
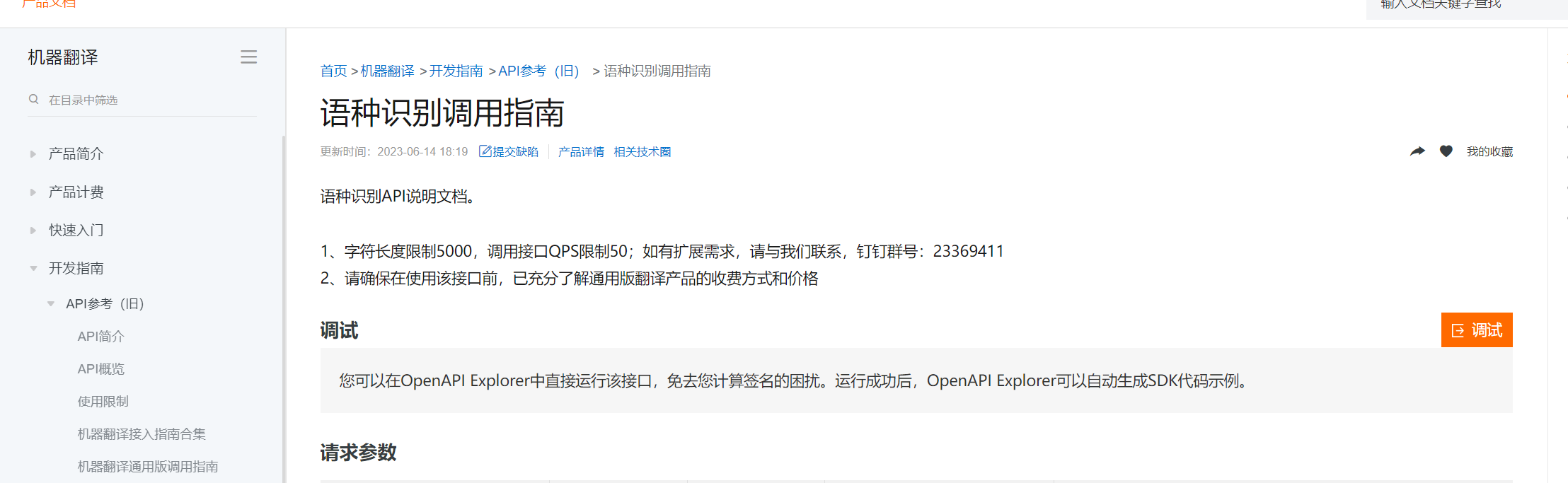
机器翻译语种识别,这里支持传入语音文件吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
目前大部分机器翻译系统均不支持传入语音文件进行翻译。
如果确实需要机器翻译输入来自语音,建议:
使用专业的语音识别工具将语音先转化为文本
然后将得到的文本输入到文本机器翻译系统中进行翻译。
可供参考的语音识别工具有:Baidu API、iFlytek API等。
这个API目前只支持文字输入,暂时不支持语音文件传入。可以尝试把语音转换成文字再传入。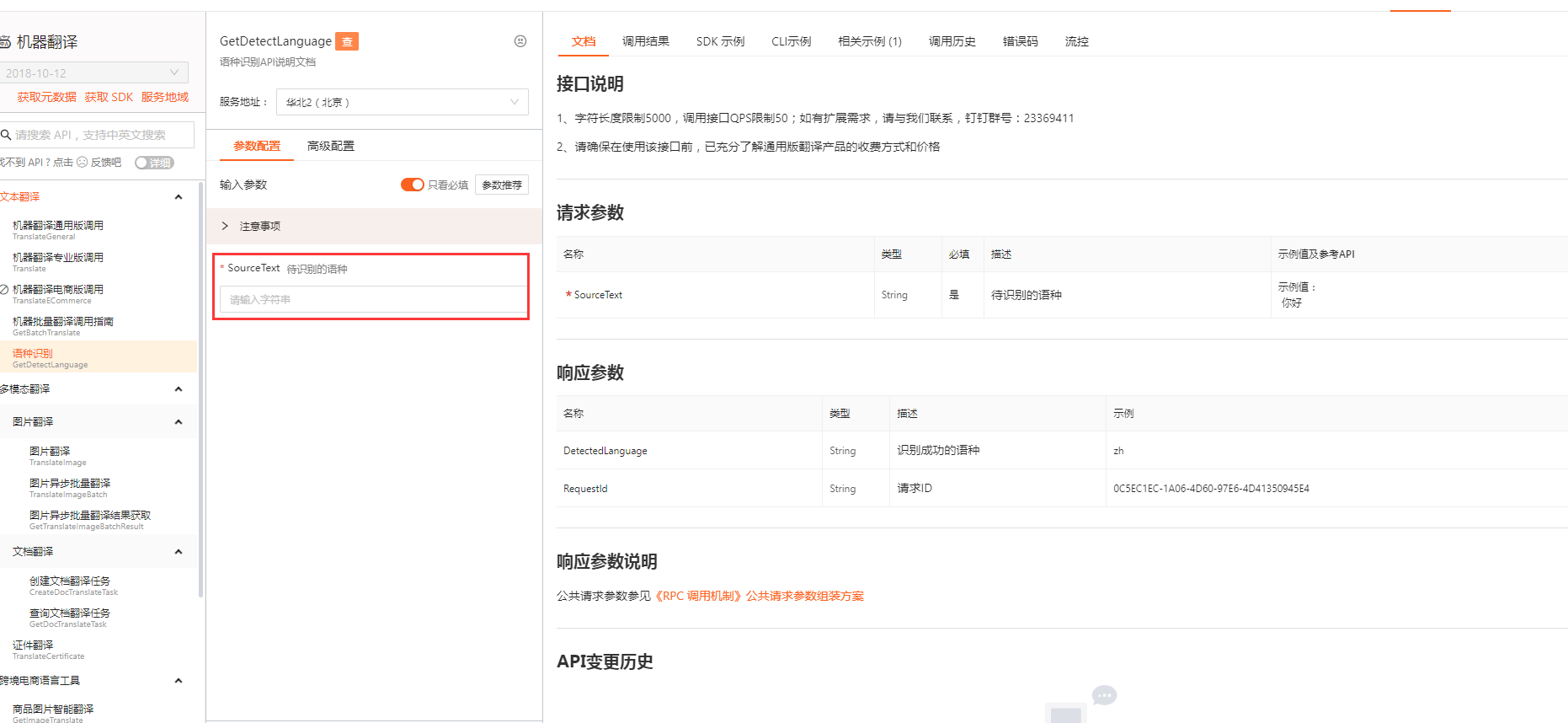
更多需求请联系,钉钉群号:23369411
对于机器翻译语种识别,一些语音转文本服务可以用于识别语种。其中,AWS Transcribe 和 Google Cloud Speech-to-Text 是两个常用的服务,它们可以将语音转换为文本,并提供语种识别的功能。
您可以使用这些服务将语音文件转换为文本,并根据返回的结果判断语种。下面是一个示例使用 Python 和 AWS Transcribe 的代码:
import boto3
def detect_language(audio_file):
transcribe = boto3.client('transcribe')
response = transcribe.start_transcription_job(
TranscriptionJobName='language-detection',
Media={'MediaFileUri': 's3://your-bucket/your-audio-file.mp3'},
MediaFormat='mp3',
LanguageOptions=['en-US', 'es-US', 'fr-FR'] # 可选的语种列表
)
# 等待转录任务完成
while True:
status = transcribe.get_transcription_job(TranscriptionJobName='language-detection')
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
# 获取转录结果
response = transcribe.get_transcription_job(TranscriptionJobName='language-detection')
transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri']
transcript = boto3.client('s3').get_object(Bucket='your-bucket', Key=transcript_uri)
text = transcript['Body'].read().decode('utf-8')
# 提取识别到的语种
language = response['TranscriptionJob']['LanguageCode']
return language
上述代码使用 AWS 的 Transcribe 服务将音频文件进行转录,并通过返回的结果获取识别到的语种。
Google Cloud Speech-to-Text 也提供类似的功能,您可以参考 Google Cloud 文档进行开发。
请注意,这些服务的准确性可能会受到多种因素的影响,如音频质量、说话人口音等。因此,结果可能不是绝对准确,可能需要进行进一步的验证和处理。
希望这对您有帮助。如果有任何其他问题,请随时提问。

