
您是否曾遇到这样的困境:收到一份重要的PDF合同或报告,使用传统OCR工具识别后,得到的却是标题正文不分、表格错乱、格式全无的杂乱文本,仍需投入大量时间手动整理?
请看下方对比,这直观揭示了文档解析的现状与未来:
传统OCR输出:
2024年第一季度财务报告核心业绩指标金额(万元)同比增长营业收入15,280+12.5%净利润2,150+8.3%详见下文分析...
所有内容连成一段,结构完全丢失
数眼智能OCR解析后(Markdown格式):
2024年第一季度财务报告
一、核心业绩
| 指标 | 金额(万元) | 同比增长 |
|---|---|---|
| 营业收入 | 15,280 | +12.5% |
| 净利润 | 2,150 | +8.3% |
为此,数眼智能正式推出新一代OCR文档解析API。我们突破单纯文字识别局限,融合多模态识别与深度学习技术,在实现高精度文字提取的同时,深度解析文档的版面结构与语义逻辑。核心在于直接输出保留完整格式与层次结构的Markdown文本,使标题、表格、列表等元素转化为标准化、机器可读的数据格式。
这意味着,学术文献可一键转为可搜索的知识库,发票合同能自动提取数据对接业务系统,复杂报告可即时变为可协作的在线文档。数眼智能OCR API正将沉睡的纸质信息转化为驱动业务增长的智能资产。
技术解读
数眼智能OCR的强大效能,源于一套创新的“两步走”解析策略:
第一步:整体规划,快速定位。系统首先对文档版面进行快速扫描与分析,精准框选出文本、表格、公式等所有关键元素,并智能规划出符合人类阅读逻辑的正确顺序。
第二步:并行精读,深度识别。随后,系统将这些已排序的内容区块,以并行的方式送入专门的高精度识别模块,集中解析每一处的具体文字与语义内容。
