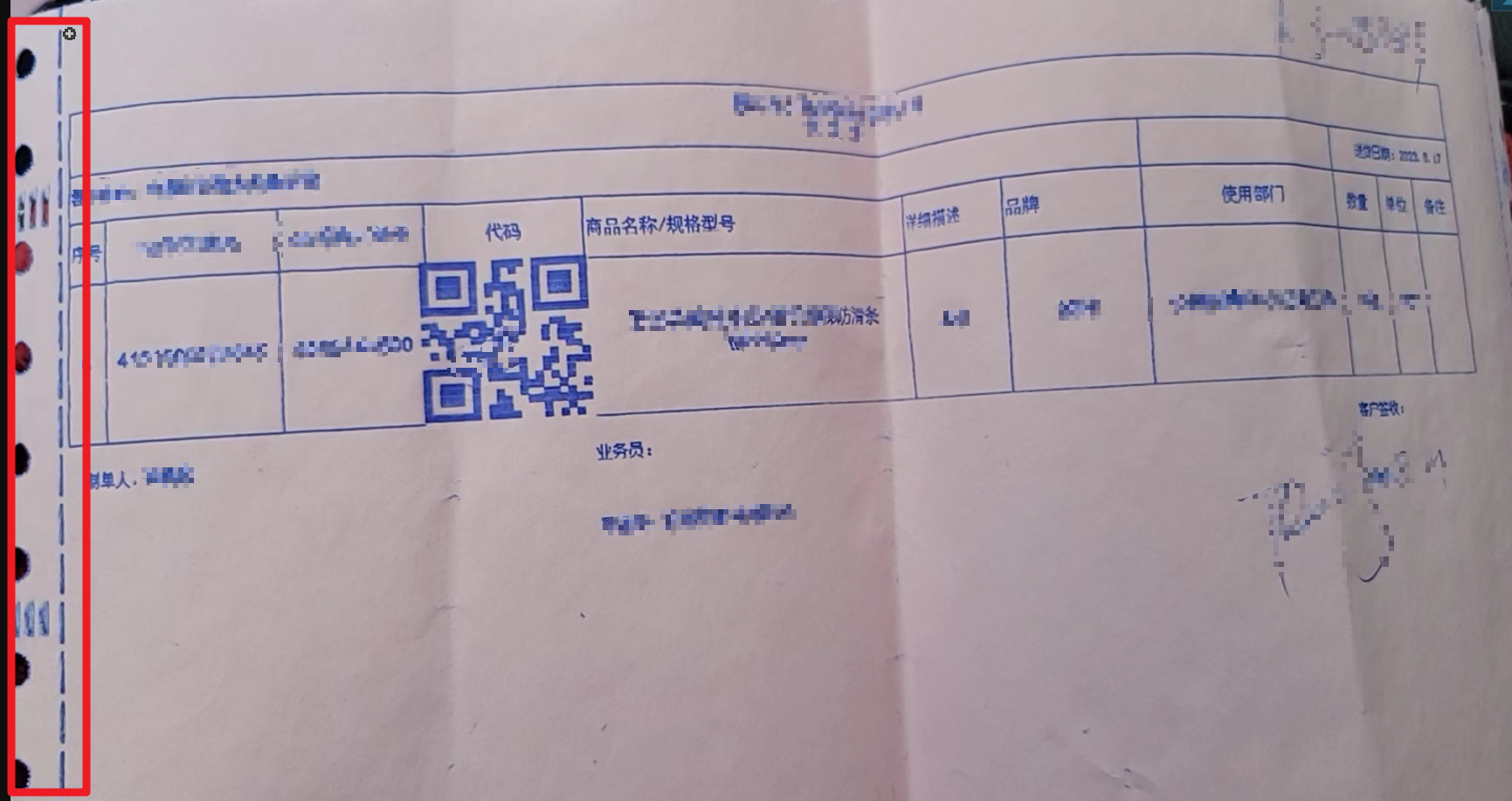
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
自定义表格模板是针对固定版式的单页有框线表格表单数据提供的一款定制化产品。用户仅需通过一张模板数据的可视化拖拉拽配置参照字段、识别字段或表头&待识别的列表区域,字段属性等,无需进行数据标注和模型训练,即可实现相同版式数据的自定义结构化识别抽取。经过配置调优的模板识别准确率可达85%以上。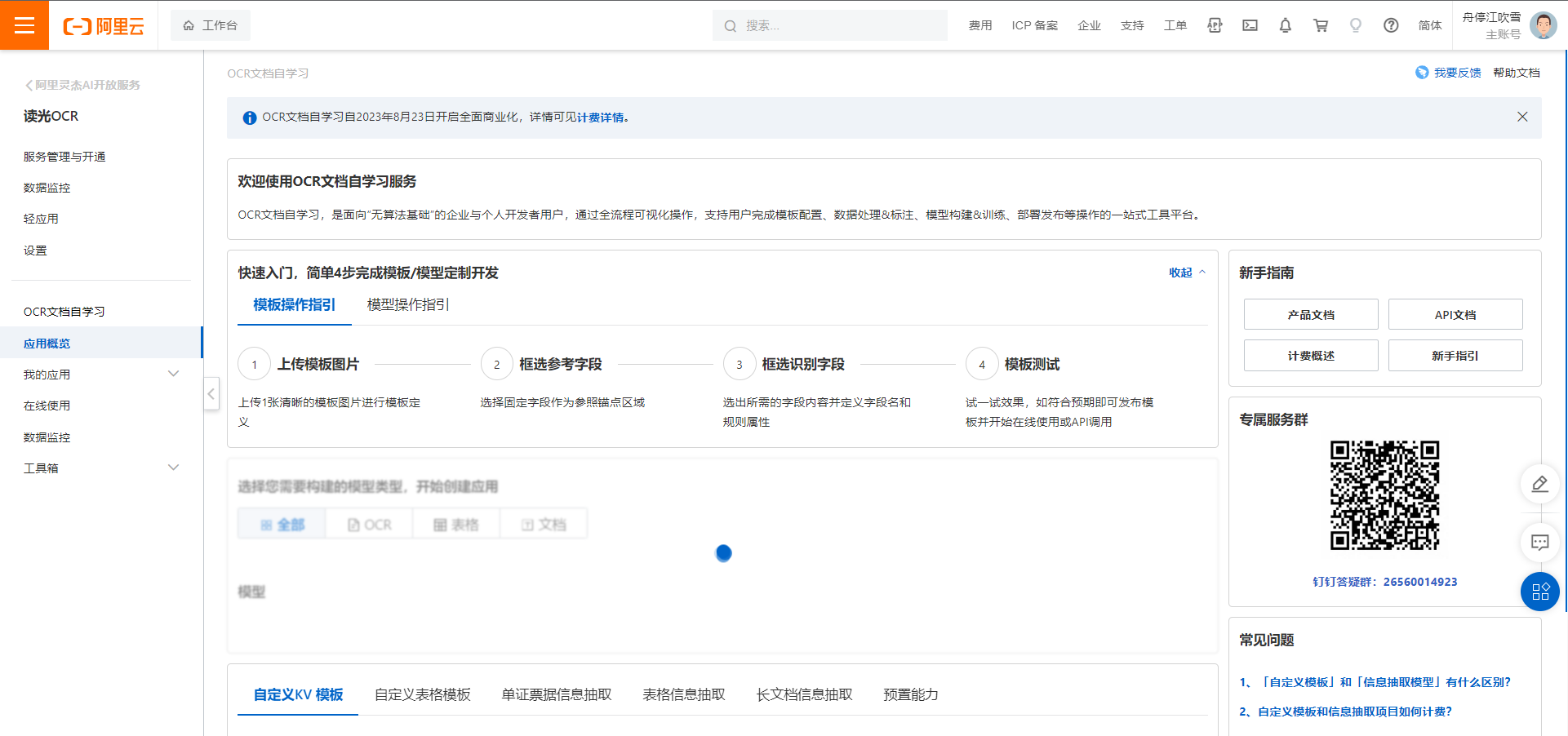
同时工具箱中还提供分类器管理工具与字段类型管理工具,支持用户通过同一接口完成不同版式数据的自动分类路由与高精度识别。
步骤一 : 上传模板图片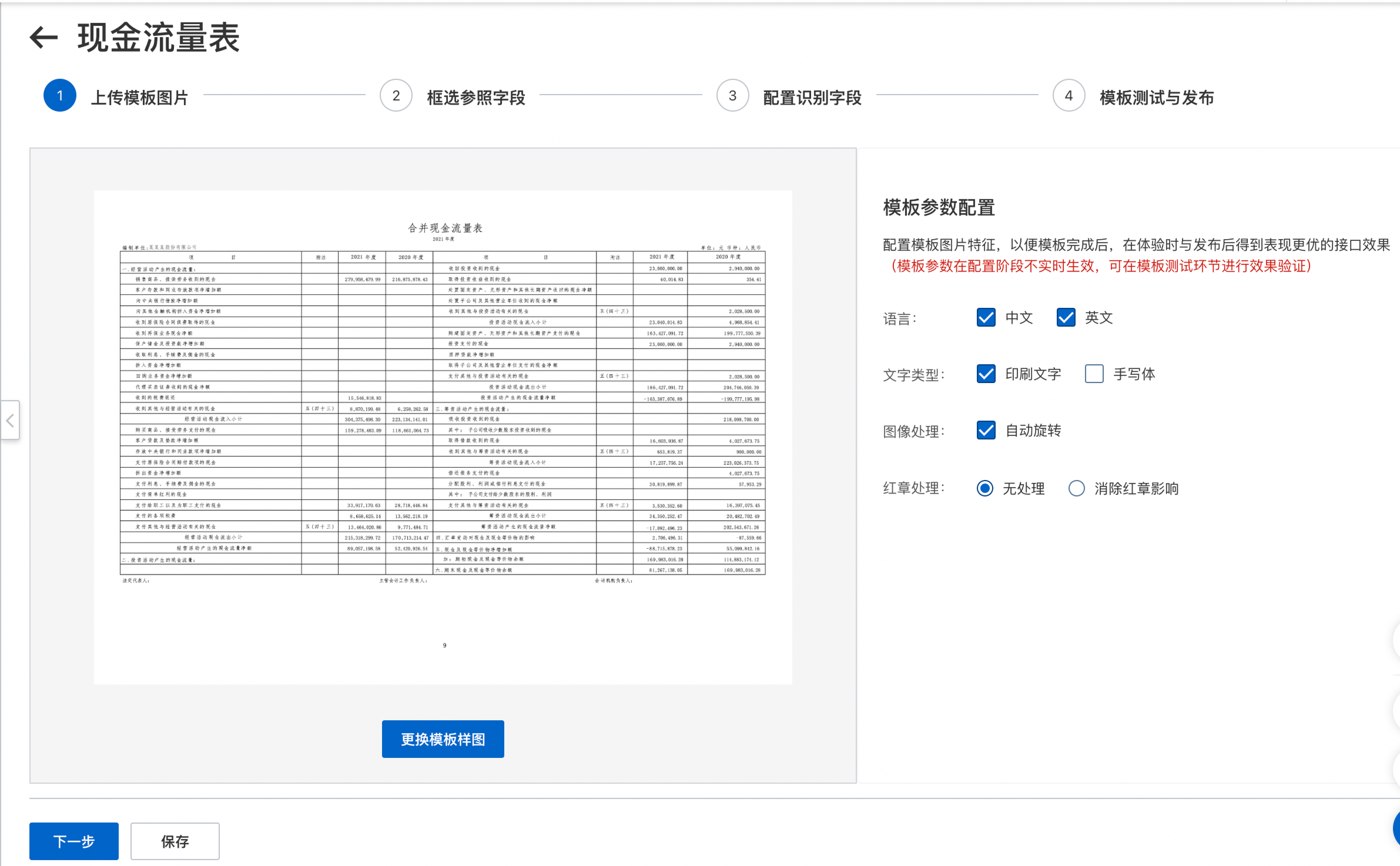