最后,通过轻量的后处理流程,系统将两阶段的结果高效融合,直接输出结构化的Markdown及JSON数据。这种“先布局、后识别”的协同流程,在确保解析结果高度准确与稳定的同时,实现了处理速度与资源效率的大幅提升。
如何调用API
只需简单几步,即可在数眼智能官网接入OCR文档解析API,或直接在线使用,将技术能力快速集成至您的业务流中。
第一步:登录官网,获取密钥
访问数眼智能官网,注册并登录后,进入控制台。在「API密钥」页面,就能创建并获取专属的 API Key,这是调用所有服务的通行证。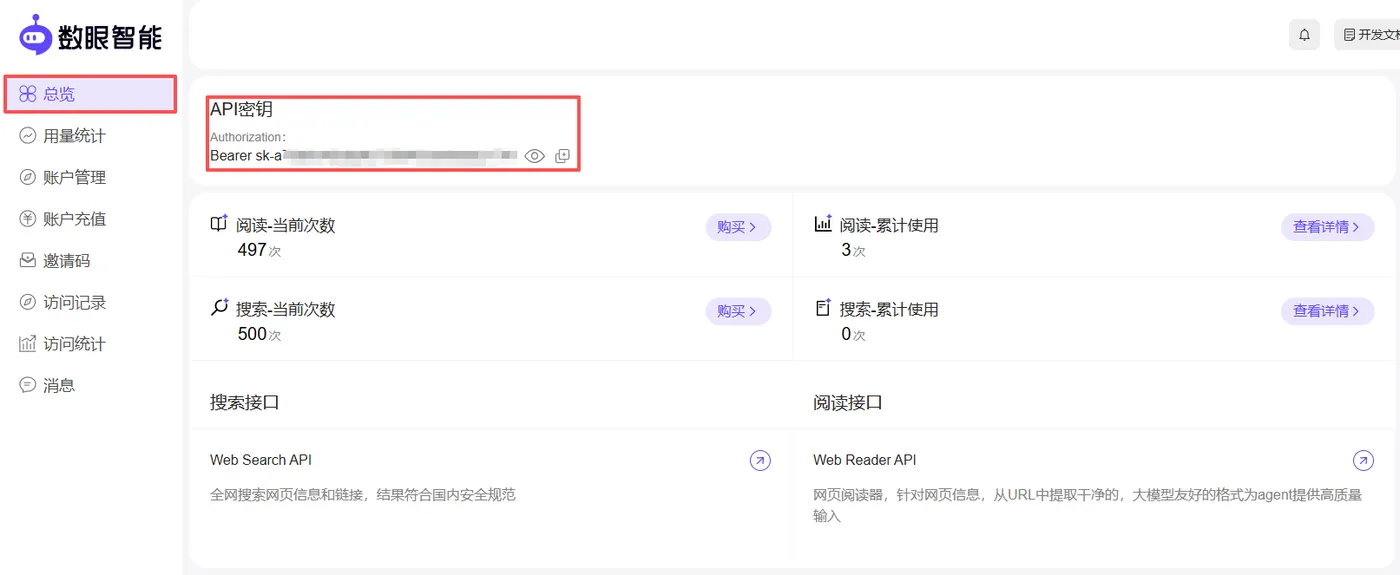
第二步:查阅文档,集成调试
在官网文档中心找到「文档OCR解析API」部分,这里提供了完整的接口说明、请求参数和返回示例,直接在线使用或根据自己的开发习惯,使用 Postman、cURL 或任何编程语言的HTTP库来调用我们的OCR API。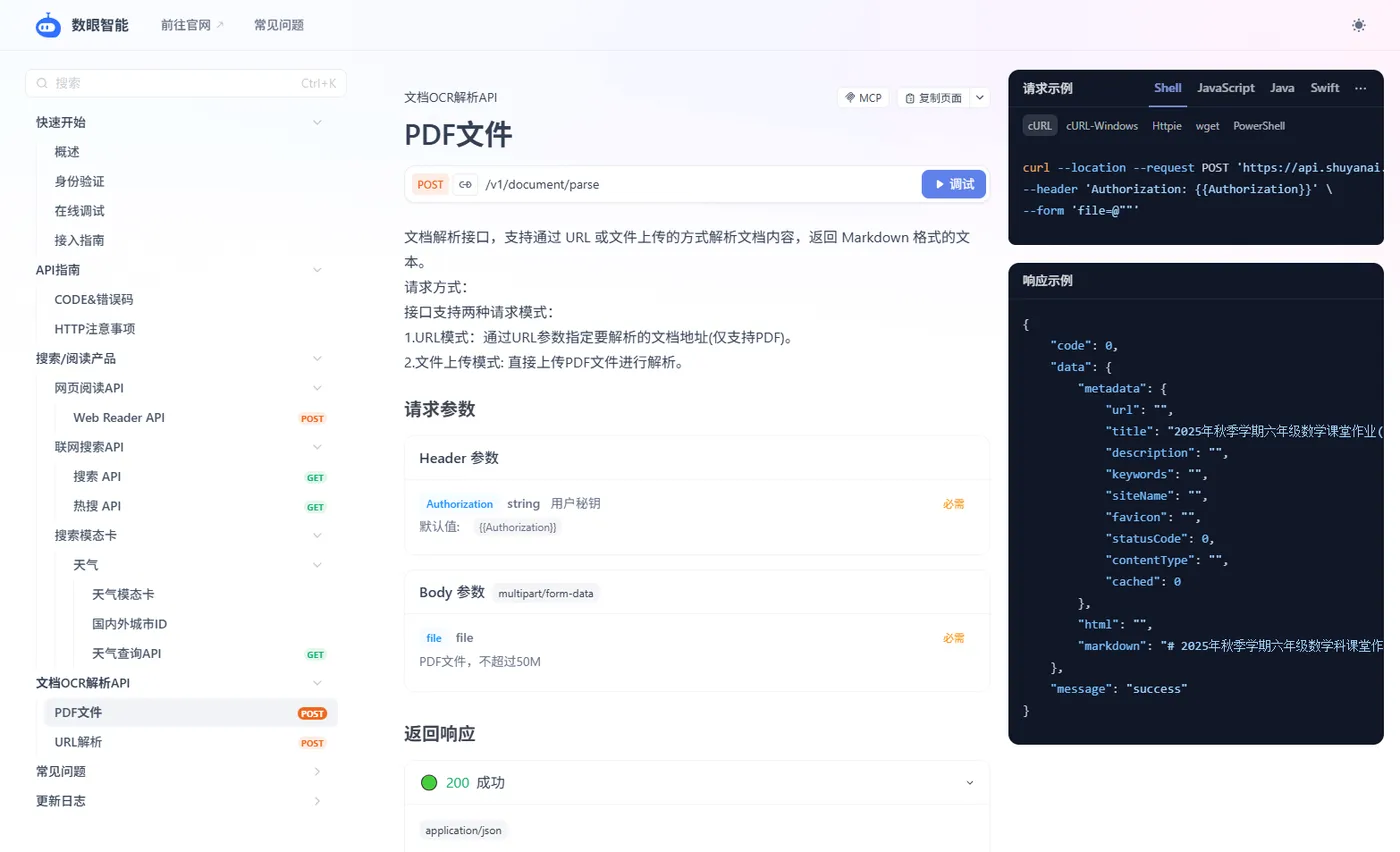
第三步:解析结果,投入应用
API将以JSON格式返回响应。解析后的结构化文本,将清晰地封装在 markdown 字段中,便可直接提取和使用。
整个调用流程通常能在10秒内完成,对于多数标准文档,响应速度相比市场上的一些大型模型更为高效。
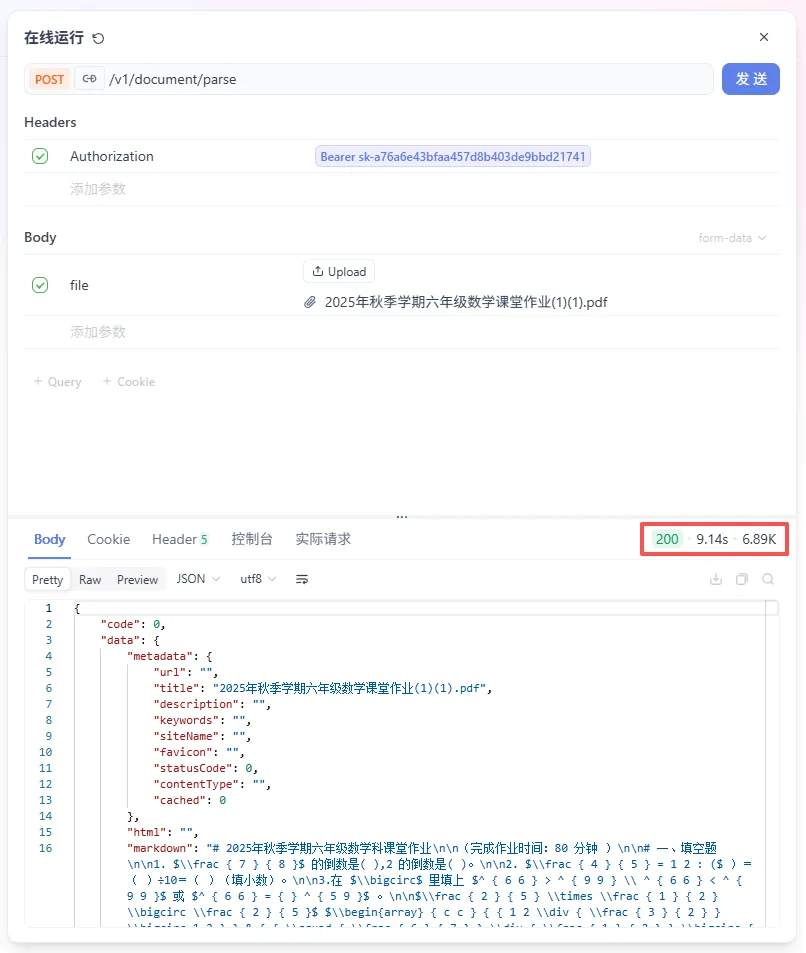
我们对比一下PDF源文件和给到数眼智能OCR之后出来的Markdown文件,正确率100%。

通过以上三步,即可完成从文档上传到获取结构化数据的全过程。接下来,您的业务系统便可直接消费这些高质量的Markdown数据,驱动自动化流程与深度分析。
使用场景
通过以上简单的步骤,数眼智能OCR API便能深入多个核心业务场景,解决长期存在的信息处理顽疾:
大模型知识库构建(RAG)
面向大模型RAG(检索增强生成)应用,将PDF、Word等非结构化文档精准清洗为Markdown或JSON格式。通过高保真保留标题层级与段落逻辑,为向量数据库提供高质量的Clean Data,显著提升大模型问答的准确率与引用溯源能力。
智能学术文献解析
针对论文、教材、试卷等包含大量数学公式与特殊符号的文档,实现像素级精准还原。支持将复杂的行内公式、多行公式直接转译为LaTeX/MathML代码,便于科研人员、师生进行二次编辑、翻译或构建数字化题库,极大缩短录入时间。
金融研报数据提取
自动解析招股书、财报年报中的复杂财务表格。智能识别跨页表格、无线框表及合并单元格结构,将表格数据无损提取并导出为Excel/CSV格式。助力金融分析师快速结构化关键财务指标,实现自动化数据录入与量化分析。
企业文档数字化归档
助力政府与企业实现海量纸质档案的数字化转型。支持合同、标书、发票等多种版式文档的批量OCR识别与并发处理。将扫描件与图片转化为可全文检索的双层PDF或纯文本,打通企业内部知识孤岛,提升文档流转与管理效率。
结语
数眼智能OCR文档解析API,凭借创新的“两阶段协同”架构与10秒内高效响应的核心优势,正成为企业处理非结构化信息的关键引擎。它通过精准输出结构化的Markdown与JSON数据,直接赋能四大核心场景:为大模型(RAG) 提供高质量数据源,为学术研究精准还原公式排版,为金融分析提取复杂表格数据,为档案数字化实现高效批量处理。
这标志着文档从静态存储走向了智能应用的起点。