步骤二 : 框选参照字段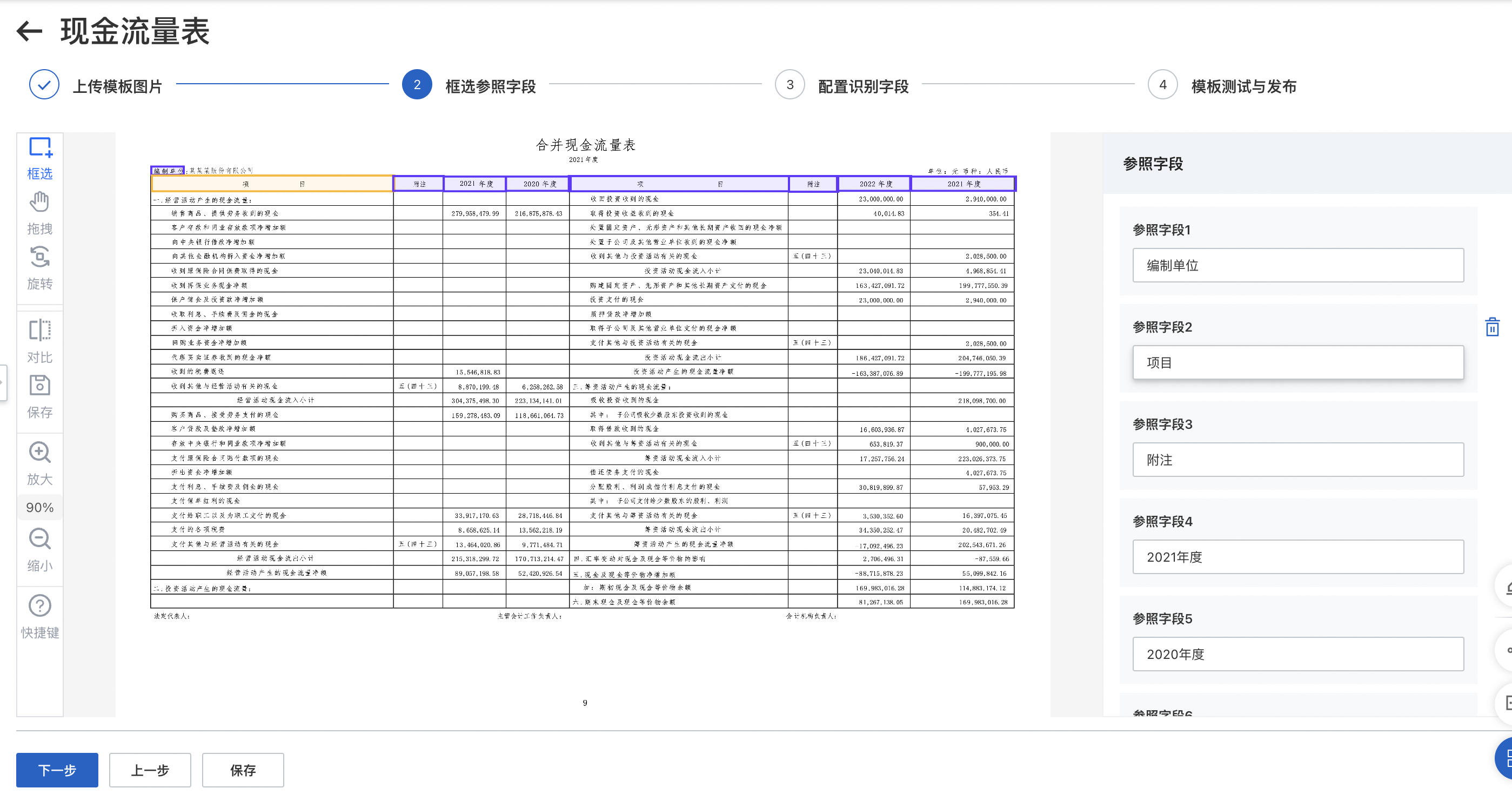
步骤三 : 配置识别字段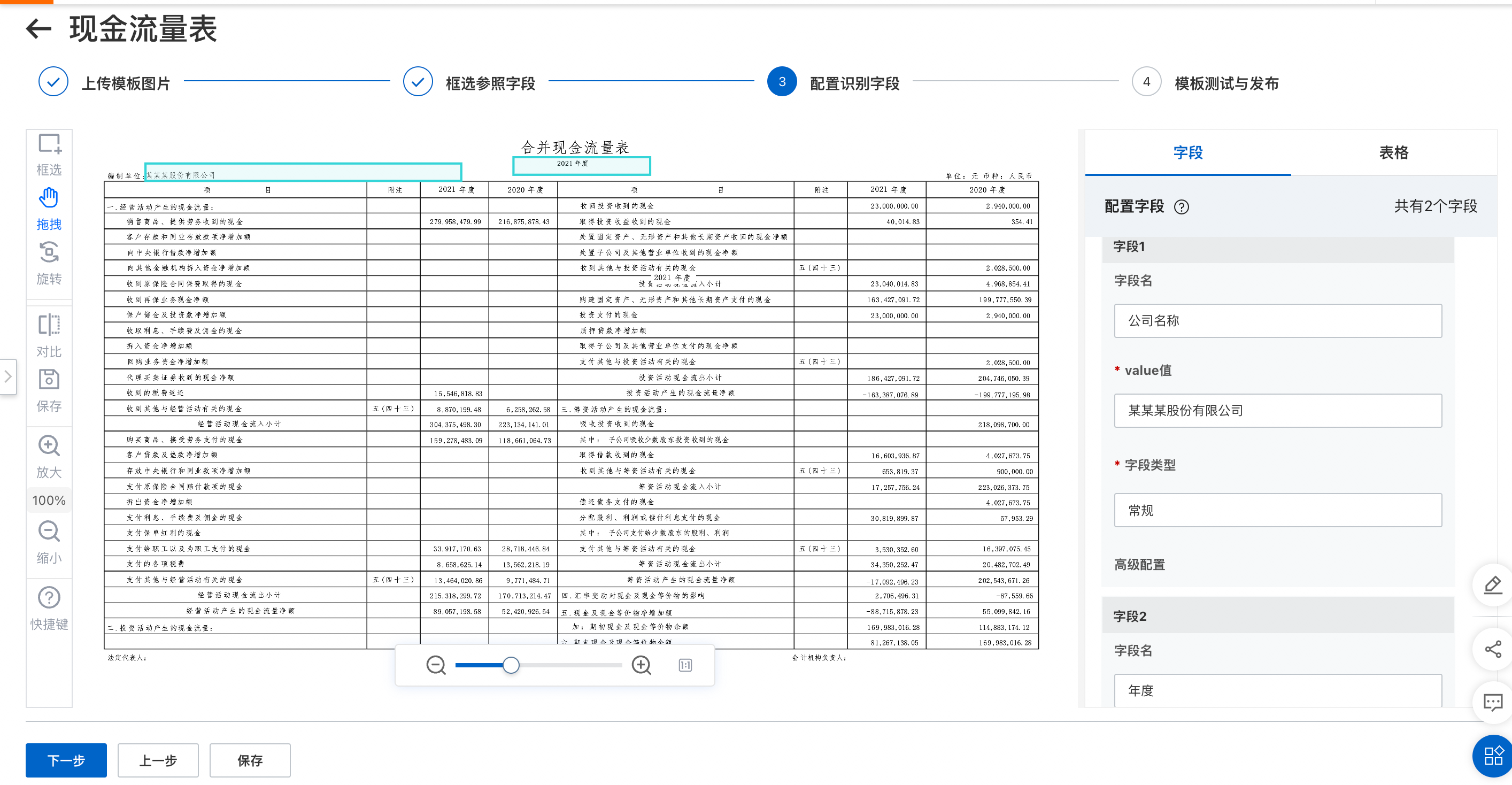
步骤四 : 模板测试与发布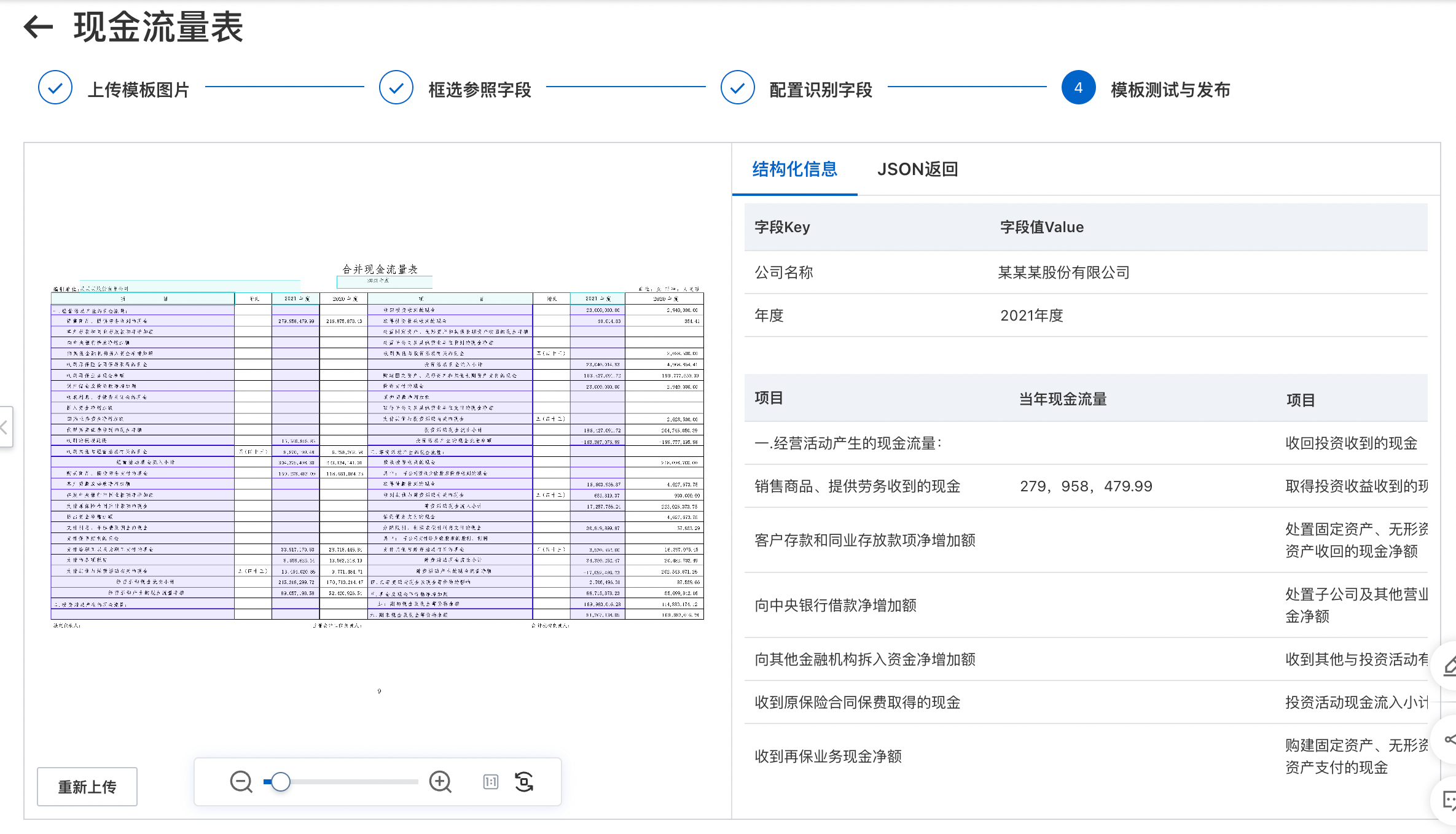
楼主你好,出现跨行的情况多数是由于OCR识别的时候没有正确地识别表格的边界,或者是表格中数字或文字的行高不同导致的。可以尝试以下几种方法解决:
1.重新调整原始图片中表格的边界并重新进行OCR识别,这样可能会减少跨行的情况。
2.手动编辑OCR转换后的Excel文件来纠正跨行的问题,可以通过拆分单元格、调整行高等方式来解决。
3.使用第三方工具进行Excel文件格式转换,例如使用Python的pandas库或者OpenPyXL库等,可以将OCR转换后的Excel文件进行处理,使其更加符合要求。
当使用阿里云文字识别OCR将图片转换为Excel时,如果图片中存在边框,并且在转换为Excel后,出现了跨行的情况,可以采取以下几种方法来解决:
图片预处理:在将图片传给OCR进行识别之前,对图片进行预处理,通过裁剪、调整大小或旋转等操作,使表格边框对齐和显示正确。这样可以提高识别的准确性,并减少出现跨行的问题。
OCR结果后处理:在将OCR识别结果转存为Excel文件之前,对OCR输出的文本进行处理。可以根据表格的行高和列宽信息,对跨行的结果进行合并,使其与原始图片中的表格结构保持一致。
使用其他工具或库:如果OCR结果转存为Excel的方法无法满足需求,可以考虑使用其他专业的处理表格数据的工具或库,如Python中的pandas库或Java中的Apache POI库。这些工具提供更多的表格处理和合并单元格的功能,可以更好地管理和调整识别结果。
表格识别和转换是一个复杂的任务,可能会遇到各种不确定因素。在处理跨行和表格结构问题时,需要根据具体的场景和需求进行一些自定义化的处理。


